SequoiaDB作为分布式数据库,从设计之初就已经支持SQL访问。目前,SequoiaDB自研的SQL访问组件SequoiaSQL作为企业版的功能之一已经提供给上百家企业用户使用,并且已经实现分布式架构下的SQL 2003支持。
对于SequoiaDB社区版用户,我们可以通过SequoiaDB对接PostgreSQL 实现社区版的分布式SQL访问。这一应用方式基本也可以满足大部分的社区版需求。
本文就主要探讨如何使用PostgreSQL引擎对接SequoiaDB社区版实现HA高可用架构。
在一台机上分别安装centos 6.5、SequoiaDB 2.6、postgresql 9.3.4 、pgpool II 3.6.2,其中SequoiaDB为默认安装,PostgreSQL数据库则手动安装,安装在不同的目录中,使用不同的端口号。pgpool II 3.6.2则单独手动安装一个,并设好免密认证。
注:需要先配好PostgreSQL数据库之间免密登录及关闭防火墙。
PostgreSQL的安装
Step1
./configure --without-readline --without-zlib --prefix=/opt/postgresql/data02/pgpool/master
注:--prefix=path,是指PostgreSQL的二进制程序和文档将被安装到这个目录。默认值为 /usr/local
Step2:编译
make
Step3:安装
make install
Step4:修改文件权限
chown -R sdbadmin:sdbadmin_group /opt/postgresql/data02/pgpool/master
当安装完成后,可通过echo $? 命令验证,如果为0则表示安装成功,非0表示失败。安装成功如图1所示
:
图1
PostgreSQL复制流部署
先配置主库,再配置备库。
1)配置主库
Step1:初始化数据库
mkdir /opt/postgresql/data02/pgpool/master /pg_data /opt/postgresql/data02/pgpool/master /bin/initdb -D pg_data/
初始化成功则如图2所示:
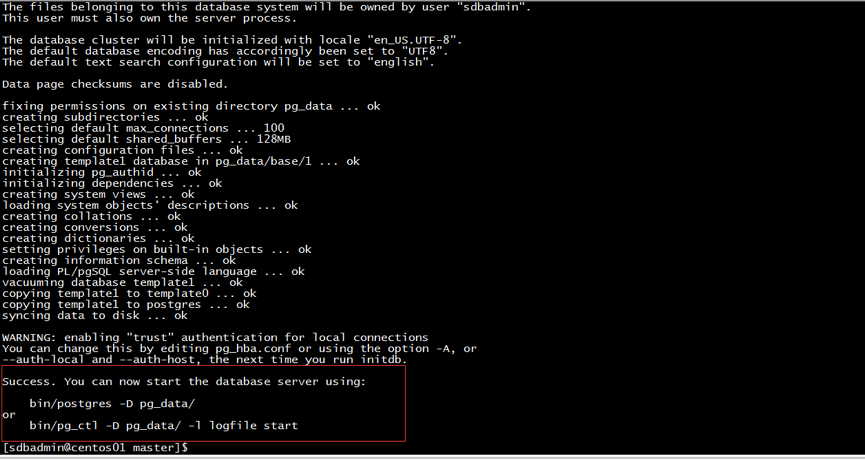
图2
Step2:修改 postgresql.conf配置文件
listen_addresses = '*' port = 7654 wal_level = hot_standby #这个是设置主为wal的主机 archive_mode = on #开启日志归档 archive_command = 'cp %p /opt/postgresql/data02/pgpool/master/pg_data/backup/%f' #WAL归档路径。 max_wal_senders = 1 #这个设置了可以最多有几个流复制连接,差不多有几个从,就设置几个 wal_keep_segments = 250 #设置log file 的段大小 wal_sender_timeout = 60s #设置流复制主机发送数据的超时时间 max_connections = 100 # 这个设置要注意下,从库的max_connections必须要大于主库的。
在搭建流复制环境时,并不必须设置 archive_mode 参数为 on ,很多资料在介绍搭建流复制环境时设置这个参数为 on ,可能是出于开启 WAL 归档更安全的原因,因为在主库宕机并且较长时间不能恢复时,从库依然可以读取归档目录的 WAL,从而保证不丢数据; 另一方面,如果主库设置了较大的 wal_keep_segments ,也可以不用开启archive_mode,因为主库保留了足够的 WAL,从而大大降低了因从库所需要的 WAL 被主库覆盖而需要从归档去取 WAL 的情况。所以从这方面说,archive_mode 参数的设置与搭建流复制并没有直接关系。提示:对于比较繁忙的库,在搭建流复制从库时,建议主库设置较大的 wal_keep_segments 参数。
其实可以在同一个postgresql.conf中把所有主从属性配置都配好,postgresql数据库能够自动识别哪些是主库参数,哪些是从库参数,但注意,有些参数在主库中不能配置,否则出错,比如不能再主库中开启热备模式(hot_standby = on)。配置完成后我们可以拷贝该库都另一个目录,当成备库。
注:当日志报“xxxxxxxxxxxxxxxxxxx WAL已经被移异常”时,有可能是 WAL被覆盖引起的或者DBA不小心把主库或从库的某个日志文件删了(如果开启了归档,则包含归档文件),即主库有而备库没有,或者备库有而主库没有都会引起该异常。解决方法:如果是主备日志文件异常(某个库缺个日志文件),则根据日志的异常把报错日志考到 另一个没有的库,在重启,如果是WAL日志被覆盖,则把主库整个pg_data数据路径下的pg_xlog日志文件拷到备库,如果是在开启归档模式下出现的异常,需要把归档文件都重新覆盖备库的,再重启,都不能解决,那就暴力的把整个pg_data目录拷贝到备库,在重启就可以了。
Step3:修改pg_hba.conf配置文件
# IPv4 local connections: host all all 127.0.0.1/32 trust host replication all 0.0.0.0/0 trust
Step4:启动服务,创建用户
/opt/postgresql/data02/pgpool/master/bin/pg_ctl -D /opt/postgresql/data02/pgpool/master/pg_data/ -l /opt/postgresql/data02/pgpool/master/log/pg.log start; #启动服务 /opt/postgresql/data02/pgpool/master/bin/createuser -P -d -a -c 5 --replication -e sequoiadb -p 7654 Enter password for new role: Enter it again: CREATE ROLE sequoiadb PASSWORD 'md570b40d6703c0a012afc8356f4511c197' SUPERUSER CREATEDB CREATEROLE INHERIT LOGIN REPLICATION CONNECTION LIMIT 5;
创建用户可根据自己需求赋予权限。
2)配置从库
Step1:拷贝主库为从库
cp -r /opt/postgresql/data02/pgpool/master /opt/postgresql/data02/pgpool/slave
Step2:修改从库 postgresql.conf配置文件
listen_addresses = '*' port = 4567 max_connections = 1000 # 一般查多于写的应用从库的最大连接数要比较大 hot_standby = on #说明这台机器不仅仅是用于数据归档,也用于数据查询 max_standby_streaming_delay = 30s # 数据流备份的最大延迟时间 wal_receiver_status_interval = 1s # 多久向主报告一次从的状态,当然从每次数据复制都会向主报告状态,这里只是设置最长的间隔时间 hot_standby_feedback = on # 如果有错误的数据复制,是否向主进行反馈
由于主备模式,主库可进行任何增删改查等操作,而从库只能提供查询操作,这是为了数据的一致性,因此,通常情况下会把查询都向从库进行,以减轻主库的压力。
Step2: 修改recovery.conf配置文件
把/share/recovery.conf.sample文件拷贝到数据库目录中,在复制模板。
cp /opt/postgresql/data02/pgpool/slave/share/recovery.conf.sample /opt/postgresql/data02/pgpool/slave/pg_data/ cp recovery.conf.sample recovery.conf standby_mode = on # 这个说明这台机器为从库 primary_conninfo = 'host=centos01 user=sequoiadb password= 123456 port=7654 keepalives_idle=60' # 这个说明这台机器对应主库的信息
其中,primary_conninfo配置可以与不需要用户名及密码,这是由于在pg_hba.conf中的信任关系为trust,所以可以不用填写。
3)主库对接SequoiaDB
Step1:从 SequoiaDB 的安装包中,拷贝 PostgreSQL 的扩展文件
su – sdbadmin cd /opt/postgresql/data02/pgpool/master cp /opt/sequoiadb/postgresql/sdb_fdw.so_2.8.1_27726 lib/ cp /opt/sequoiadb/postgresql/sdb_fdw.control share/extension/ cp /opt/sequoiadb/postgresql/sdb_fdw--1.0.sql share/extension/ cd lib/ ln -s sdb_fdw.so_2.8.1_27726 sdb_fdw.so
添加完软连接完成后,可查看文件(ls –trl )验证,如图3展示,则表示成功。
图3
Step2:登录主库,创建连接
/opt/postgresql/data02/pgpool/master/bin/psql –U sequoiadb –d postgres –p 7654 create extension sdb_fdw; create server sdb_server foreign data wrapper sdb_fdw options(address 'centos01', service '11810');
Step3:测试连接
create foreign table foo (name text, age int) server sdb_server options ( collectionspace 'foo', collection 'bar', decimal 'on' ) ; select * from test limit 1;
测试结果如图4:
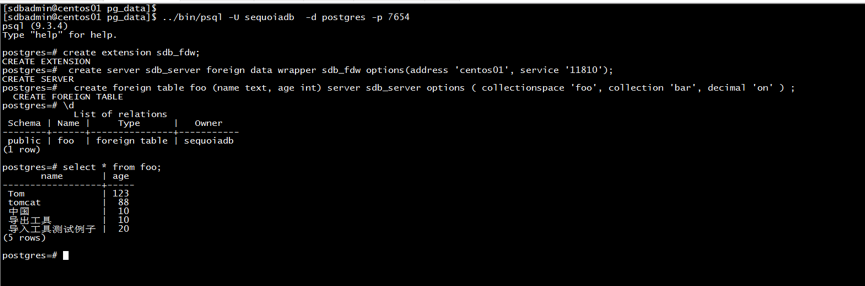
图4
4)测试复制流
Step1:启动备库
/opt/postgresql/data02/pgpool/slave/bin/pg_ctl -D /opt/postgresql/data02/pgpool/slave/pg_data/ -l /opt/postgresql/data02/pgpool/slave/log/pg.log start
查看日志如图5表示启动成功,进入主备模式。
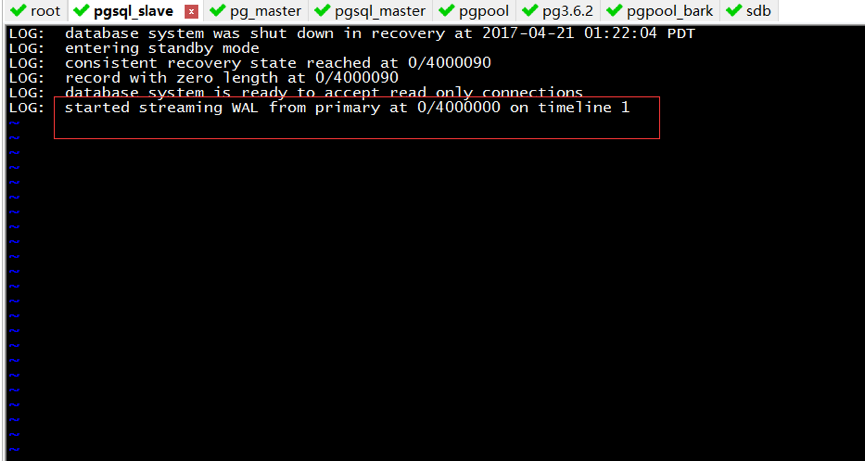
图5
Step2:登录主库,进行异步复制
select pg_start_backup('hot_backup');
select pg_is_in_backup();#查看是否在备份中backup。返回"t"表示true。“f”表示false。
select pg_stop_backup();其中,select pg_start_backup('hot_backup');语句里的hot_backup参数不是固定的,这里的 hot_backup 是任意DBA想使用的这次备份操作的唯一标识,DBA也可以指定备份文件存放全路径,如:select pg_start_backup('/opt/backup/backup_20170413');这是推荐使用的方式;select pg_stop_backup(),Postgresql将会生成一个文件,如“000000010000000000000000.003911E0.backup”,这是一个备份的历史文件。pg_stop_backup()将保留本次生成的备份历史文件,然后把上次执行本方式备份产生的备份历史文件清理掉,然后发信号告知归档进程(pg_stop_backup -> CleanupBackupHistory -> XLogArchiveCheckDone -> XLogArchiveNotify -> SendPostmasterSignal),可以归档了。
操作结果如图6所示:
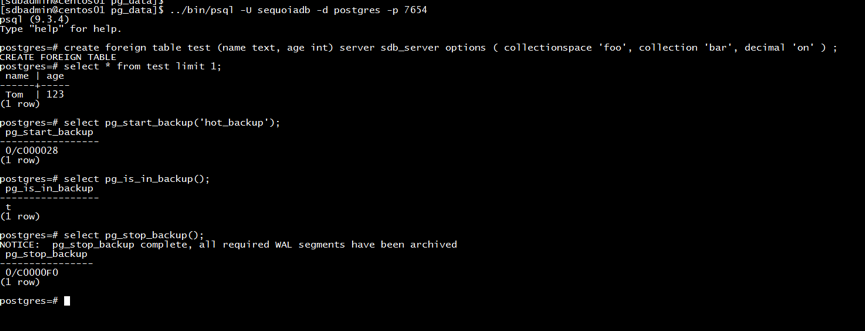
图6
Step3:登录备库,进行查看
../bin/psql –U sequoiadb –d postgres –p 4567 select * from test limit 1;
测试结果如图7所示,表示成功。
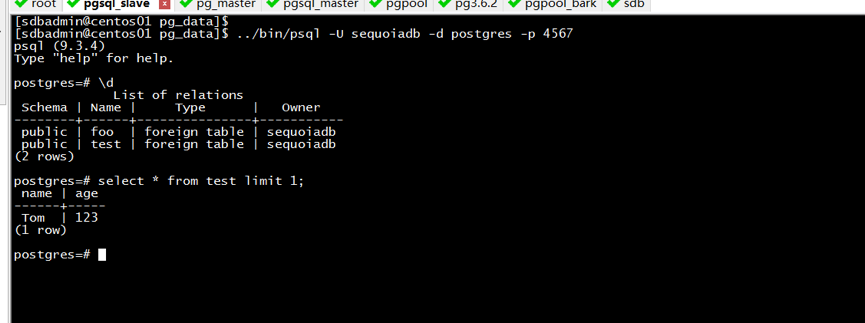
图7
1.安装pgpool
./configure --prefix=/opt/postgresql/data02/pgpool-II-3.6.2 --with-pgsql=/opt/postgresql/data02/pgpool/master make make install #需要root权限。
在编译安装过程中,如果出现libtool异常,重新编译安装时加上参数 --disable-libtool-lock,如:./configure -–prefix --with-pgsql=pg_path --disable-libtool-lock,特别注意的是,当不指定—prefix时,会默认安装在/usr/local/目录下,且无论是否把安装目录拷贝出来,每次执行都会到/usr/local/默认目录下读取配置信息,所以建议指定安装路径(--prefix)。如果安装成功,则会如图8所示:
图8
2. 安装 pgpool_regclass, pgpool_recovery 函数
安装pgpool_regclass, pgpool_recovery 函数库时,进入目录src/sql下,但无法直接使用make编译,会报找不到pg_config文件,因此,需要找到pg_config配置文件,该文件存在于postgresql安装目录中,如上面安时指定的—with-pgsql参数路径中寻找,并把其全路径替换掉Makefile文件中的变量PG_CONFIG =pg_config参数值,才能安装。当在src/sql目录下把Makefile参数改了,还是没能够编译安装时,则需要依次登录其库目录src/sql/pgpool_regclass和src/sql/pgpool_recovery,在分别替换掉Makefile文件中的变量PG_CONFIG =pg_config参数值,就能够安装 了。具体部署如下:
find /opt/postgresql/data02/pgpool/master -name “pg_config”; cd /opt/postgresql/data02/pgpool/pgpool-II-3.6.2/src/sql/pgpool-regclass; vi Makefile PG_CONFIG ?= /opt/postgresql/data02/pgpool/master/bin/pg_config :wq make make install
详情操作可如图9和图10 所示:
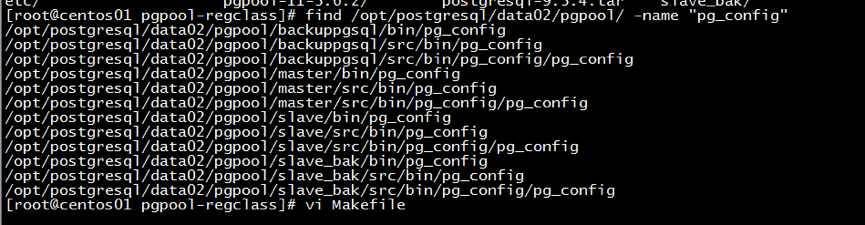
图9
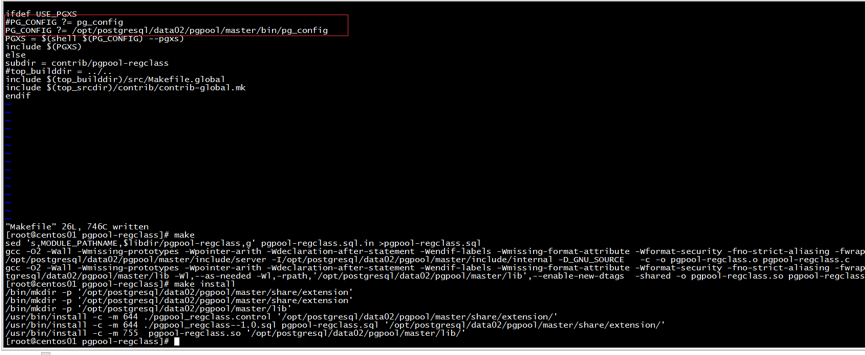
图10
安装pgpool_regclass函数库成功后,会在postgresql中的 /share/extension/目录下会有三个文件,分别为pgpool_regclass.control、pgpool_regclass--1.0.sql和pgpool-regclass.sql,而安装成功pgpool_recovery函数库,则在postgresql 中的 /share/extension/目录下也有三个文件,分别为:pgpool_recovery.control、pgpool-recovery.sql和pgpool_recovery--1.1.sql。
pgpool_regclass与pgpool_recovery函数库安装成功则如图11:
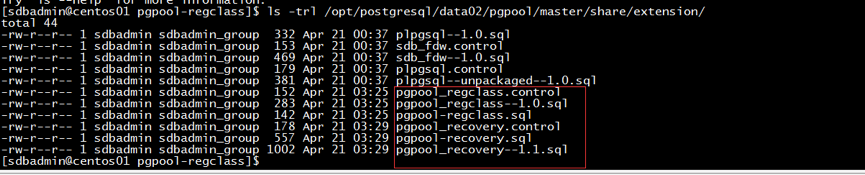
图11
3. 配置pgpool.conf文件
listen_addresses = '*' port = 9999 socket_dir = '/tmp' pcp_listen_addresses = '*' pcp_port = 9898 pcp_socket_dir = '/tmp' backend_hostname0 = 'centos01' #配置数据节点,可以是主机名或IP地址 backend_port0 = 7654 backend_weight0 = 1 #负载均衡中的权重值 backend_data_directory0 = '/opt/postgresql/data02/pgpool/master/pg_data' #指定节点0数据路径 backend_flag0 = 'ALLOW_TO_FAILOVER' #允许自动切换 backend_hostname1 = 'centos01' backend_port1 = 4567 backend_weight1 = 1 backend_data_directory1 = '/opt/postgresql/data02/pgpool/slave/pg_data' backend_flag1 = 'ALLOW_TO_FAILOVER' enable_pool_hba = on #开启pool_hba验证 pool_passwd = 'pool_passwd' #验证文件(pool_passwd格式为,客户端连接到pgpool的账户名 root:md5生成的密码) authentication_timeout = 60 #验证超时时间。 pid_file_name = '/opt/postgresql/data02/pgpool/pgpool-II-3.6.2/info/run/pgpool.pid' logdir = '/opt/postgresql/data02/pgpool/pgpool-II-3.6.2/info/status' load_balance_mode = on #开启负载模式 master_slave_mode = on #开启主备模式 master_slave_sub_mode = 'stream' #开启流模式 sr_check_period = 10 #流式复制检查周期默认为禁用(0) sr_check_user = 'sequoiadb' #流复制模式检测用户 sr_check_password = '123456' #检测用户密码 sr_check_database = 'postgres' #检测用户下的数据库 health_check_period = 10 #每10s检测数据库节点状态 health_check_timeout = 20 #20s无反应测超时,即检测两次无反应就超时,禁用为0。 health_check_user = 'sequoiadb' #检测某用户数据库节点状态 health_check_password = '123456' //被检测用户密码 health_check_max_retries = 0 health_check_retry_delay = 1 connect_timeout = 10000 failover_command = '/opt/postgresql/data02/pgpool/pgpool-II-3.6.2/fail.sh %H' memqcache_oiddir = '/opt/postgresql/data02/pgpool/pgpool-II-3.6.2/info/oiddir'
其中健康检测状态有四种,即status 由数字 [0 - 3]来表示。0 - 该状态仅仅用于初始化,PCP从不显示它。1 - 节点已启动,还没有连接。2 - 节点已启动,连接被缓冲。3 - 节点已关闭,。在节点关闭或者为0的时候可以用pgpool的pcp_attach_node命令来动态增加节点,包括以后动态扩充节点也可以。
在配置过程中,需要注意的时,在3.3.4版本的pgpool II中,如果你配置pid_file_name. logdir等默认路径为/tmp变量参数,则在登录pgpool时有可能应环境而无法等路pgpool,这是由于postgresql无法找到pgpool的 .s.PGSQL.8989和.s.PGSQL.6868文件,因为postgresql是在/tmp/目录下寻找的,即使你修改postgresql的unix_socket_directories参数值和pgpool上指定的路径相同,还是会出现异常,因此建议用默认值。
cp pcp.conf.sample pcp.conf ../bin/pg_md5 -u pgpool -p password: e10adc3949ba59abbe56e057f20f883e
操作详情如图12所示:
图12
5. 配置pool_hba.conf
cp pool_hba.conf.sample pool_hba.conf vi pool_hba.conf # IPv4 local connections: host all all 127.0.0.1/32 trust host sequoiadb postgres 0.0.0.0/0 trust
这里特别注意,不能用md5效验,因为md5不支持复制流模式、主备模式以及并行查询模式。
Pool_passwd配置哪些用户可以通过pgpool登陆数据库,格式user:md5
vi pool_passwd sequoiadb:md570b40d6703c0a012afc8356f4511c197
# Failover command for streaming replication.
# This script assumes that DB node 0 is primary, and 1 is standby.
#
# If standby goes down, do nothing. If primary goes down, create a
# trigger file so that standby takes over primary node.
#
# Arguments: $1: failed node id. $2: new master hostname. $3: path to
# trigger file.
new_master=$1
echo "new_master info =============== ${new_master}";
trigger_command="/opt/postgresql/data02/pgpool/slave/bin/pg_ctl -D /opt/postgresql/data02/pgpool/slave/pg_data –l /opt/postgresql/data02/pgpool/slave/log/pg.log start"
# Do nothing if standby goes down.
if [ $failed_node = 1 ]; then
exit 0;
fi
# Create the trigger file.
/usr/bin/ssh -T $new_master $trigger_command
exit 0;../bin/pgpool –n –d > ../log/pgpool.log 2>&1 & #-n表示取消后台模式,-d 表示打印调试信息。 bin/psql -U sequoiadb -d postgres -p 9999 #通过postgresql工具psql登录pgpool postgres=# show pool_nodes; node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay ---------+----------+------+--------+-----------+---------+------------+-------------------+------------------- 0 | centos01 | 7654 | up | 0.500000 | primary | 2 | true | 0 1 | centos01 | 4567 | up | 0.500000 | standby | 0 | false | 0 (2 rows) postgres=#
当手动关闭主库,等一会儿在重启主库,缺发现没有了主库,具体如下图13与所示:
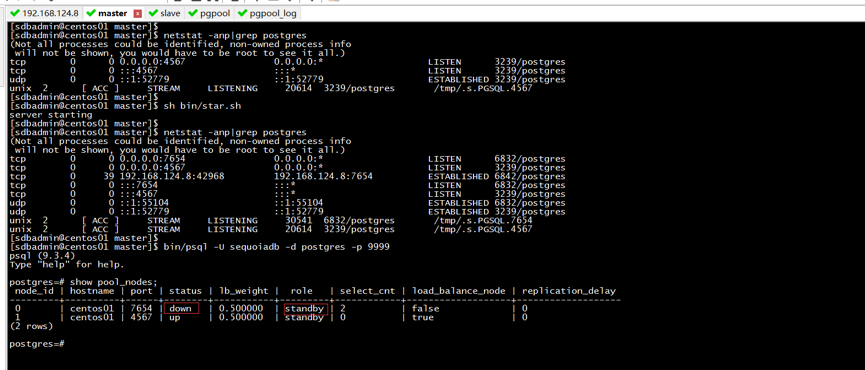
图13
目前还没有找到原因,实现在线恢复功能,即主节点挂后自动选主,且在主库关闭在重启过程中,有可能会出现原主库节点直接down掉,即status状态值为down,pgpool一致报无法找到主节点的异常,具体如图14所示:
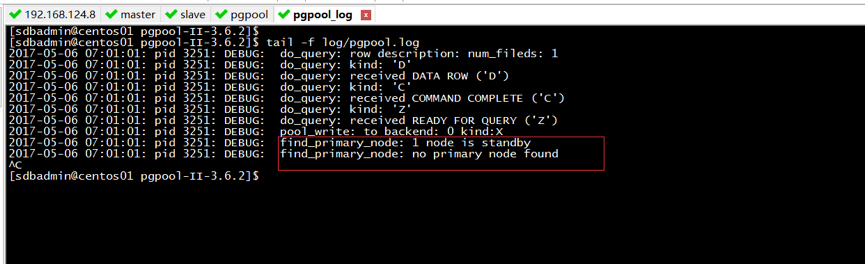
图14
可通过pgpool自带的工具pcp_attach_node进行处理,处理命令为:bin/pcp_attach_node -U pgpool -h centos01 -p 9898 -n 0 –d –W,具体则如图15:
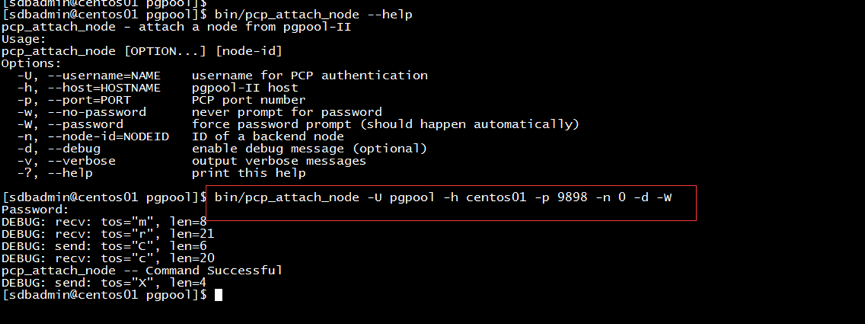
图15
该命令本身是可以把原主节点拉起并使其成为主节点的,执行后结果如图16所示:
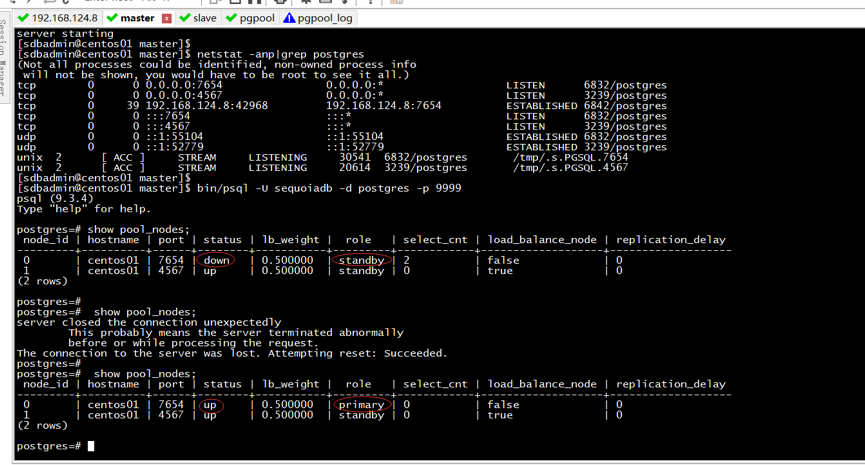
图16
使用PostgreSQL+SequoiaDB实现HA高可用架构,可以说为社区用户提供了一个更为简单的技术选择,使得SequoiaDB除了原生API之外,为社区开发者提供了SQL的接口。
当然,如果有更为复杂的需求或者更为庞大的业务数据需要管理,我们还是会推荐购买企业版的SequoiaDB,包括其中的SequoiaSQL分布式SQL引擎。







