SequoiaDB是一款分布式关系型数据库,是国内为数不多拥有自主知识产权的开源数据库。目前SequoiaDB已经在GitHub上开源。
SequoiaDB主要的功能特点是支持分布式事务、2003标准SQL、同时提供文档存储引擎和块存储引擎、与大数据产品有良好的整合。
SequoiaDB开发接口
API开发接口
SequoiaDB的API开发接口,是功能最全的开发接口,目前已经支持C、C++、Java、Scala、Python、C#、Perl、Javascript多种开发语言。
SequoiaDB的API支持对数据库做所有操作,包括:增删查改、数据库扩容、数据迁移、数据库节点启停、增减集合空间和集合、监控数据库状态信息等。
SequoiaDB的API开发风格偏向对象式操作,以Java驱动为例,向数据库写入一条记录,代码如下。

图 1
但是C语言的API驱动由于开发语言的限制,开发方式还是遵循面向过程式开发,以下是C语言驱动向数据库写入一条记录的代码。
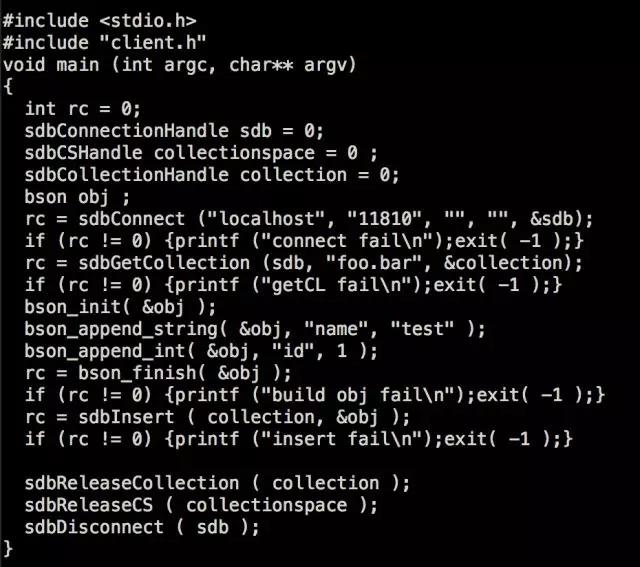
图 2
SequoiaDB的安装包已经包含了大部分常用的API驱动,用户可以在安装数据库后直接使用。用户也可以通过SequoiaDB官网下载各个开发语言的驱动包。
大数据开发接口
SequoiaDB和很多大数据产品都有较好的整合,例如:Hadoop MapReduce、Hive、Spark RDD、SparkSQL,用户可以通过扩展大数据产品的存储层,使得存储在SequoiaDB的数据为大数据提供源数据。
简而言之,SequoiaDB和大数据产品的关系就是存储和计算框架的关系。
SequoiaDB和各类大数据产品的对接方式都是通过配置大数据产品的连接方式进行,例如SequoiaDB和Spark的对接,就是对Spark的spark-env.sh 配置文件增加SPARK_CLASSPATH参数。
SPARK_CLASSPATH="/opt/sequoiadb/sequoiadb-driver-SNAPSHOT.jar:/opt/sequoiadb/spark-sequoiadb-SNAPSHOT.jar"
当大数据产品和SequoiaDB完成了对接,那么后续的使用和开发流程与使用原生的HDFS或者本地文件没有本质区别。
SQL开发接口
SequoiaDB的SQL开发接口包含两种方式,一种是社区版的基于PostgreSQL扩展的SQL引擎,另外一种是由SequoiaDB公司提供的SequoiaSQL产品,两者的SQL语法都使用PostgreSQL的SQL语法,支持2003 SQL规范,并且都支持存储过程、事务功能和JDBC服务。但是两者在复杂SQL关联实现机制上有所不同,社区版本的PostgreSQL仅支持Hash Join关联方式,而SequoiaSQL同时支持NL Join和Hash Join两种关联方式,能够更好适用在复杂的SQL关联场景。
实时数据处理
在实时处理场景,通常都是对数据库做高并发的增、删、查、改操作,此时需要数据库的索引功能支持,所以开发者可以采用API接口或者是SQL接口,不建议使用大数据相关开发接口做应用开发。另一方面,实时数据处理也有可能是由流式处理引擎+数据库共同处理,所以开发者在开发流式处理程序时,需要结合SequoiaDB的驱动程序进行开发,例如Spark Streaming的开发程序通常使用Scala语言和Java语言,如果是Store流处理引擎,开发者更多是选择Java作为开发语言。
跑批数据处理
如果开发者要使用SequoiaDB做跑批类数据处理,应该选择SequoiaDB与大数据产品相结合的技术方案。如果发者希望使用SQL命令做数据处理,那么可以考虑采用SparkSQL或者Hive做开发。如果开发者需要处理的业务场景非常复杂,普通SQL很难满足开发需求,那么可以考虑采用MapReduce或者RDD开发接口,由开发人员直接根据业务逻辑使用程序实现相应的数据处理流程。
开发者在选择SequoiaDB的开发方式时,通常出现选择困难症,究竟是选择使用API还是SQL。其实这个问题没有绝对的答案,主要要看开发者将要实现的场景。
首先开发者应该了解两种接口各自的优缺点。
API 优点
1. 性能优,所有的开发接口中性能最高的
2. 支持操作块存储
3. 支持数据库所有操作接口,包括监控、启停节点等数据库运维接口
API 缺点
1. 开发方式与传统的JDBC不同,需要开发者适应
2. 对多表关联支持不好,需要开发者使用程序完成表关联操作
3. 缺乏数据处理函数,大部分需要用户使用程序实现
SQL 优点
1. 符合传统开发者习惯,学习成本低
2. 提供多表关联功能
3. 提供丰富数据处理函数,开发相对便捷
4. 做原有系统程序迁移,开发成本低
SQL 缺点
1. 性能相对API有所下降,下降幅度大概在10%-15%
2. 对全表做count、group by、sort等统计操作性能相对较差
3. 不支持直接操作SequoiaDB的块存储
4. 开发者需要同时维护SequoiaDB中的集合和SQL引擎中的table信息
5. 无法调用数据库的运维相关命令
所以根据以上特性,开发者可以在以下场景选择API进行系统开发:
(1) 最求性能最大化
(2) 新系统开发
(3) 业务场景相对简单的场景使用API
(4) 需要使用块存储的场景
在以下场景选择SQL进行系统开发
(1) 需要使用复杂关联查询
(2) 需要使用多种数据处理函数
(3) 对原有系统进行应用迁移
(4) 系统不会经常对全表做count、group by和sort这类统计操作
结论
由于SequoiaDB的开发接口相对过去传统的关系型数据库多,所以本文通过对SequoiaDB各种接口的技术特性向广大开发者进行介绍,希望能够让开发者更加了解SequoiaDB的开发特性,然后可以在不同的开发场景中选择适合的接口进行开发,以获得性能最优的效果。






