近期,巨杉数据库 受邀在第七届数据技术嘉年华中做了“金融级数据库技术与实践”为主题的演讲,分享了巨杉数据库有关金融行业数据库管理以及金融级数据库技术与应用的一些实践及思考。

数据爆炸:数据呈现急剧增长,对数据存储的数据量,并发性和响应速度都提出了更高要求。以大型商业银行为例,通常它们拥有成百上千个业务系统以及上亿用户的海量数据,且数量呈现指数级增长,从TB级别增加到PB级别,未来很快就会增加至EB级别,这些都需要有效的管理以及实现实时访问。
数据融合:不仅是金融行业,在过去,各个业务的数据都是以孤岛的形式独立存在,而我们需要的是跨业务、跨业务系统的数据统一管理和维护,甚至需要统一架构支撑下的数据沟通交流。打破数据孤岛就成为金融行业的切实需求。

非结构化数据:非结构数据在金融行业数据量上的占比逐渐占绝对优势的一种数据存在的形式。图像、图片、语音、有格式的文档都是非结构化数据,非结构化数据量每年增长80%左右。数据量的快速增加,再加上对银行业两地三中心数据安全的要求,对非结构化数据的存储和管理的要求就提高了。这也是金融业的行业需求。
随着银行远程开户、柜面无纸化、双录、会计档案管理等系统的建立和升级,影像系统除了满足商业银行在线业务系统不断提升的访问性能需求外,还需要提供作为在线系统的高可用、灾备甚至“双活”能力,以保证系统数据绝对安全。
面对金融行业的新需求,新一代金融级数据库需要在分布式架构、非结构化数据管理、多模式数据处理、标准化数据访问、数据可靠性、与混合负载等几个角度对传统数据库架构进行重新定义。
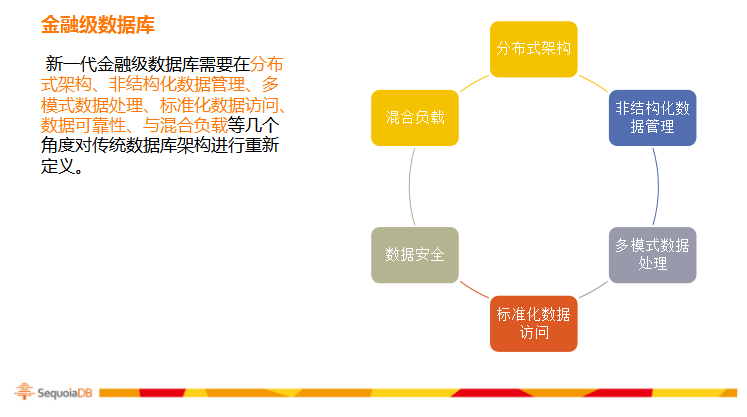
分布式架构
由于传统数据库的单点架构无法满足新型金融科技应用对数据量与并发能力的需求,新一代金融级数据库必须采用分布式架构来应对该类挑战。分布式架构,将海量数据均匀存储在多台物理设备中,以避免单一设备所造成的瓶颈。同时,分布式数据库的灵活扩展能力,为金融业务增长提供了弹性的容量与性能支持,在大规模数据应用中具有明显的技术优势。
我们以巨杉分布式架构为例,无论是数据还是文件系统等元数据都要进行分布式存储,同时元数据的管理也应该是分布式、高可用、没有单点故障的。分布式架构必须具备弹性拓展和性能线性增长,同事分布式架构可以有效降低TCO、总体应用成本。分布式架构有很好的管理能力,可以降低开发运维的成本。
多模式数据管理---非结构化数据管理
如今,在金融业务“互联网化”和“零售化”的趋势下,金融机构开始向用户提供更多个性化、定制化的产品与服务。特别是非结构化数据,增长最为迅猛。
通常来说,结构化数据特指表单类型的数据存储结构,典型应用包括银行联机交易等传统业务;而半结构化数据则在用户画像、物联网设备日志采集、应用点击流分析等场景中得到大规模使用;非结构化数据则对应着海量的的图片、视频、和文档处理等业务,在金融科技的发展下增长迅速。
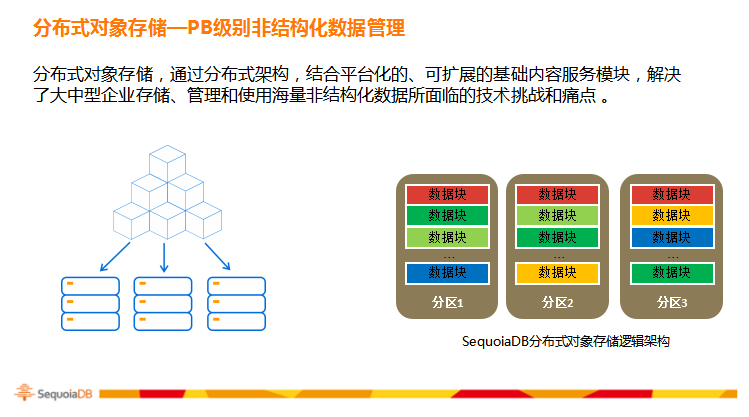
为了实现金融业务数据的统一管理和数据融合,新型数据库需要具备多模式(Multi-Model)数据管理和存储的能力,以满足应用程序对于结构化、半结构化、非结构化数据的管理需求。
多模式数据管理能力,使得金融级数据库能够进行跨部门、跨业务的数据统一存储与管理,实现多业务数据融合,支撑多样化的金融服务。
标准数据访问与混合负载
根据Gartner的最新定义,混合负载在保留原有联机交易功能的同时,也强调了数据库原生计算分析的能力。支持混合负载的数据库能够避免在传统架构中,在线与离线数据库之间大量的数据交互,同时也能够针对最新的业务数据进行实时统计分析。
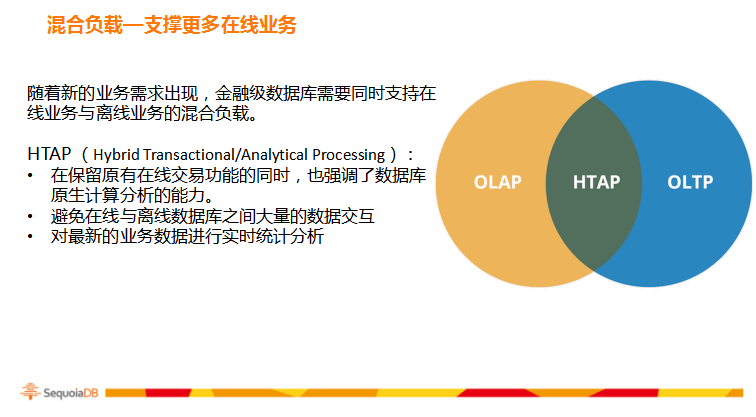
为了避免在线实时读写与批处理作业之间的资源干扰,混合负载型数据库通常使用读写分离或内存处理技术实现。一般来说,分布式数据库的多副本架构天然支持读写分离技术,而基于传统架构的数据库往往采用内存处理技术进行实现
数据安全
伴随着在企业内部价值的不断提升,数据已经成为了金融企业的生命线与核心资产。作为承载着企业关键数据的数据库,其安全性、可靠性、稳定性一直是金融级数据库的核心价值。
数据安全领域重要的一个概念是容灾能力,银监会就要求银行业要符合两地三中心的要求。这其实是一个数据多副本的思想,任何一个副本丢失我们还有其他副本可以支撑数据管理的需求,数据服务的需求。这对于金融企业显得尤其重要。
银行业分布式影像平台
银行业影像平台案例,是在某大型股份制银行实施的,该平台底层基于巨杉数据库,目前已经投入生产。
巨杉数据库适合于结构化、非结构化、半结构化数据存储。在应用层面提供对外的影像文件管理服务能力,有两台或者更多台具备负载均衡和高可用能力的应用服务器,服务器上对接的是银行内部业务系统,当需要查非结构化数据时就可以接入影像管理平台,巨杉数据库支撑的是PB级的数据存储,同时支持了高可用。
此外,巨杉数据库支持多索引,毫秒级别实时数据访问,这么大数据量下依然提供这么大的访问性能,总体应用成本跟过去影像平台对比可以降低三分之一,这是整个巨杉数据库分布式的架构决定的。
证券超高并发数据访问
证券交易主要特点是频度高,每天可能有上亿条交易数据。证券交易场景一般都是结构化数据,大量结构化数据进入系统提高高并发的结构能力。
这个系统可以帮助用户查询证券交易的所有历史交易明细,并且查询的返回速度依然很高,在海量数据情况下可能做到百毫秒以内的查询范围。
实现结果
· 平均每日超过2亿条记录写入
· 高峰时段,同时有超过百亿级别的数据需要被检索、调用
· 系统保存3年内所有交易和持有数据
· 峰值并发量超过10000
· 高峰时段,查询返回时间小于100ms
银行海量数据管理
关于银行海量数据的管理平台,实际上是银行多业务系统的结构化数据组成一个统一的查询平台,用户可以通过这个平台去查询业务,而不再需要查询原有业务系统,这样原有业务系统数据库的负载就降下来了。原有业务系统数据库只保存需要联机交易的那部分数据,其他的数据全部储存在巨杉数据库。
SequoiaDB利用其横向扩展、支持标准SQL以及双引擎的机制,能够在存储海量历史数据的同时对外提供在线查询与分析能力,这就使得银行能将传统的离线数据做到近线化,将冷数据有效地使用起来。
巨杉数据库的多家银行客户使用SequoiaDB提供高并发的数据查询和访问功能,使银行客户能够在柜台、网银、手机银行上随时随地查询开户以来所有的交易历史。同时,该平台可以提供司法查询的能力,使银行IT部门不需要为了复杂多变的查询请求,在历史带库与数据库之间疲于奔命。
其他案例
在政府行业,巨杉数据库可以对电子证件进行集中存储和查询,可以帮助行政服务大厅或者其他政府部门查询信息,提升工作的效率。
在交通领域,大量摄像头实时采集的图片和视频数据需要存储,并且现在还增加了实时处理分析套牌违规等行为,这背后也需要强大的数据存储管理查询或者存储引擎支撑海量的数据,巨杉数据库能够有效满足这种需求。
关于巨杉数据库
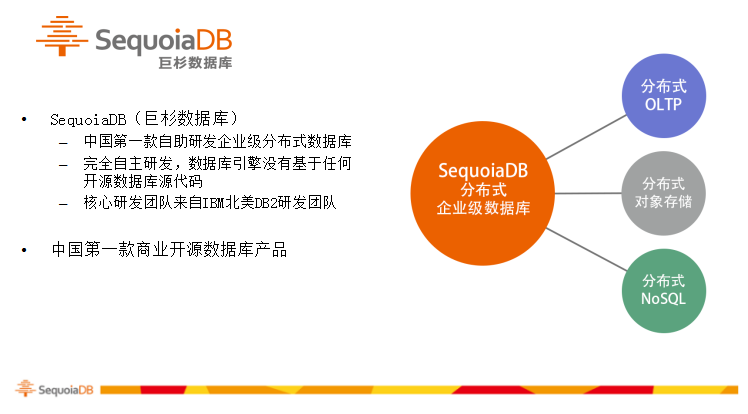
巨杉数据库是完全自主研发的金融级分布式数据库。公司的主要核心开发团队来自IBM北美DB2研发团队以及国内知名企业,作为中国本土第一款完全自主研发的分布式数据库,巨杉数据库页做了开源,在巨杉的官网(http://www.sequoiadb.com/cn/)有社区版的开源代码。
作为完全自主研发的金融级分布式数据库,我们的产品和技术上的创新能力得到业界的广泛认可,曾多次荣获硅谷、开源组织及金融机构组织的评奖活动。
SequoiaDB还入选硅谷2016年度大数据生态象限,成为唯一一家入榜的中国企业。







