随着互联网的飞速发展,互联网的业务量呈爆发性增长,对于的数据量也迅速激增。传统的单机数据库在存储空间及性能的瓶颈,导致其将无法支撑企业业务的高速发展。伴随着海量数据对系统性能,成本以及扩展性的新需求,分布式数据库系统应运而生。sequoiadb作为是一款优秀的分布式文档型数据库,其底层基于分布式,高可用,高性能与动态数据类型设计的,能够应对海量数据的存储,及提供高效检索。
传统数据库可以利用分布式数据库的优势来缓解其自身的瓶颈。比如,将历史数据迁移到sequoiadb,由sequoiadb提供存储及业务服务,以缓解传统数据库自身的压力。数据迁移分为全量迁移和增量迁移,本文主要对mysql到sequoiadb的增量数据迁移过程进行分析。
本文将通过一个小案例来分析数据从mysql数据库抽取,并经由spark对数据进行清洗转换,最后装载到sequoiadb的迁移过程。
源数据mysql中有两张待迁移的数据表分别为student表和grade表,我们需要对grade表进行增量迁移,每次只迁移更新的数据;此外,我们需要一张由student和grade整合的大表,方便提供查询服务。
具体方案为先通过select ...... into outfile ......方式从mysql数据库中导出数据为csv格式文件,指定导出编码为gb18030(此处模拟银行数据编码),经由java将文件编码由gb18030转为utf8编码类型;然后,针对不同的数据,选择不同的导入的方式。对于增量的数据可以调用sdbimprt和sdbupsert工具结合的方式来导入到SDB集群中,对于需要额外加工处理的数据可以利用spark的RDD特性进行处理并加装到sequoiadb集群中。
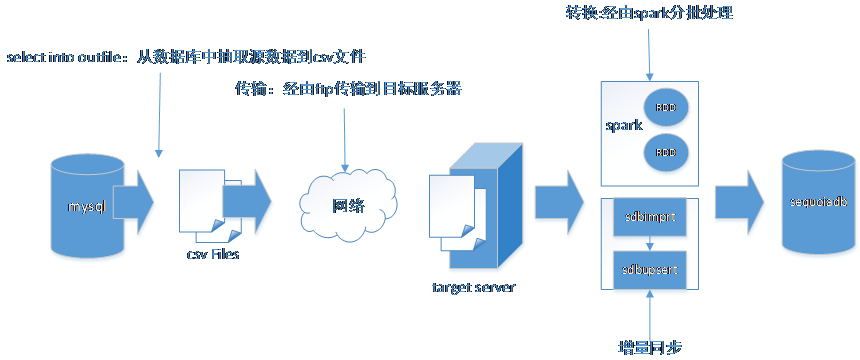
数据迁移流程
mysql数据抽取
mysql导出数据可以使用mysqldump工具,也可用select into outfile的方式,此处使用select into outfile方式进行数据抽取,执行以下语句即可实现带条件抽取指定数据到指定目录下。其中参数character 指定为gb18030 编码,fields 分隔符为",",lines 分隔符为'\n'。
select * from student where id < 51 into outfile '/data/hbh/student.csv' character set gb18030 fields terminated by ',' lines terminated by '\n'; select * from grade into outfile '/tmp/grade.csv' character set gb18030 fields terminated by ',' lines terminated by '\n';
在执行select into outfile语句时,应确保具有MySQL的FILE权限,否则会遇到权限问题;并且输出文件必须不存在。这可以防止MySQL破坏重要的文件。
数据迁移准备
我们迁移的目标数据库为sequoiadb,此案例中我们根据sequoiadb分布式的优势,结合它的数据分区特性,采用多维分区的方式将海量数据分散到多个数据分区组上进行存储。该方式通过结合了Hash分布方式和Partition分布方式的优点,让集合中的数据以更小的颗粒度分布到数据库多个数据分区组上,使得数据库的性能得到极大提升。
1) 对抽取出来的数据进行转码
利用Linux自带的转码工具iconv进行转码,将编码由gb18030 转为utf8
iconv -t utf-8 -f gb2312 -c filename > newFilename
-f 原编码
-t 目标编码
-c 忽略无法转换的字符
2) 创建目标表(主子表模式)
//创建主表
sdb 'db.createCS("test")'
db.test.createCL("clname",{ShardingKey:{_id:1},ShardingType:"range",IsMainCL:true})
//创建子表
db.createCS("clname1",{Domain:"test_domain"}).createCL("clname1",{ShardingKey:{"_id:1"},ShardingType:"hash",Compressed:true,CompressionType:"lzw",AutoSplit:true})
//挂载
db.test.clname.attachCL("clname1.clname1",{LowBound:{_id:MinKey()},UpBound:{_id:MaxKey()}})'
//对主键建立唯一索引
db.test.clname.createIndex("id_Idx",{id:1},true,true)
增量数据迁移
1)sdbupsert更新迁移
增量的数据分为新增数据和更新数据,对于新增数据可以根据import工具直接导入,对于更新数据可以利用sdbupsert工具进行更新插入。sdbimprt工具导入数据时,对于更新后的数据而不是新插入的数据,在有唯一性约束的情况下就会出现键值重复(Duplicate Key)的异常,并且这些异常数据会以Json格式记录在.rec结尾的文件中(与导入的数据文件在同一目录下)。sdbupsert的功能就是将这些键值重复的数据upsert到SDB数据库中。并且支持多线程并发导入。
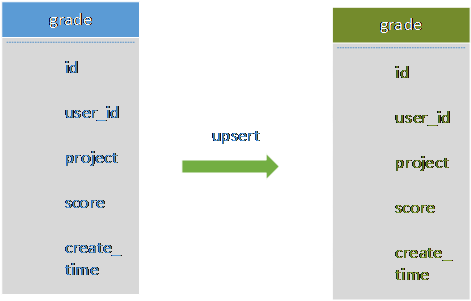
增量迁移
1) 使用sdbimprt导入工具进行导入迁移
sdbimprt --hosts="server1:11810,server2:11810,server3:11810" --delfield="\44" --type=csv --file=clname.csv -c test -l clname --fields='id string, user_id string,project string, score double, create_time string' -n 1000 -j 100
2) 使用sdbupsert进行更新迁移
对于键值重复的数据sdbimprt会记录在.rec结尾的文件,使用sdbupert进行更新导入。
java -jar sdbupsert.jar sdb.properties clname.rec
参数说明:
sdb.properties: 配置文件,含有调控参数,及连接参数配置
clname.rec:需导入的数据文件,json格式类型
2)表合并操作
在数据库的常见模型中(比如星型模型或者雪花模型),表一般分为两种:事实表和维度表。维度表一般指固定的、变动较少的表,例如联系人、物品种类等,一般数据有限。而事实表一般记录流水,比如销售清单等,通常随着时间的增长不断膨胀。这里的student表类似于维度表,grade表类似于事实表。对于这种大小表关联的join操作,sparkSQL有两种实现分为Broadcast Join和Shuffle Hash Join。在SparkSQL中,对两个表做Join最直接的方式是先根据key分区,再在每个分区中把key值相同的记录拿出来做连接操作。但这样就不可避免地涉及到shuffle,而shuffle在Spark中是比较耗时的操作,Broadcast Join为了避免shuffle,我们可以将大小有限的维度表的全部数据分发到每个节点上,供事实表使用。executor存储维度表的全部数据,一定程度上牺牲了空间,换取shuffle操作大量的耗时。但是这种方式只能用于广播较小的表,否则数据的冗余传输就远大于shuffle的开销。当维度表较大时,可以使用Shuffle Hash Join方式,利用key相同必然分区相同的这个原理,SparkSQL将较大表的join分而治之,先将表划分成n个分区,再对两个表中相对应分区的数据分别进行Hash Join,这样即在一定程度上减少了driver广播一侧表的压力,也减少了executor端取整张被广播表的内存消耗。
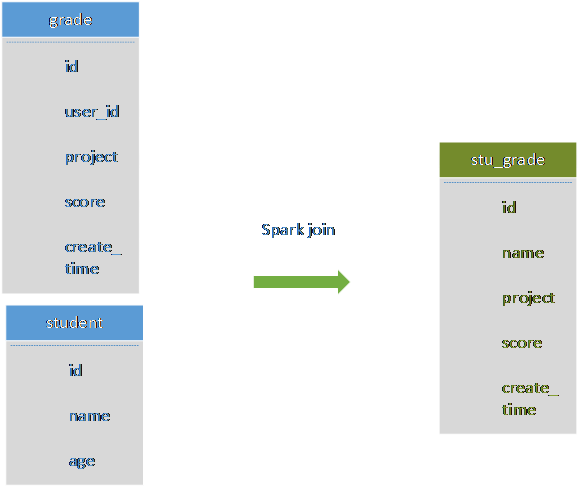
Spark join同步数据
Spark作为一个分布式的计算引擎,可以通过分区的形式将大批量的数据划分成n份较小的数据集进行并行计算。我们利用其这种特性可以进行大批量的数据的join关联操作,并落地到sequoiadb数据库中。
将需要做join的两张表数据分别加载出来做成dataframe,然后创建为临时视图进行join操作,之后将没份结果集插入到sequoiadb中。
val db= new Sequoiadb("192.168.5.188:11810","","")val stu_grade=db.getCollectionSpace("test").getCollection("stu_grade")
import spark.implicits._
val spark = SparkSession .builder() .appName("SparkSQL_join") .config("spark.some.config.option", "some-value") .getOrCreate()
val user_array = Array(StructField("id", StringType, nullable = true),StructField("name", StringType, nullable = true),StructField("age", IntegerType, nullable = true)) val user_schema = (StructType(user_array)) val user_df = spark.read.schema(user_schema).csv("user.csv") user_df.createTempView("user_tbl"); val grade_array = Array(StructField("id", StringType, nullable = true),StructField("user_id", StringType, nullable = true),StructField("project", StringType, nullable = true),StructField("grade", IntegerType, nullable = true),StructField("create_time", IntegerType, nullable = true)) val grade_schema = (StructType(grade_array)) val grade_df = spark.read.schema(grade_schema).csv("grade.csv") grade_df.createTempView("grade_tbl") val user_grade = spark.sql("select g.id,u.name,g.project,g.grade,g.create_time from user_tbl u right join grade_tbl g on u.id=g.user_id") user_grade.foreachPartition(partitionOfRecords => { partitionOfRecords.foreach(pair => { val id = pair.get(0) val name = pair.get(1) val project = pair.get(2) val grade = pair.get(3) val create_time = pair.get(4); stu_grade.insert("{'id':'"+id+"','name':'"+name+"','project':'"+project+"','grade':'"+grade+"','create_time':"+create_time+ "}") })数据迁移是系统开发经常涉及到的一项工作。在企业级应用系统中,新系统的开发,新旧系统的升级换代,以及正常的系统维护,不可避免地涉及到大量的迁移工作。数据迁移看视简单却蕴含许多技术实现细节。本文粗劣的介绍了数据迁移的整个流程,及一些迁移的方式,还有许多迁移的细节,包括数据的检查,迁移前后数据一致性等尚未涉及。







