巨杉数据库SequoiaDB从「多模数据湖」、「实时数据湖」发展到「湖仓一体」架构,为客户提供「数据核心」所需的全量数据存储,实时对客服务,及基于统一数据源的分析能力,充分激活客户的离线数据。当中,「实时数据湖」对比Hadoop架构,除了海量数据存储能力外,还提供高并发的实时对客服务能力。
随着数字化转型的深入,以及金融科技的不断发展,金融银行业的应用系统正在经历从功能型系统向数据型系统转型,金融企业越来越认识到全量数据的价值所在。目前,国内个别大型银行已经完成数据湖的初期建设,实现以 “一湖两库”(数据湖+数据仓库+信息库)为核心的大数据2.0架构,提升大数据服务能力。
通过建立数据湖对全量数据进行沉淀和积累,打通各业务系统之间的数据共享、拓宽应用范围、加速业务探索、释放数据价值,从而为企业发展注入新动能,已成为金融银行业的迫切需要。国内各银行也认识到数据湖的潜在前景,正在积极地进行着技术探索和选型储备。近几年数据湖的探索和落地过程中,企业对于数据的实时性越来越重视。一方面要求全量数据在湖内即时可用,一方面更强调数据入湖的高时效性:面向客户:多源实时数据的共享,将带来更高的用户体验,如移动端客户资产视图,将来自核心、信用卡、理财、贵金属交易等数十个业务系统的资产数据实时展现,为客户提供统一、快捷的服务入口。
面向营销:通过实时计算,可实现更精准的客户画像及营销决策,从而提升获客能力。如客户资产AUM,基于全量数据进行实时的、复杂的多维度指标计算,从而提升客户评级、费率优惠等环节的营销效果。
面向监管及风控:全量实时数据不但为监管、司法部门、合规部门提供高保真、即时可用的数据准备,而且能够加速风控模型计算,提升风控时效和准确性,从而保障资产安全。还有实时反欺诈,可基于实时数据迅速识别、阻断可疑的欺诈交易行为,有效保护客户资产。
面向运维:数据全量即时可用,可将监管、运营分析等内外部提数过程实现自助化,大幅节省人力成本及资源投入。同时,将核心系统部分查询下移,可缓解业务负载洪峰(秒杀、双11等),提升源系统稳定性。
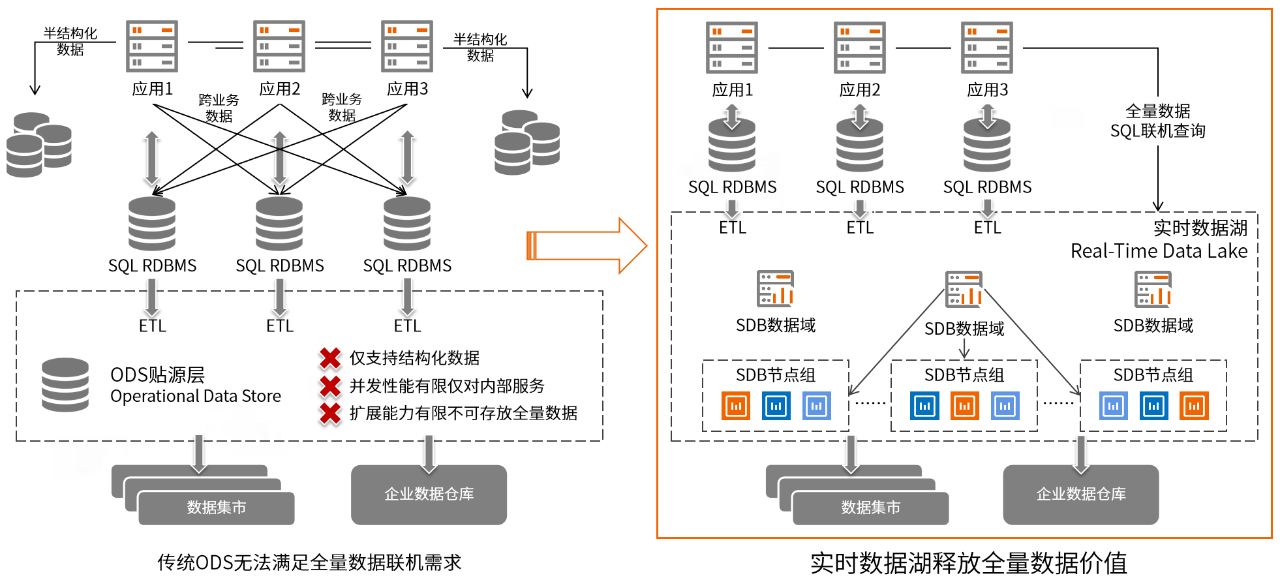
当前,在金融业大数据架构中,多种数据形态呈共存状态,如ODS、数仓、主题集市等,在全量数据完备性、时效性、共享能力、技术栈复杂度方面,存在明显的局限性。巨杉数据库深耕金融银行业,聚焦于从数据湖到湖仓一体的技术架构,针对业界对全量数据实时查询及处理的需求,提出实时数据湖技术方案。
实时数据湖提供了一种全量、即时使用、高性能的数据存储理念。它强调“先入湖,后使用”,即数据以原始形态,全量集中存储,在湖中按需随时使用。通过丰富的计算引擎,提供多样化的数据处理及服务能力,灵活应对联机对客查询、数据分析、批处理加工、数据科学等业务场景。- 超大规模存储。存储容量支持百PB级,并提供在线弹性扩展,应对数据爆发式增长;
- 高时效入湖。灵活地支持批量、流式入湖,高度兼容OGG、CDC、Canal等同步工具,对接Kafka、Flink等流式引擎,时效性可达到T+0;
- 多源异构。支持多源异构入湖,提供灵活的数据形态,包括结构化、半结构化等存储格式,灵活应对上游系统的结构差异及变化;
- 高性能。通过稳定的分布式框架和灵活的数据多维切分机制,为实时数据提供高并发、低延时的加载、查询、加工、分析等计算性能。
- 多样化数据服务。事务ACID能力,兼容标准SQL语法,支持多字段灵活索引,能够满足更多样化的应用场景,如实时对客查询、数据加工、数据分析、数据科学等。
相比于传统的ODS、数据集市和数据仓库,「实时数据湖」的优势在于:某大型股份制银行,以巨杉数据库作为存储底座,构建了实时数据湖。完成两核心数百亿交易明细数据的积累(国内核心、卡核心),面向客户提供五年交易流水查询,平均查询响应达数十毫秒级,在国内银行业遥遥领先。为客户提供个人账户下的全局资产信息,数据来自国内核心、卡核心、理财、贵金属交易等十余个业务系统,查询量数百万笔/日,峰值QPS为数百笔/s,其中仅手机银行渠道的资产查询就已占查询总量近半。以客户维度为基础,提供数百个复杂AUM指标的秒级实时计算,主要应用于客户身份识别、费率减免、客群分析、购买力判断、营销达标分析等场景。另增加了机构维度,为管理驾驶舱机构提供高频统计,展现时效为半小时。实现全量数据高保真在线,大幅缩短司法查询在数据提取环节的处理时长,司法查询自助化替代率近九成。单次处理时间缩短至0.5个工作日,每年减少磁带恢复近千次,节省人力约3人/年。巨杉数据库拥有100%自研的分布式数据库内核,目前已在银行、保险、证券等各领域,拥有丰富的最佳实践及案例,提供实时数据湖存储底座,助力客户实现提升降低成本、提升用户体验、提升运营效率、探索业务价值等目标。
未来,巨杉将与合作伙伴紧密携手,提供优质的产品、技术服务及生态支持,在数字化转型过程中,共同助力客户释放全量数据价值。