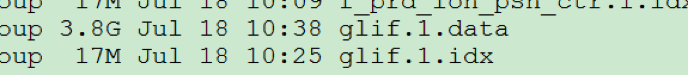SequoiaDB数据库经过了客户和第三方认证机构的大量场景测试,证明了SequoiaDB数据库能满足大数据场景下的性能要求。
本章用测试数据带大家来感受SequoiaDB数据库的强大性能,以及在反范式化和缓慢渐变维度中的性能。
本章主要测试目标有:
(1)SequoiaDB数据库支持大数据批量快速导入。将近200万每秒的入库速度,能在很短的时间内完成的数据迁移。
(2)SequoiaDB数据库支持大数据单表高并发实时查询。10亿数据量500并发的简单SQL查询,能达到平均23ms的响应速度。
(3)SequoiaDB数据库支持大数据多表关联查询。传统数据库无法执行的关联查询,SequoiaDB能以较快的速度执行出来。
表格1 硬件配置
服务器 | 3台 |
组件 | 配置 |
CPU | 64 CORE |
内存 | 256 GB |
磁盘 | 10 * 2TB |
网卡 | 10 Gb |
OS | Linux 64 位 |
测试环境是在表格1所示的硬件设备上,部署了一个30节点单副本的数据库集群。
测试项目: | 大数据多进程导入测试 |
测试目的: | 验证数据库在多进程同时发起导入时的写入性能 |
预置条件: | · 数据库集群运行正常 · 磁盘空间充足 · 测试数据均衡且分成多份,并且提前将数据文件存储在多台机器的磁盘上 |
测试过程: | 三台机器同时发起导入的命令,每台机器同时启动10个进程发起导入,并且每个进程又使用12个线程同时往数据库写入记录,所以对于数据库来说,共有3*10*12=360个线程同时发起导入任务。 耗时526秒:
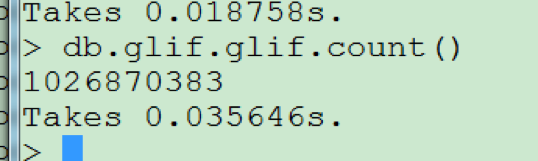
导入1026870383条记录:
数据库中某个节点的存储占用空间:
由于本次测试共使用30个节点来存储数据,所以数据库文件总大小为 3.8GB*30=114GB。
|
测试结果: | 数据导入平均性能为 1952225条记录/秒 峰值性能为2418525条记录/秒 数据压缩率 ((3.8GB*30)/349GB)*100%=32.665% |
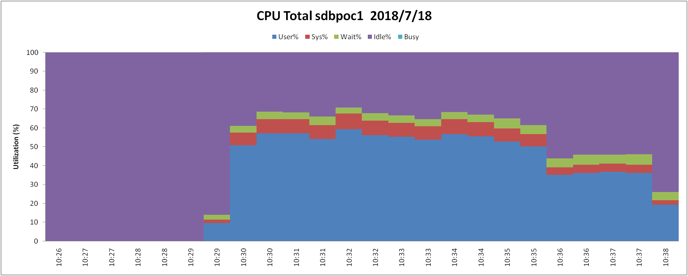
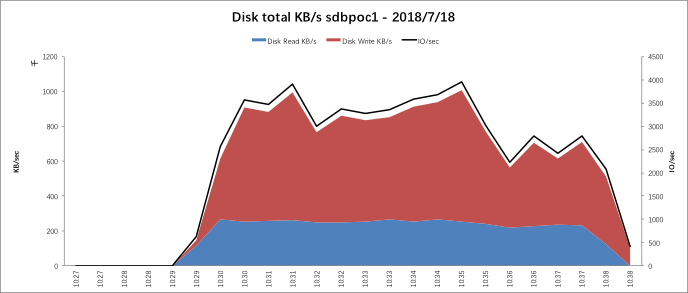
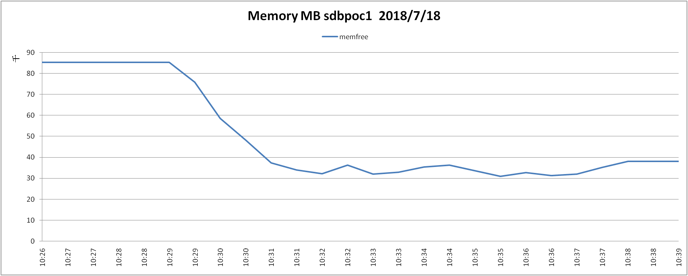
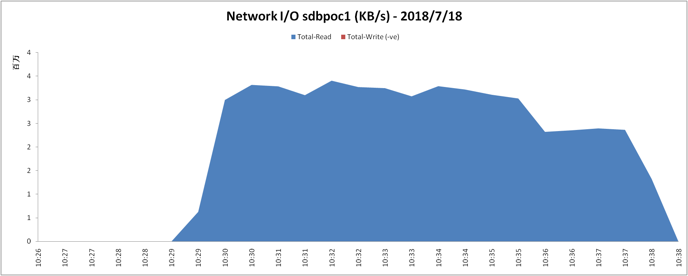
硬件性能数据信息: | 数据库集群各节点的nmon数据显示,各机器性能都还未到达瓶颈,但如果使用3副本则机器的硬件性能就基本饱和了。 其中一台机器的nmon性能监控如下: CPU使用情况:
内存使用情况:
网络使用情况:
|
测试项目: | 大数据高并发查询压力测试 |
测试目的: | 验证数据库支持高并发查询功能,并且查看在大数据高并发场景下数据库的执行效率,计划设计500并发用户进行测试 |
预置条件: | · SequoiaDB集群运行正常 · glif 表的数据量为 1026870383 条记录 · 测试对应的sql 为 “select * from FNSONLPH.GLIF where substr(key_1,5,5) = '???' and GLIF_REFERENCES=’??? ’” · 每个场景测试时间为 30 分钟 |
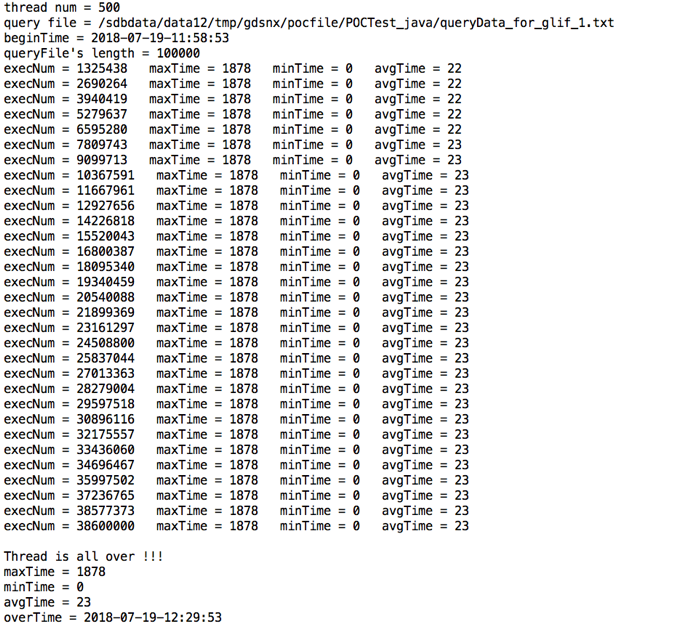
测试过程: | 启动500个并发数的数据操作程序,记录程序执行效率:
|
测试结果: | 共执行了38600000次查询。 最大响应时间:1.878 Sec 最小响应时间:1 ms 平均响应时间:23 ms |
测试项目: | 大数据多表关联查询测试 |
测试目的: | 验证数据库对复杂关联查询的支持。 验证数据库对复杂sql 查询结果的保存速度 |
预置条件: | · 服务器运行正常 · SequoiaDB集群运行正常 · f_prd_dep_psn_sv_acct 数据量为104689660条记录 · glif 数据量为 1026870383 条记录 |
测试过程: | 执行一下sql命令,记录数据库执行效率: insert into test2 select * from ( select * from f_prd_dep_psn_sv_acct ) a inner join ( select GLIF_REFERENCES,sum(lcy_amt) as lcy_amt,sum(fcy_amt) as fcy_amt from glif where substr(GL_CLASS_CODE,9,4) ='6021' group by GLIF_REFERENCES ) b on substr(a.acct_no,1,16) = b.GLIF_REFERENCES; |
测试结果: | 执行耗时为439.7秒 Sql执行时间截图
Sql结果集截图
|