在现代的企业运营中,除了是和竞争对手比拼产品的功能、市场的推广能力外,还需要和竞争对手比拼业务数据的挖掘能力,所以现在越来越多的企业对业务数据的重视程度越来越高,并且在数据分析和数据挖掘方面投入更多的资源,希望能够在此领域领先于竞争对手,从而占据商业竞争中更加有利的地位。
而在数据分析、数据挖掘领域,数据量的积累往往是最基础的条件,要想从数据分析中得出更加符合实际的业务价值,或者是更加准确的市场预测,都需要从海量的数据中分析得出。
同时,为了能够让更多的业务人员参与到数据分析、数据挖掘中来,那么过去高门槛的分析工作必定要大大降低准入门槛,从而能够让懂业务但是不精通编程开发的一线人员参与进来,以更加符合企业业务特点的方式分析数据。
SequoiaDB是国内唯一款具有完全自主知识产权的分布式数据库,已经被成功应用在多家世界500强企业的生产环境上。SequoiaDB利用自身的技术优势,能够为超过PB级别的数据提供毫秒级响应的数据操作。
而在数据展现图形化领域里,国产的SmartBI是一款出色的BI报表工具,它能够为用户提供简单、方便、直观的数据分析操作体验,能够很好地降低了数据分析、数据展现的开发门槛,让更多的业务人员参与到数据分析的工作上来,为企业得出更加有价值的分析结果和预测数据贡献自己的一分力量。
Linux环境
资源 | 详细配置 |
CPU | 2CORE |
内存 | 4GB |
磁盘 | 100GB |
网络 | 1Gb |
操作系统 | Ubuntu desktop 64位版 |
软件版本介绍
产品名称 | 版本 | 说明 |
SequoiaDB | 2.8.1 | SequoiaDB企业版本 |
Smart BI | 7.0 | 社区版本 更新时间2017-07-18 19:22:31 |
Tomcat | 7.0 | Apache版本 |
Spark | 2.1.0 | Apache版本 |
JDK | 1.7 | 64位 |
MySQL | 5.7.18 | 社区版本 |
Smart BI软件准备
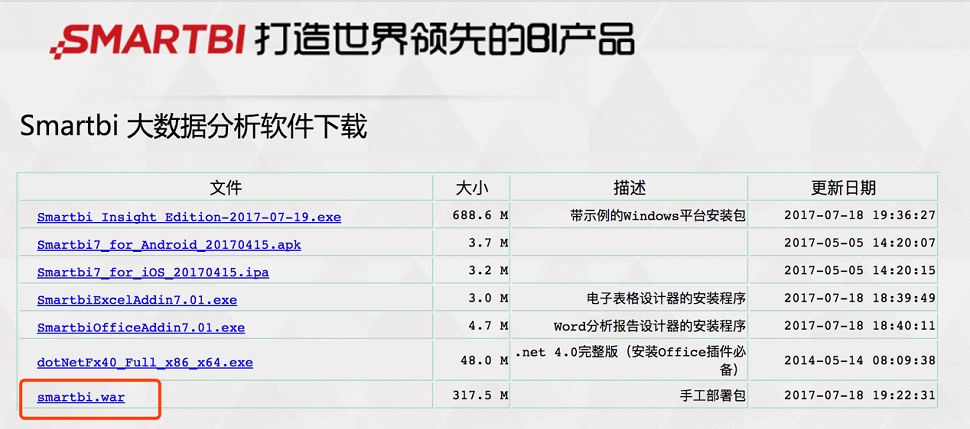
软件下载
用户可以通过Smart BI 官网下载它的安装包。

Smart BI安装包分为两大类,一种是企业版本,另外一种是社区版本,本次演示教程采用的是社区版本。
Smart BI的社区版本在基本功能上没有太多的限制,但是限制了服务的并发数以及一些高级功能,但是并不影响作者介绍如何通过Spark SQL将SequoiaDB 和 Smart BI进行技术对接。
Smart BI官网下载的链接为
http://download.smartbi.com.cn/insight/

用户可以选择exe格式和war格式的文件进行下载,本次教程将采用war包部署方式进行介绍。
授权文件下载
由于Smart BI软件的限制,即使用户是使用社区版本,也需要向Smart BI官方基于机器的MAC地址申请License文件。
Smart BI申请License 文件的方式也比较简单,首先用户需要在Smart BI上注册一个账号,注意填写好个人邮箱地址。

然后查看个人机器的mac地址,如果是windows机器,查看的命令如下:
ipconfig /all
屏幕输出的物理地址信息即为当前机器的mac地址
如果是linux环境,查看的命令如下:
ifconfig -a
屏幕输出的HWaddr信息即为当前机器的mac地址信息。
Smart BI官网申请License 文件地址
http://www.smartbi.com.cn/myaccount.php

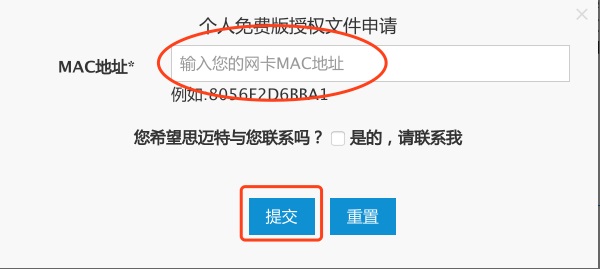
用户正确填写个人机器的mac地址信息后,点击“提交”,一般在5-10分钟内Smart BI官网会将对应的License 文件发送到用户注册的邮箱上。用户只需要提前下载好该License 文件即可。
启动Smart BI服务
本教程使用Tomcat作为部署Smart BI的中间件,如果用户使用其他的中间件进行部署,可以根据实际情况对启动Smart BI步骤进行修改。
假设Tomcat 的HOME目录为/root/software/tomcat-7.0.78。
用户首先将提前下载好的smartbi.war 文件拷贝到/root/software/tomcat-7.0.78/webapps目录下。
用户可以根据Smart BI官网上的介绍,对Tomcat的catalina.sh配置文件进行修改
vi /root/software/tomcat-7.0.78/bin/catalina.sh
Smart BI官网建议用户对JAVA_OPTS的jvm参数进行调整
作者根据自身的机器配置,修改后保存退出。
JAVA_OPTS="$JAVA_OPTS -Dfile.encoding=GBK -Duser.region=CN -Duser.language=zh -Djava.awt.headless=true -Xms2048m -Xmx2048m -XX:MaxPermSize=512m"

启动Tomcat服务,由于Tomcat在默认情况下Service端口为8080,所以用户只需啊检查机器的8080端口是否被占用即可判断Tomcat是否已经正常启动。
/root/software/tomcat-7.0.78/bin/startup.sh
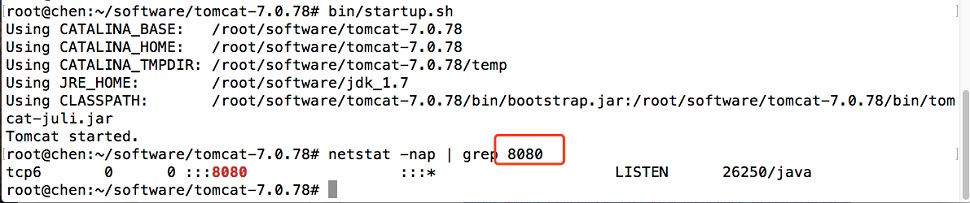
用户可以通过/root/software/tomcat-7.0.78/logs/catalina.out日志文件确认Smart BI服务已经启动。
如果日志文件中显示以下内容,则代表启动成功
七月 26, 2017 1:02:26 下午 org.apache.catalina.startup.HostConfig deployDirectory
信息: Deploying web application directory /root/software/tomcat-7.0.78/webapps/manager
七月 26, 2017 1:02:26 下午 org.apache.catalina.startup.HostConfig deployDirectory
信息: Deployment of web application directory /root/software/tomcat-7.0.78/webapps/manager has finished in 48 ms
七月 26, 2017 1:02:26 下午 org.apache.coyote.AbstractProtocol start
信息: Starting ProtocolHandler ["http-bio-8080"]
七月 26, 2017 1:02:26 下午 org.apache.coyote.AbstractProtocol start
信息: Starting ProtocolHandler ["ajp-bio-8009"]
七月 26, 2017 1:02:26 下午 org.apache.catalina.startup.Catalina start
信息: Server startup in 30502 ms
配置Smart BI Server
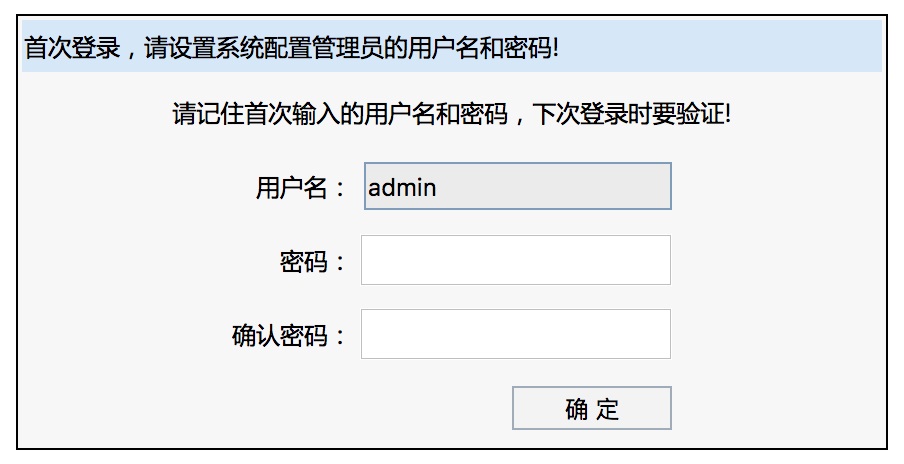
Tomcat服务启动后,用户可以通过浏览器登录Smart BI的知识库配置页面进行License认证。
假设用户启动Tomcat的机器IP地址为10.211.55.3,则Smart BI的知识库配置网址为
http://10.211.55.3:8080/smartbi/vision/config
用户第一次登录,需要输入初始化的管理员密码,作者为了简单起见设置初始密码为configadmin。
配置MySQL作为Smart BI知识库
首先检查MySQL是否支持GBK字符集,因为作者在测试过程中发现,Smart BI在知识库字符集设置上,只能够支持GBK,如果不注意设置为UTF8则后面的很多配置操作会失败。
MySQL检查字符集的命令
show character set;
如果支持gbk字符集,则会显示
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
创建一个gbk字符集的database
create database if not exists smartbi DEFAULT CHARACTER SET gbk COLLATE gbk_chinese_ci;
查看一下smartbi的database字符集是否为gbk
show create database smartbi;
显示如下信息

用户继续在http://10.211.55.3:8080/smartbi/vision/config页面上设置以MySQL作为知识库。
用户应该正确填写“服务器地址”,该拦填写部署MySQL服务的IP地址和MySQL的端口号;“数据库名”应该填写上一步骤在MySQL中创建的database名字;“用户名”和“密码”则为MySQL服务的登录方式。
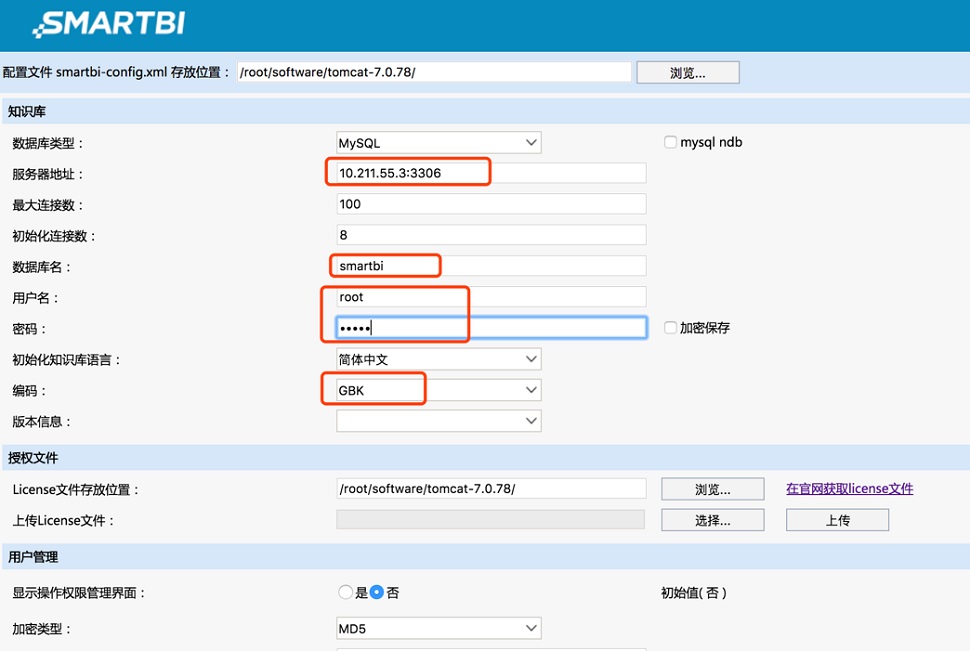
用户再在“授权文件”选项上,点击“选择”按钮,在磁盘上选择已经申请到的License文件,再点击“上传”按钮,完成License文件的认证。

用户设置好相关的配置后,点击页面末尾的“测试知识库连接”按钮,验证设置是否正确。
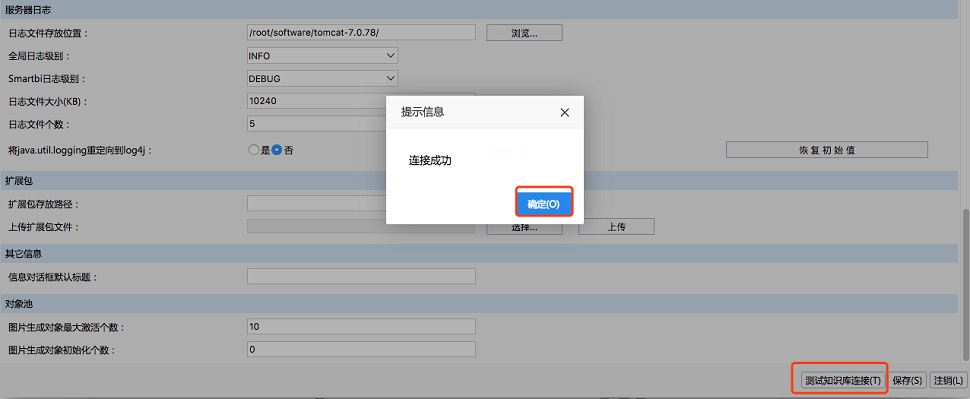
如果配置正确,点击“保存”退出,并且关闭Tomcat服务器。
关闭Tomcat命令
/root/software/tomcat-7.0.78/bin/shutdown.sh ;
SequoiaDB 对接 Spark SQL
SequoiaDB和Spark SQL的对接方式只要用户将sequoiadb.jar和spark-sequoiadb.jar两个驱动程序分别拷贝到Spark SQL运行的Worker机器上,并且为每台机器的Spark 配置文件spark-env.sh 添加SPARK_CLASSPATH参数,例如:
SPARK_CLASSPATH="/media/psf/mnt/spark-sequoiadb_2.11-2.9.0-SNAPSHOT.jar:/media/psf/mnt/sequoiadb-driver-2.9.0-SNAPSHOT.jar"
详细对接步骤可以参考:
http://doc.sequoiadb.com/cn/SequoiaDB-cat_id-1432190712-edition_id-0
用户在为每台Spark 服务器设置好后,应该选择一台Spark 机器启动一个thriftserver 服务,假设Spark HOME 目录为/root/software/spark-2.1.0-bin-hadoop2.7
启动方式如下:
/root/software/spark-2.1.0-bin-hadoop2.7/sbin/start-thriftserver.sh --master spark://10.211.55.3:7077
假设SequoiaDB已经存在一个foo.bar的集合,并且里面包含两条记录。

用户可以通过beeline客户端为Spark SQL创建SequoiaDB的映射表。
启动beeline的命令如下
/root/software/spark-2.1.0-bin-hadoop2.7bin/beeline -u "jdbc:hive2://10.211.55.3:10000"
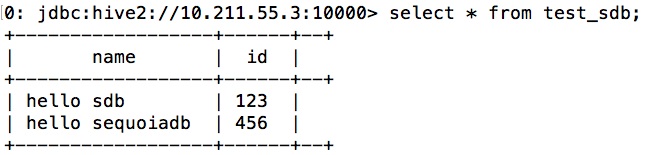
用户在beeline客户端上创建SequoiaDB映射表的命令如下:
CREATE TABLE test_sdb(name string, id int) USING com.sequoiadb.spark OPTIONS ( host 'chen:11810', collectionspace 'foo', collection 'bar');
通过beeline检查SequoiaDB的真实数据。
配置Smart BI驱动
由于Smart BI在默认情况下,并不能直接和Spark SQL进行通信,但是它支持Hadoop Hive2的JDBC访问接口,所以用户只需要将Spark SQL的开发驱动拷贝一份到Smart BI的libs目录中即可。
cp -rf /root/software/spark-2.1.0-bin-hadoop2.7/jars/* /root/software/tomcat-7.0.78/webapps/smartbi/WEB-INF/lib/
重启Smart BI
用户为Smart BI配置Spark SQL的驱动程序后,就可以对Tomcat进行重启,由于之前的步骤中,只对Tomcat服务进行了停止,所以用户只要重新启动Tomcat即可。
/root/software/tomcat-7.0.78/bin/startup.sh ;
初始化管理员登录密码
用户在按照以上步骤设置好Smart BI和SequoiaDB对接之后,就可以浏览器上登录http://10.211.55.3:8080/smartbi/vision/index.jsp地址,开始配置Smart BI的连接资源。
用户需要先登录Smart BI的管理页面。用户名默认为“admin”,密码默认为“manager”。

用户第一次登录后,需要设置新的管理员密码,作者为了简单起见,将密码设置为“admin”。

用户在登录Smart BI的页面后,会咨询“是否需要执行检查”,作者为了简单起见,选择“否”。

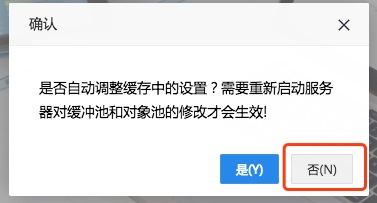
同时Smart BI会继续咨询“是否自动调整缓存设置”,作者为了简单起见,选择了“否”。
然后用户在“定制管理”按钮下,选择“数据管理”,再在“数据源”按钮上右击,在“新建”选项上选择“关系数据源”
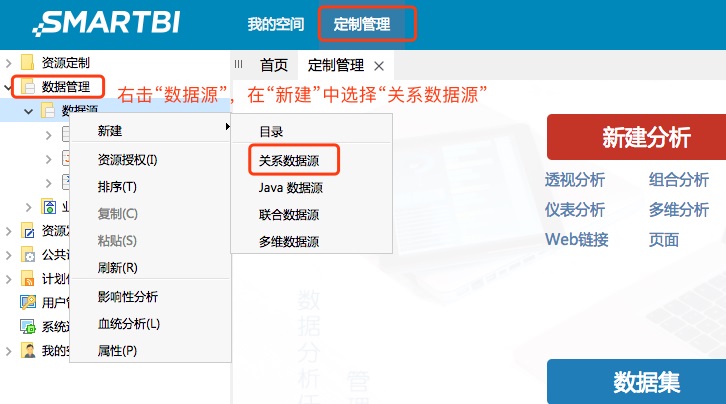
用户在配置页面上依次填写“名称”、“别名”、“驱动程序类型”、“连接字符串”参数。
用户应该要注意的,“名称”和“别名”用户可以随意指定,但是“驱动程序类型”应该选择“Hadoop_Hive”,并且“连接字符串”按照用户自己环境的不同进行填写。
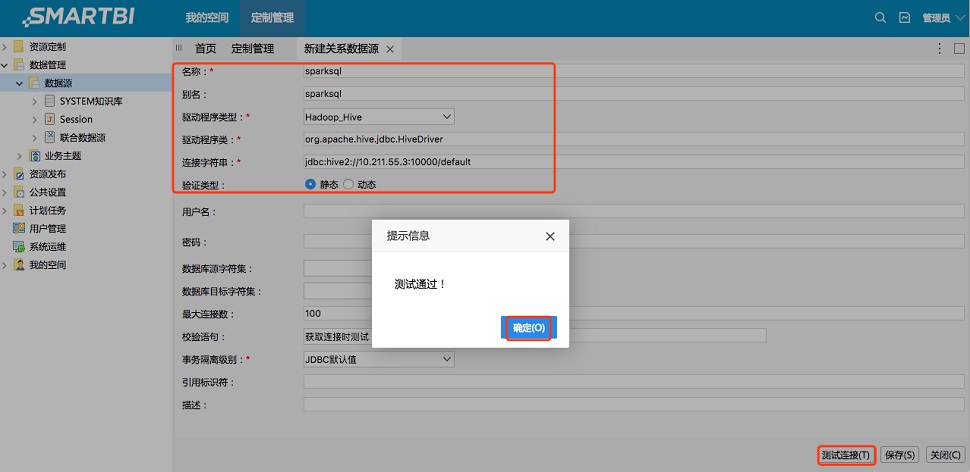
用户填写无误后,点击“测试连接“按钮,测试配置是否正确。如果显示”连接通过“,代表配置正确,用户直接点击”保存“即可。
验证Spark SQL数据源
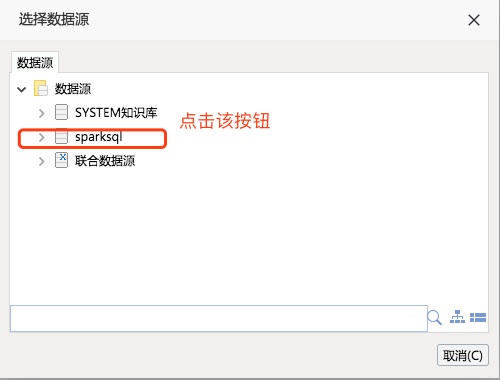
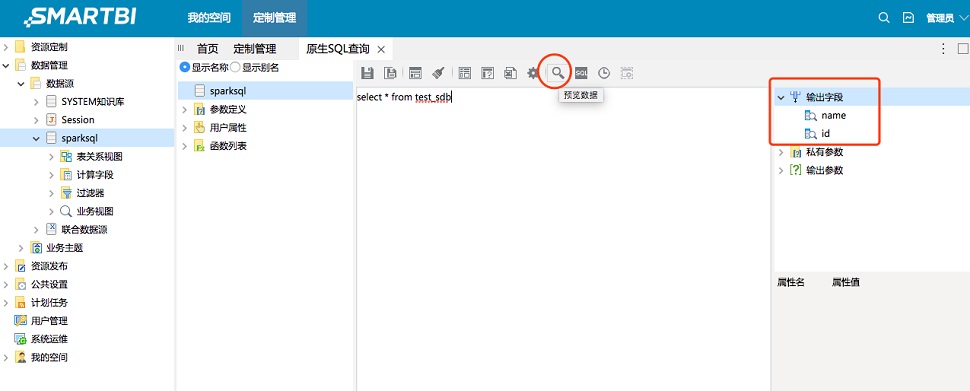
用户可以继续在刚才的页面上点击“原生SQL查询”按钮。

在下级页面上点击刚才配置的sparksql数据源。
用户可以在新的页面上直接编辑SQL命令,例如
select * from test_sdb
然后用户在右侧的导航栏上右键“输出字段”按钮,选择“检测输出字段”,检查Smart BI是否能够正确识别SQL命令的输出字段。
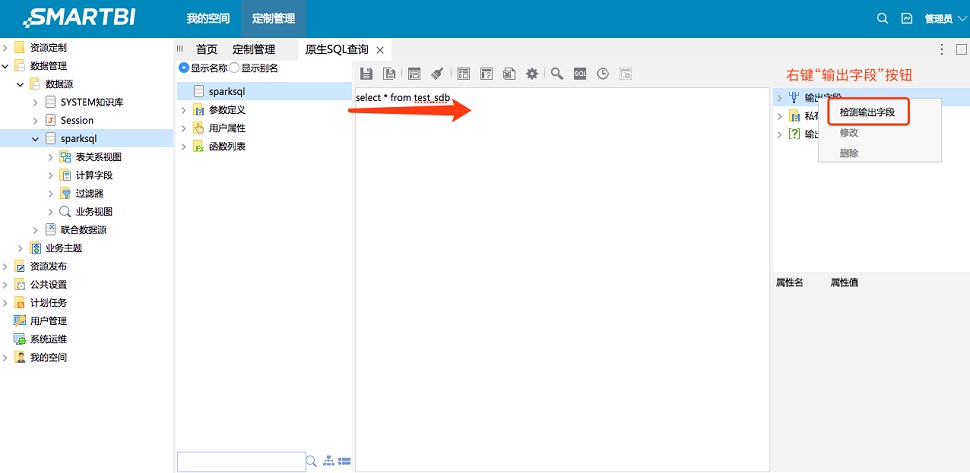
用户通过测试,可以发现Smart BI可以正确识别Spark SQL中test_sdb 表的表结构。用户也可以点击“预览数据”的按钮,检查Smart BI是否能够正确从Spark SQL中获取记录。
用户在预览数据界面上,可以通过点击“刷新”按钮查看最新的数据。
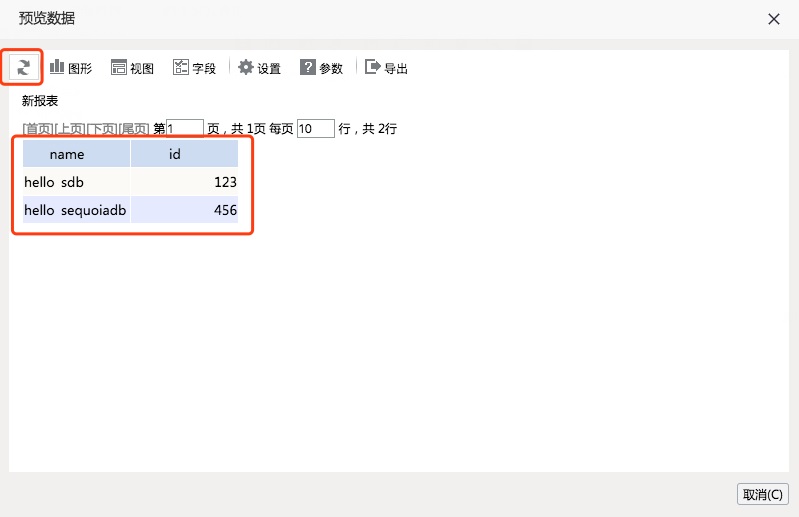
通过以上测试步骤,基本可以确定Smart BI和Spark SQL能够实现无缝对接,从而间接完层Smart BI和SequoiaDB的技术整合。
用户通过本篇SmartBI和SequoiaDB+SparkSQL的对接教程,能够快速掌握如何安装部署社区版的SmartBI,以及如何配置SmartBI的知识库。还有用户通过对接教程的说明,也可以了解SmartBI和SequoiaDB的对接原理。SequoiaDB和SparkSQL的整合,使得SequoiaDB的海量数据能够直接被SparkSQL所使用,并且得益于SparkSQL的分布式计算优势,未来复杂的SQL计算和数据分析的计算时间能够比以前使用关系性数据库大大降低,为企业的数据分析提供了良好的技术保障。






