对于分布式数据库和分布式环境,高并发和高性能压力的情况下,出现线程创建失败等等问题也是十分常见的,这时候就十分考虑数据库管理员的经验,需要能快速的定位到问题和瓶颈所在,快速解决。本文作为最佳实践,将与大家分享如何在高并发情况下定位问题,排除问题,解决瓶颈。
SequoiaDB在集群环境中的 -10 错误码,在认真查阅节点的 diaglog 日志后,发现是操作系统 create thread 失败的问题。
如我们的测试环境下,SequoiaDB节点的 diaglog 的错误日志信息
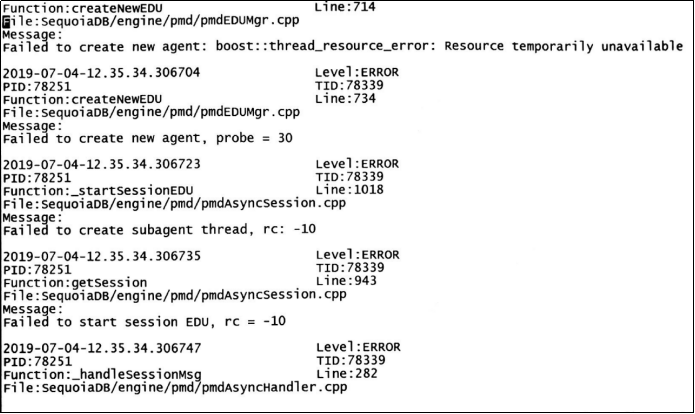
阅读这个错误日志的内容,通过看到类似如下的关键信息:
Failed to create new agent: boost::thread_resource_error: Resource temporaily unavailable Failed to create new agent, probe = 30 Failed to create subagent thread, rc = -10 Failed to start session EDU, rc = -10
那么一般操作系统在创建线程时,会受限于哪些参数呢,主要有几个:文件句柄数限制、操作系统句柄数限制和内存资源。
1)文件句柄数
在linux 操作系统中,号称一切皆为文件,无论是进程、线程、socker 还是其他,最终都会被操作系统归为文件操作。操作系统或者进程,每申请一个资源,例如线程、socker,都会打开一个文件,那么这个文件打开状态,就可以简单理解为文件句柄。其中,“句柄数限制“代表操作系统或者某个进程所能够打开的最多文件的数量的限制。
大家有了这个概念后,我们再来看操作系统是如何对文件句柄数进行限制的。在操作系统中,有一个神奇的命令 - ulimit 。这一个命令可以设置许多限制值,进程文件句柄数就是其中之一。
例如我们可以查看 root 用户的 ulimit 输出, -n open file = 1024 就是root 用户允许进程打开的最大文件句柄数。
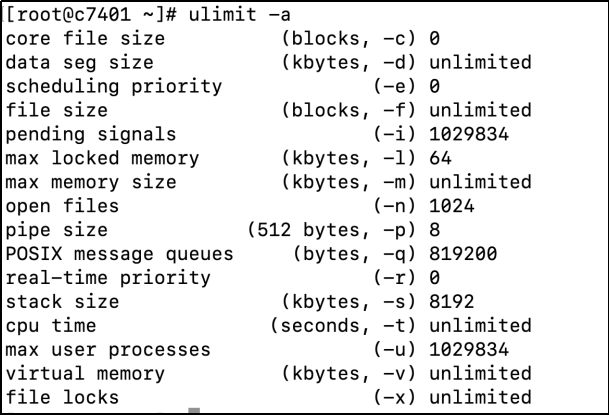
此处需要注意,由于root 用户是Linux 中的管理员用户,所以如果root 用户的 ulimit open file 设置成 1024, 那么其他的用户,例如test和mysql 用户等,想将 ulimit opon file 设置成 大于 1024是不行的。因此,普通用户的 ulimit 值修改前,必须要注意root用户的ulimit值,保证普通用户的ulimit值比root用户的设置值小。
2)操作系统句柄数
除了进程中的句柄数限制,整个操作系统的句柄数限制同样会对数据库运行产生影响。在句柄数限制下,因为一个操作系统,是不能无限地打开句柄的。所以又引入另外一个设置,操作系统最大打开的句柄数限制。
该值在 centos 7 中是被保存在 /proc/sys/fs/file-max 文件里
如果操作系统总的句柄数已经达到上限,那么即使进程还没有启动几个线程,也会出现句柄不够的情况
如果希望临时修改操作系统最大句柄数的设置,可以直接执行: echo 2000000 > /proc/sys/fs/file-max
如果希望永久修改操作系统最大句柄数的设置,可以编辑 /etc/sysctl.conf 文件,增加 fs.file-max = 2000000 内容,然后在root 用户中执行 sysctl -p 即可
3)内存资源
针对内存资源的优化,在创建线程时,在Linux 中,是需要给它预先分配内存的 – 也叫 栈大小,用来存储线程中数据的值。
我们程序员都知道,内存主要分为两个大的部分,一个称为 “堆”,一个称为“栈”。在程序中,“堆”通常是程序用来保存常量和变量名字的,“栈”则通常是程序来用保存具体的变量数字的。
此前我们说到,如果系统内存不足,也是无法创建线程的。这个原因就是在于创建线程时,操作系统需要分配一块内存给线程,这个内存是多大呢,就是 ulimit 中 -s stack size 的大小。如果操作系统连 stack size 大小的内容都无法拿出来了,创建线程就会失败。
整个服务器资源,为什么这么一点内存都没有了?
其实如果仔细查看操作系统就会发现,那么多进程,每个进程又是那么多线程在运行,每个线程都在申请内存(注意,这块的内存是物理内存),内存不足正常的很。这个也容易让人联想到JVM 的OOM ,但它们之间并无关联。
要解决这个问题也比较简单 – 直接粗暴?就是将 ulimit 中 -s stack size 调小一点,每个线程不要申请那么多内存了,操作系统的内存资源就会更加的充裕。毕竟程序、线程这些,都是用完就完了,不可能都永久占用内存的。
除了上述解决方案,如果仍无法解决创建线程失败的额问题,那么执行 ulimit -a 命令,参数看起来也正常,但是系统是否是完成了设置?此时需要确认 SequoiaDB 进程的ulimit 参数是什么。
确认的方式有两种:
在sdb的较新版本中,节点启动时的diaglog 日志,会打印它自己的 ulimit 参数,读者可以去翻翻日志
另外一种就更加直接,直接查看 linux 的系统记录。例如知道 11910 进程的 PID 是 123456,就直接打开 /proc/123456/limits 文件,查看里面的内容
查看 某个进程总共开启了多少个 线程,可以
cat /proc/$PID/status | grep Threads pstree -p $PID
因为有主进程,所以需要+1
top -Hp $PID
查看头部 “Threads”参数
ps hH p $PID | wc -l
查看linux 目前总打开的句柄数
lsof -n|awk '{print $2}'|sort|uniq -c|sort -nr|awk '{print $1}' | awk '{sum += $1};END {print sum}'查看某个进程打开的总句柄数
lsof -n|awk '{print $2}'|sort|uniq -c|sort -nr | grep $PID





