随着移动互联网的飞速发展,海量非结构化数据的应用场景日益增多。巨杉数据库基于原生分布式技术,采用多模数据湖,提供了存算分离、海量数据存储、多模数据、高并发访问等能力,为银行的非结构化数据治理提供了内容管理平台的解决方案。结合AI技术的推动,进一步探索非结构化数据的价值释放,从而提高数据处理的效率和准确性。在实践中,根据不同的客户发展阶段和业务特性,巨杉数据库深入剖析客户的业务需求,基于多模数据湖在结构化数据与非结构化数据的融合处理方向上提供了成功的解决方案,并积极探索在全量数据场景下,如何推动银行业数据管理的智能化进程。
在股份制银行的内容管理平台场景中,巨杉数据库已经落地了近百亿条、百TB级数据的稳定支撑能力,提供PB级数据场景下的高并发访问。
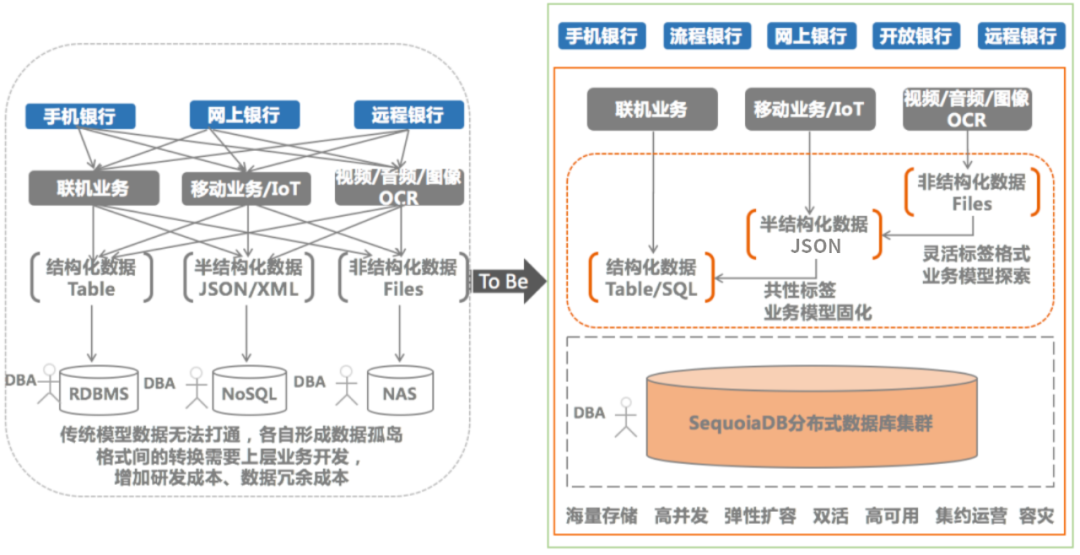
近些年,伴随着移动互联网飞速发展,基于手机银行、移动营业厅、网上银行、远程银行、开放银行、流程银行等业务渠道,在各类创新的业务有效地提升了客户体验的同时,也为银行带来了海量的电子票据、图像、音视频等非结构化数据。非结构化数据从原来仅仅用于数据的电子化存档,上升成为业务交易链条中的关键环节,传统内容管理平台基于Documentum、FileNet、IBM CM、SAN存储等架构的管理系统随着数据量爆发式增长之后,逐渐面临查询性能慢、实时性不高、并发处理性能急速下降、扩容困难等问题。SequoiaDB基于原生分布式技术构建的多模数据湖,实现了资源池化,结构化和非结构化等多模数据海量存储,多中心容灾等技术能力,为银行提供一体化的非结构化数据存储平台,以及包含批次管理、版本管理、生命周期管理、标签管理、模糊检索、断点续传等丰富的元数据管理机制。SequoiaDB分布式数据库满足银行的灵活按需扩容、低成本海量存储、高并发低延时访问、异地分布式架构、高效整合、多中心高可用、跨中心容灾等需求,有效解决了平台高并发低延时、数据管理、弹性扩容、双活、高可用、集约运营、容灾等问题,实现非结构化数据统一管理、数据全量在线、降低风险和减少成本等目标。股份制银行内容管理平台提供各类业务流程化处理的影像非结构化数据及相关元数据的存储,将原本分散的数据进行统一集中的管理,原内容管理平台使用Documentum、 FileNet架构,随着数据量增长,平台面临性能急速下降、扩容困难、查询并发低、实时性不高等问题。不适用于面向客户、高并发、高实时场景。同时由于数据量较大,存在容灾数据恢复周期长的问题。
新内容管理平台基于SequoiaDB分布式数据库进行规划建设。
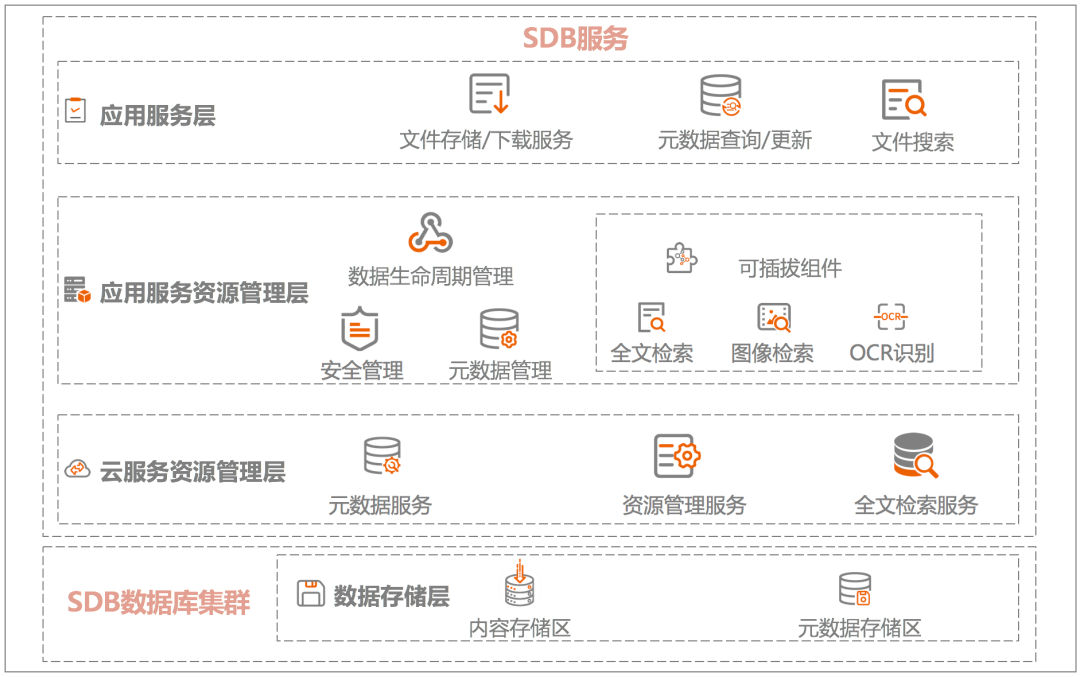 图2 SequoiaDB的内容管理能力以基于Spring-Cloud框架的微服务架构为基础,基于SequoiaDB构建的内容管理平台解决方案通过可插拔组件与可配置流程,允许用户自由定义不同数据存储容器中对象文件的处理方式。譬如,对于合同扫描件类型的业务,系统可以将OCR文字识别模块直接加入非结构化文件处理流程,使得所有写入该容器的合同自动进行文字识别处理,并直接支持针对其内容的全文检索能力。
图2 SequoiaDB的内容管理能力以基于Spring-Cloud框架的微服务架构为基础,基于SequoiaDB构建的内容管理平台解决方案通过可插拔组件与可配置流程,允许用户自由定义不同数据存储容器中对象文件的处理方式。譬如,对于合同扫描件类型的业务,系统可以将OCR文字识别模块直接加入非结构化文件处理流程,使得所有写入该容器的合同自动进行文字识别处理,并直接支持针对其内容的全文检索能力。
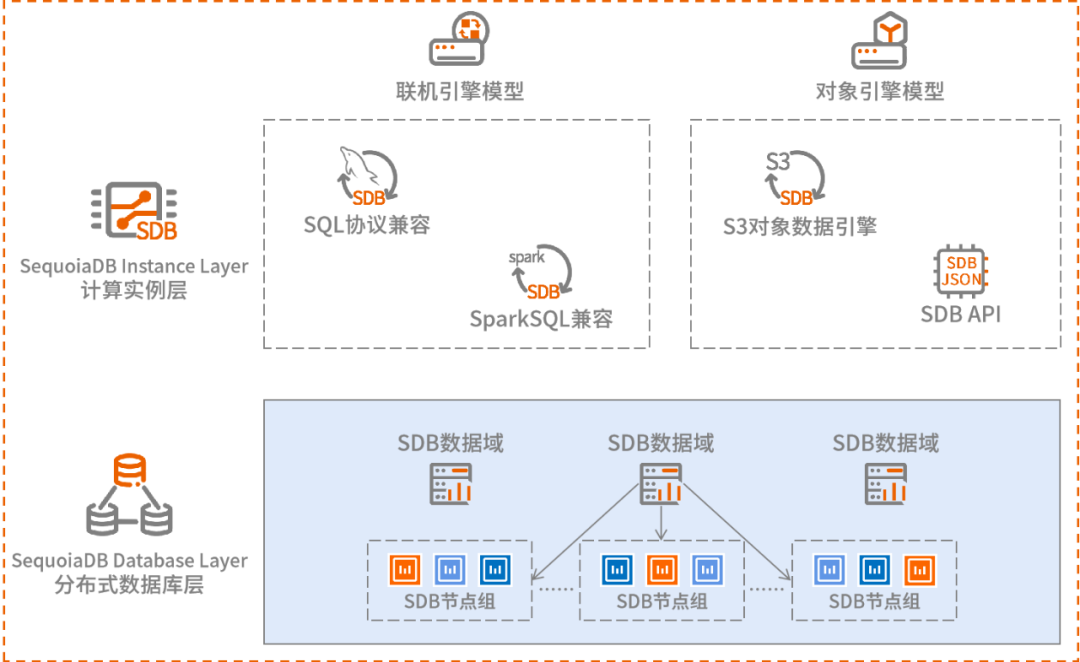
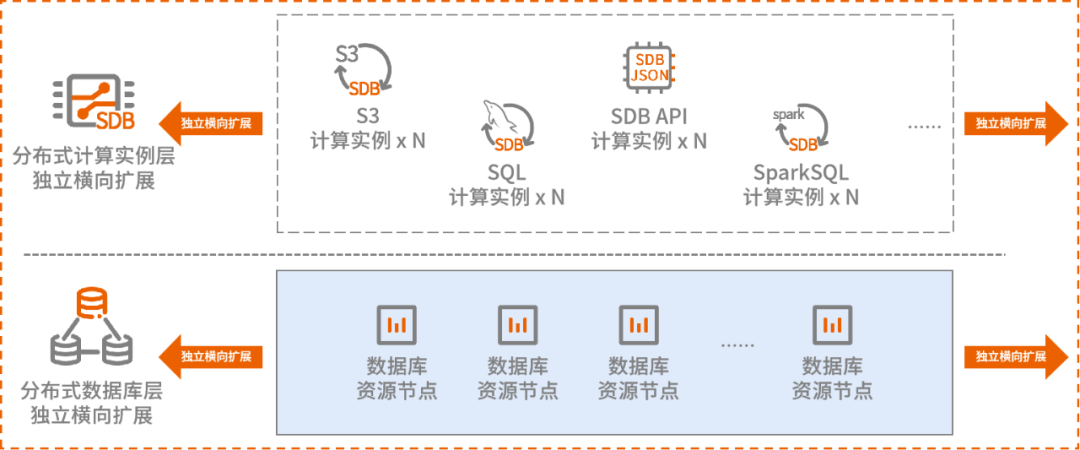
非结构化数据治理:双引擎技术,存算分离原生分布式架构
引擎级多模:兼容SDB API、SQL、S3对象数据引擎接口
高性能,低成本:全量内容数据持续在线,多策略分区管理、分域缓存,资源池化的存储引擎层,提升海量数据管理效率及处理性能,TCO为传统ECM方案1/3
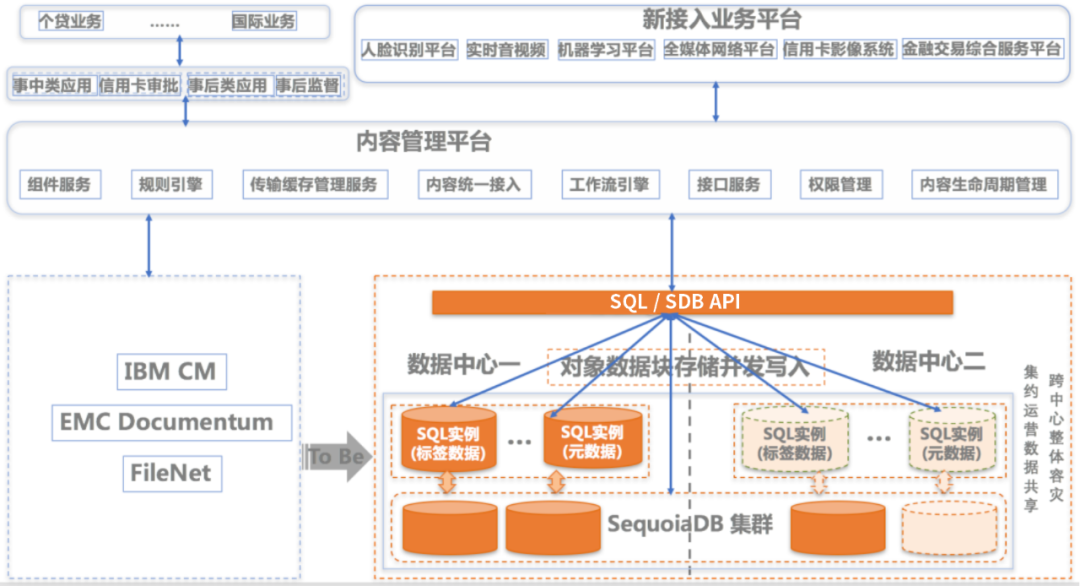
股份制银行基于SequoiaDB构建的内容管理平台建设规划如下:
各厂商的内容管理平台(如:信雅达、方正国际、清华紫光等)通过调用巨杉数据库提供的标准SQL API,与SequoiaDB分布式数据库进行交互,实现可按需横向扩展的元数据、对象数据、标签数据的跨中心一体化管理。平台采用SequoiaDB巨杉数据库进行数据的存储与统一管理。巨杉数据库是国产分布式数据库,原生支持分布式集群模式,基于多模数据湖,“计算与存储分离”架构满足客户海量数据弹性存储、横向弹性扩容、亿级记录情况下的低延时高并发的数据查询等需求,多副本机制提供数据高可用能力,多中心双活提升数据读写性能以及灾备能力,可以实现打通不同业务类型、不同数据类型之间的技术壁垒,实现交易分析一体化、流批一体化、多模数据一体化,充分满足客户在海量数据下高并发低延时查询、按需的节点扩容、持续稳定运行等需求。巨杉数据库提供存算分离、资源隔离、多副本一致性以及多模数据(结构化、半结构化、非结构化数据)能力。巨杉数据库基于存算分离架构,实现存储与计算能力的横向弹性扩展。
本方案采用集群方式部署,消除单点问题,提供高可用、高并发性能。
除此之外,系统还拥有丰富的平台能力,如下:
数据管理:数据权限管理、对象数据版本控制、历史版本回溯等功能,数据生命周期管理、冷热数据分层存储,提升数据治理水平
系统自主可控,支持信创:支持x86、ARM,核心代码可控
容灾:同城双活、两地三中心、三地五中心,RPO=0,RTO<15秒
此改造方案已经成功落地实施,并帮助客户实现系统性能提升。
当今金融行业面临着越来越多的数据管理和运营的挑战,结合AI技术和多模数据湖的优势,通过结构化数据与非结构化数据的融合处理,以及高并发访问与统一集中运营的能力,内容管理平台已经成为了股份制银行业务处理的重要工具,可以更加高效地管理和利用大量数据,从而提高业务运营效率和客户服务水平。未来,巨杉数据库将继续不断创新,打造更加安全、稳定、可靠的数据库系统,深耕数据沃土,释放全量数据价值,持续助力金融行业客户信息化创新。