导读:

巨杉数据库农信典型客户案例

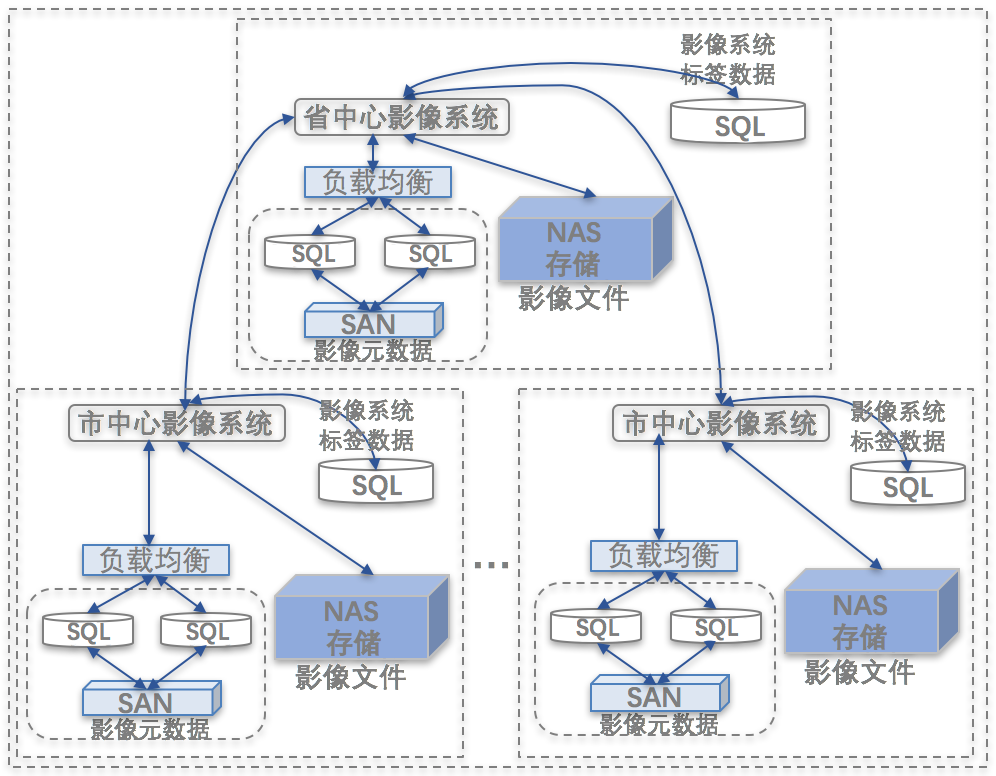
省级农信内容管理平台基于巨杉数据库多级缓存数据服务,实现多法人、多中心缓存系统的数据共享能力及高并发访问能力。在省级农信的内容管理平台场景中,已经落地了近几十亿条、超百TB级数据的稳定支撑能力,提供多法人、多中心缓存数据场景下的数据共享及高并发访问。

背景
需求痛点
业务痛点
异地分布式架构整合难:各地农信独立法人机构,数据中心本地化建设,难统一
网络差:地市与省农信数据中心间网络情况复杂,性能差
扩容难:业务系统烟囱式构建,当数据量激增,这种单点架构下系统横向扩容难
监管难:数据单点系统部署,无双活机制,无法全量数据在线满足监管查询需求,数据安全性低
为了更好的适应业务发展的挑战,增强市场的竞争力,急需建设各分社与总中心联动的内容缓存系统,以满足分社本地内容文件的管理需求,提高相关业务系统的整体性能,同时通过数据迁移、清理机制将所有的内容管理元数据信息存放在省中心,实现全社影像文件元数据统一纳管,非结构化数据异地存放,最大化节省数据中心之间的带宽。

改造方案
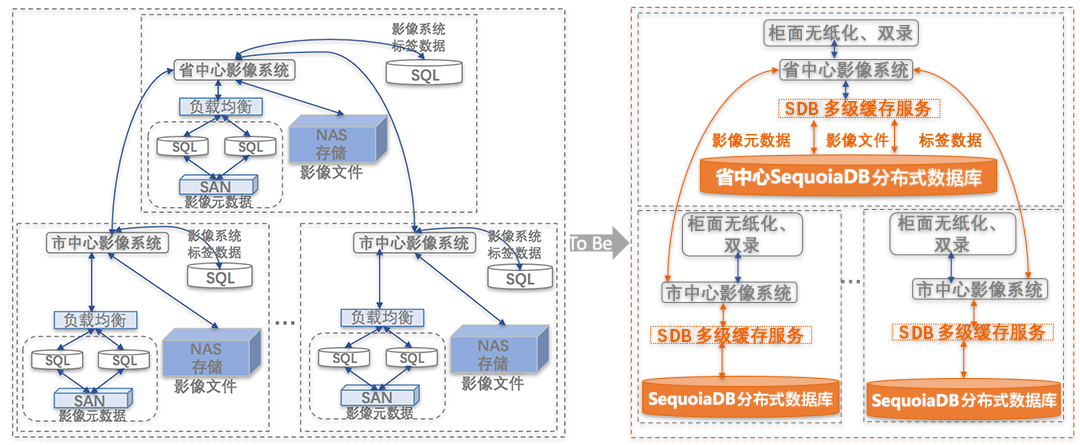
农信内容管理平台是基于SequoiaDB分布式数据库集群进行规划的,改造设计框架如图2所示。
农信内容管理平台改造方案
改造方案优势
非结构化数据统一管理:省与地市农信影像元数据、影像数据统一管理、访问
高并发低延时:高并发、毫秒级响应
海量存储:PB级数据管理、弹性扩容、灵活数据分片
实时在线服务:跨数据中心统一数据存储,实时数据在线访问
改造方案设计:
各厂商的内容管理平台(如:信雅达、大连同方软银)通过调用巨杉数据库提供的多级缓存服务,与SequoiaDB分布式集群进行交互,实现可按需横向扩展的影像元数据、影像文件、标签数据的跨中心一体化管理。
影像元数据统一存储于省农信数据中心SequoiaDB分布式数据库,以便为地市农信分数据中心提供数据查询服务;地市农信影像数据本地数据中心存放,通过SequoiaDB多级缓存服务数据迁移机制将影像数据迁移存放于省农信内容管理平台,实现跨中心数据访问、统一存储和管理。
巨杉数据库原生分布式架构:
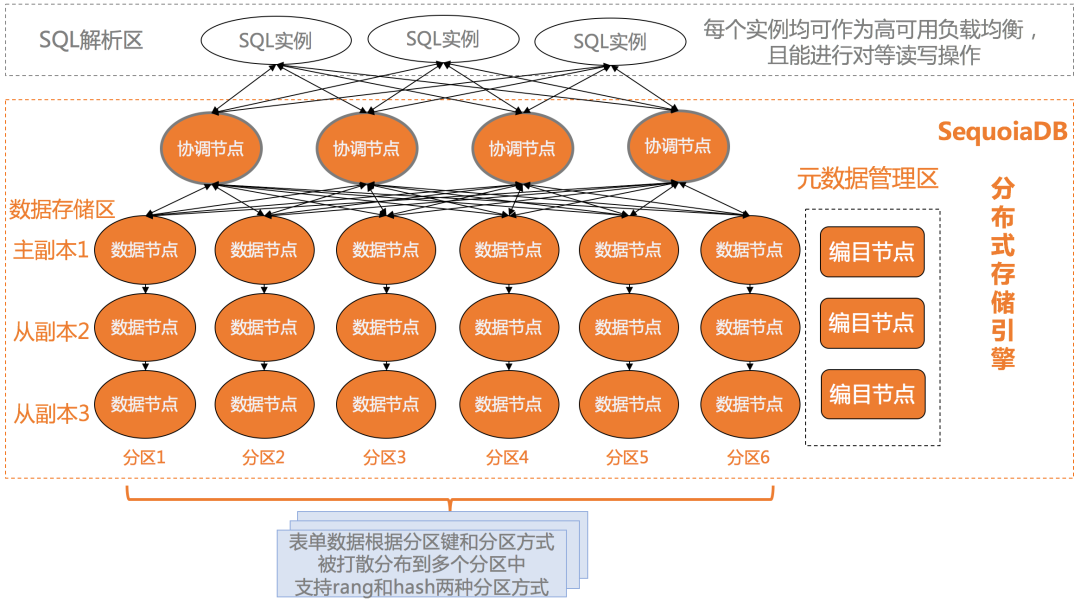
图3 SequoiaDB巨杉数据库原生分布式架构
SequoiaDB作为分布式数据库,由数据库存储引擎与数据库实例层架构组成。其中,数据库存储引擎是数据存储的核心,负责提供整个数据库的读写服务、数据的高可用与容灾等全部核心数据服务能力。
数据库实例模块则作为协议与语法的适配层,支持结构化、半结构化、非结构化数据的统一存储,提供S3对象数据引擎接口和兼容JSON、SQL接口。
SequoiaDB分布式数据库架构优势
无缝迁移:用户可以通过创建不同类型的数据库实例,使应用程序从传统数据库进行无缝迁移,大幅度降低应用程序开发者的学习成本。
应用透明:每个实例中的数据在底层是存放在一个机器还是十个机器,对上层应用来说完全透明不需要感知。
引擎级多模:兼容SDB API、SQL、S3对象数据引擎接口
高性能,低成本:全量内容数据持续在线,多策略分区管理、分域缓存,资源池化的存储引擎层,提升海量数据管理效率及处理性能,TCO为传统ECM方案1/3
除此之外,系统还拥有丰富的平台能力,如下:
系统能力
集约运营:多模数据统一管理
数据管理:数据权限管理、对象数据版本控制、历史版本回溯等功能,数据生命周期管理、冷热数据分层存储,提升数据治理水平
服务节点高可用:节点无状态,多节点提供服务
多中心:跨中心部署,逻辑隔离、物理隔离
多索引:不同字段、维度创建索引,精确查询
数据高可用:多副本机制
满足监管要求:数据全量在线,数据安全
系统自主可控,支持信创:支持x86、ARM,核心代码可控
容灾:同城双活、两地三中心、三地五中心,RPO=0,RTO<15秒
此改造方案已经成功落地实施,并帮助客户实现系统性能提升。

结束语
未来,巨杉数据库基于多模数据湖与AI技术的进一步深化,所构建的内容管理平台可以更好地处理和利用非结构化数据,实现智能化客户服务和风险管理,提高业务运营效率和创新能力,不仅为农信银行提供了更多的商业机会和竞争优势,也为金融行业的数字化转型和升级注入了新的活力和动力。






