分布式数据库从过去成为NoSQL的数据库发展开始,底层的数据存储结构变得多样化,包括KV、文档、列式等结构。各自有自己擅长的业务应用场景,例如操作型和分析型就是最简单的区分。
然而SQL的支持成为了业界的共识。 SQL语言几十年的发展已经非常成熟,技术基础也非常广泛。全世界90%以上的开发,无论业务操作型还是分析型都以SQL的数据处理为主。无论底层数据存储结构是关系型还是非关系型都将对系统开发透明。开发者只需根据自己的业务场景来选择合适的数据库,但不需要改变自身的开发模式。
本篇文章主要是向大家介绍分布式数据库的关联查询基本原理,以及用户在使用SequoiaSQL做关联查询时应该注意哪些地方,也希望用户能够通过本篇文章了解到更多分布式数据库操作的相关知识,同时帮助用户快速掌握SequoiaSQL的开发和使用技巧。
关联查询在传统数据库使用
在关系型数据库中如果要介绍关联查询,那么必然会涉及到数据库范式设计的内容。那么为什么关系型数据库会有范式设计这种开发理念,这还得从关系型数据库的发展历程说起。
关系型数据库是从上世纪70年代开始发展起来的,那个时候硬件设备的成本价格是非常高的,那个时候像十几MB的存储硬件就已经是顶配级别了,即使到了90年代,硬盘的存储空间也就是达到几百兆级别,价格依然昂贵。
所以关系型数据库是在一个存储资源极度紧张的背景下诞生的,在这种情况下,数据库研发的理念理所当然的往“尽可能利用存储空间”方向发展,同样使用数据库的用户也同样想尽办法往数据库中多存储有价值数据库。
资深的DBA明白,要想数据存储冗余低,那么遵循范式设计是非常有效的方法。
范式设计,核心思想就是尽可能确保表中每一列的数据都不会产冗余,例如第一范式里要求数据库表中所有字段值都是不可分解的原子值,第二范式里要求数据库表中的每列都和主键相关,第三范式里要求数据库表中消除与主键之间的间接相关。
关联的作用
由于关系型数据库的范式设计开发理念,所以会导致过去建设一个完整的系统,会有比较复杂的数据模型,可能一个系统会包含几十甚至上百张数据表,而每张表之间都有主外建关联关系。
在这种数据模型下,用户如果要在系统中查询某些数据,则可能需要同时用到几张表甚至是几十张表的数据才能够得到完整的结果集。所以要在这种遵循范式设计的系统中操作数据表,就难以避免需要用到数据库的关联方法。
常见关联查询策略
在传统的关系型数据库中,最常见的关联策略有三种,分别是:NL Join(Nest Loop Join)、Hash Join和Merge Join。
1)NL Join
NL Join的技术原理相对来说比较好理解,实际上读者可以理解为两张表一条记录一条记录地作比对,如果符合关联条件则关联成功。
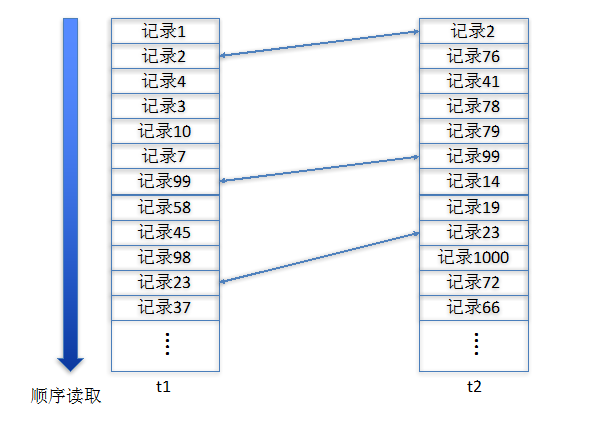
图 1
使用伪代码来表示则是
for (int i=0; i<t1.length; ++i) {
for (int j=0; j<t2.length; ++j) {
if ( t1[i] == t2[j] ) {
return ( t1[i], t2[j] )
}
}
}
在没有索引情况做NL Jion,复杂度为O(N*M)。
NL Join关联方法通常使用在
1) 左表(也叫驱动表、外部表)数据量较小
2) 右表(也叫探查表、内部表)中匹配字段支持索引查询,并且能够做高效查询
典型的SQL命令如下
select t1.name,t2.info
from t1,t2
where t1.id=t2.id and t1.num="123456789";
2)Hash Join
Hash Join的技术原理是将其中一张记录较少的数据表加载到Hash Table上,再通过遍历另外一张表的数据,通过对关联字段做Hash后对Hash Table上的数据做关联匹配,如果匹配成功,则证明该记录符合关联条件,否则继续读取下一条记录做关联。
该方法主要利用Hash Table的分区以及内存提升匹配速度,用户需要确保服务器的内容足以缓存下数据量较少的表的所有数据,否则超出部分将需要写入到磁盘的临时文件上。因此用户可以在内存不足情况下,考虑采用SSD存储来提升临时文件的读写性能。
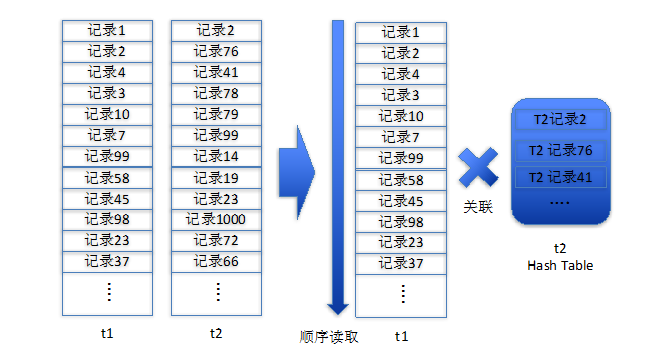
图 2
在内存足够的情况下,Hash Join 的复杂度仅仅为O(N+M)
所以Hash Join主要使用的场景是
1) 关联的表数据量较大
2) 机器内存足以缓存全部或者绝大部分关联数据
3) 只能用在等值匹配关联匹配上
典型的SQL命令如下
select t1.name,t2.info
from t1,t2
where t1.id=t2.id;
3)Merge Join
Merge Join也被称为Sort Merge Join,顾名思义,就是要对需要关联的表根据关联字段做排序后再做匹配关联计算。
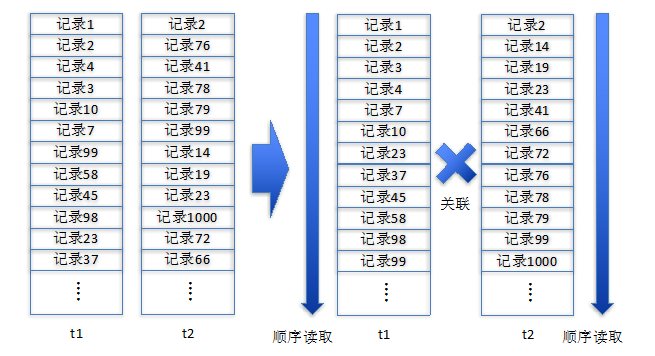
图 3
Merger Join的实现步骤比较复杂,读者可以理解为程序同时对两张已经排好序的表从头开始读取匹配字段的值,如果两者值不相同,则一方选择下一个值继续匹配,如果匹配成功,则一方读取下一个值继续匹配,直至任意一张表的所有数据读取完毕,匹配程序结束。
例如SQL引擎要对t1和t2两张表做Merge Join,两表的排序方式为升序排序,Merge Join的过程如下图示。
SQL引擎从两表的第一行开始匹配,发现左表的1值小于右表的2值,所以左表读取下一条记录继续匹配,当左右两表的值都为2时,该记录符合匹配条件,然后右表读取下一条记录继续匹配,发现两者不等于并且左表值小于右表值后,左表读取下一条继续匹配,一直到t1或者t2表的数据全部读区完毕,Merge Join才算结束。

图 4
Merge Join如果不考虑排序的开销,效率要比Hash Join要高,但是如果左右表都需要做复杂度O(n*)的排序,则关联效率肯定要比Hash Join要低。
Merge Join主要使用的场景为
1) 关联的字段在两张表中都索引,可以支持快速排序,或者需要关联的表的关联字段本身是有序的
2) 两张数据量较大的表关联,Merge Join的性能会比 NL Join性能要好
典型的SQL命令如下
select t1.name,t2.info
from t1,t2
where t1.id=t2.id order by t1.id , t2.id;
SequoiaSQL是SequoiaDB的SQL引擎,为用户提供基于SQL语言访问SequoiaDB的方法,能够大大降低用户需要重新学习SequoiaDB驱动API的难度,继续沿用JDBC驱动开发应用程序,同时也能利用成熟的GUI工具操作数据库。
SequoiaDB支持SQL
SequoiaDB本身是一款分布式文档型数据库,它为用户提供了各种开发语言的驱动程序,例如:Java、PHP、Python、C#、C++、C、Javascript等,但是这些驱动程序都只支持使用API方式操作数据库。
但是用户如果希望使用SQL语言对SequoiaDB做开发,也可以选择部署SequoiaSQL或者PostgreSQL来补充SequoiaDB的开发接口,这样用户就可以使用标准的JDBC驱动开发程序代码了。
SequoiaSQL支持的关联策略
目前用户可以通过SequoiaSQL或者PostgreSQL来扩展SequoiaDB的开发接口,并且两者都支持2003 SQL标准。但是两者在底层的运行机制上还是有所区别,最明显一点就是Sequoia SQL支持NL Join和Hash Join两种关联策略,而以PostgreSQL做为SequoiaDB的SQL引擎只能够支持Hash Join一种关联策略。
SequoiaSQL 关联策略说明
由于SequoiaSQL在做关联查询时,实际上数据的提供者就是SequoiaDB,所以在不同的关联策略生效时,对于SequoiaDB数据库有不同的表现。
例如
1) 如果SequoiaSQL使用Hash Join策略执行关联查询,则SequoiaDB会表现出大量的数据读,而索引读则为零;
2) 如果Sequoia SQL使用NL Join策略执行关联查询,则SequoiaDB会有较大的索引读,而数据读和索引读的数值相当。
用户可以在sdb shell中执行以下快照命令查看
db.snapshot(SDB_SNAP_DATABASE)
快照结果中,TotalDataRead代表数据读的数值,TotalIndexRead代表索引读的数据,该数值始终保持递增状态,如果用户想用更加简单的方法了解当前数据库平均每秒数据读和索引读的数值,可以使用sdbtop工具进行查看。
SequoiaSQL的NL Join功能由引擎配置文件的enable_nestloop参数控制是否开启,当然该功能默认是开启的。
SequoiaSQL在做关联查询时需要执行NL Join关联策略,需要满足以下条件
1) enable_nestloop参数设置为on
2) 关联右表(也叫探查表、内部表)的关联字段有创建索引
3) 关联左表(也叫驱动表、外部表)的数据量相对较少
SequoiaSQL在执行关联查询时,如果不满足NL Join的要求,则自动选择使用Hash Join完成关联查询。
查看关联策略
用户在SequoiaSQL的操作控制窗口中,可以通过explain+SQL命令查看引擎的关联策略,例如存在duebill和contract 两张表,每张表中都存储了2000万记录,并且两表的关联条件为
duebill.relativeserialno2=contract.serialno
图 5
如果开始时只对duebill表中relativeserialno2 创建了索引,而contract表中 serialno 字段没有索引,此时使用expalin查看访问计划,用户将会看到引擎是使用Hash join完成关联查询。
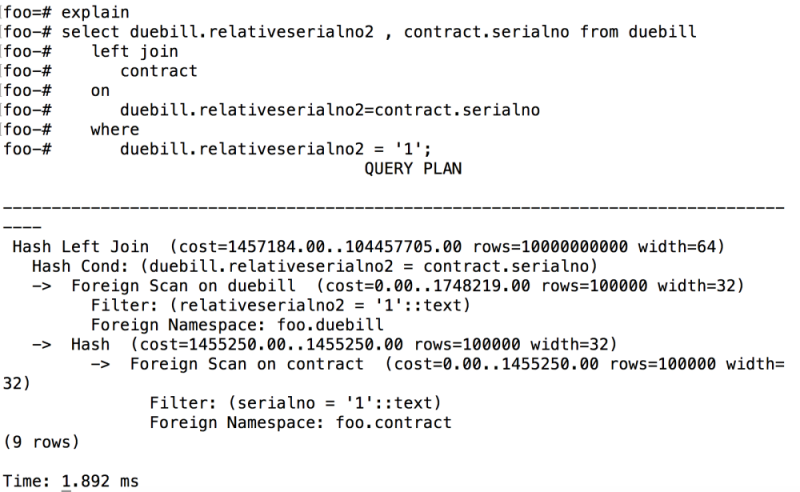
图 6
此时使用Hash join的SQL查询效率较低,需要18.9秒
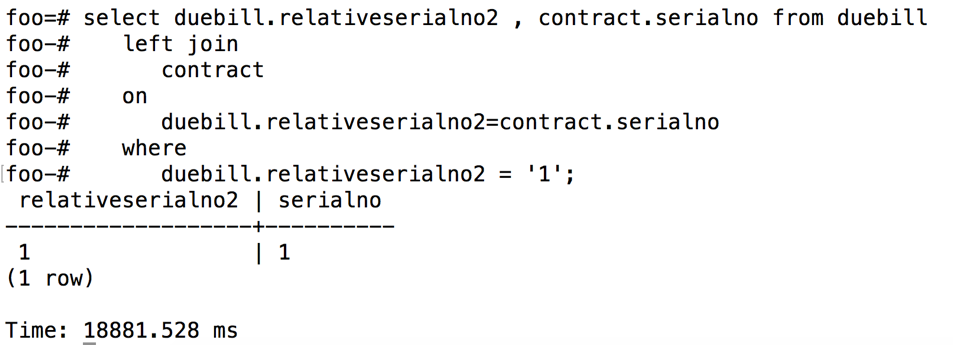
图 7
而如果用户对contract表中的serialno 字段创建索引后,再使用相同的SQL查看引擎的访问计划,将会变成NL join策略。
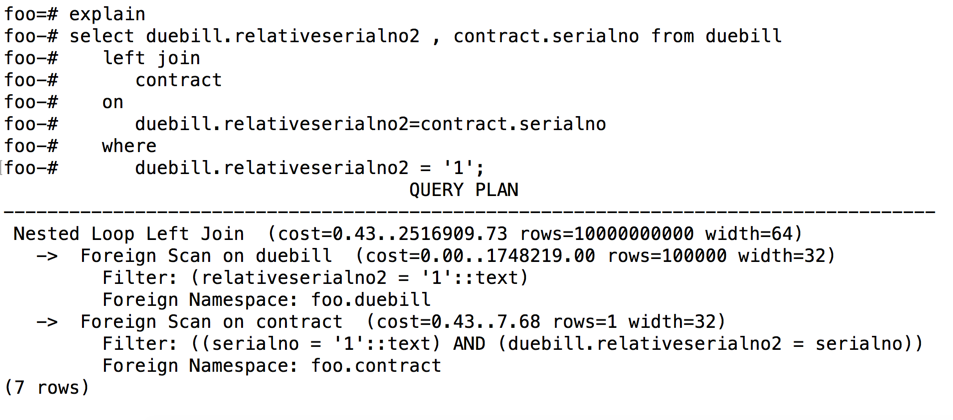
图 8
而且用户可以发现使用NL join 的查询效率比使用Hash join的查询效率高很多,关联查询只需要7毫秒。
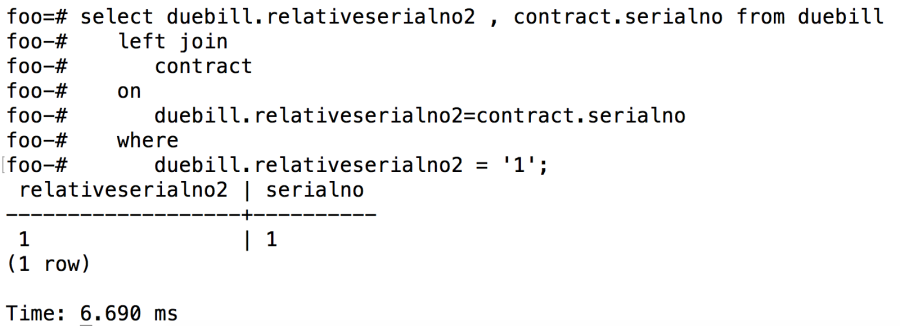
图 9
本篇文章主要向读者介绍了数据库在做关联查询时,数据库底层的技术原理。作者结合SequoiaSQL自身的技术特性,向用户介绍在什么场景下应该使用哪种关联策略,以及如果用户需要使用NL Join关联策略,SequoiaDB数据库应该满足什么条件才能够正确触发SequoiaSQL的NL Join关联查询。
SequoiaDB是一款分布式文档型数据库,自从在2013年发布之后,受到越来越开发者的喜爱和广泛的使用。SequoiaDB经过这些年的发展,功能覆盖已经较为全面,例如支持分布式事务、完整对接大数据主流产品、异地灾备、分布式块存储等,并且SequoiaDB还为开发者提供完整的SQL支持。
目前,SequoiaDB自研的SQL访问组件SequoiaSQL作为企业版的功能之一已经提供给上百家企业用户使用,并且已经实现分布式架构下的SQL 2003支持。
对于SequoiaDB社区版用户,我们可以通过SequoiaDB对接PostgreSQL 实现社区版的分布式SQL访问。这一应用方式基本也可以满足大部分的社区版需求。







