过去几年中,「湖仓一体」(Lakehouse)作为一种新的数据管理架构,逐步独立地出现在许多客户的应用场景中。这篇文章,让我们来看看这种新架构,有哪些技术特点和优势。
在决策支持和商业智能应用方面,数据仓库有着悠久的历史。数据仓库技术,自上世纪80年代末出现以来,经历了不断地发展。同时,MPP架构的出现,也使得系统能够处理更大规模的数据量。尽管仓库非常适合结构化数据,但是随着企业的现代化,产生了大量的非结构化、半结构化数据,这些数据呈现出多样性(variety),高速度(velocity)、大容量(volume)等特征。很显然,数据仓库并不适合这样的场景,而且就成本而言,一定不是最具优势的方案。
随着企业从多种数据来源中,大规模地收集数据,架构师也开始考虑,如何构建一个单一的系统,来实现数据的仓库化存储,并以此为多样化的数据分析应用提供承载。
大约十年前,数据湖出现了,它被定义为一种可以存储各类格式的原始数据存储库。数据湖虽然适合数据的存储,但又缺少一些关键功能,比如不支持事务、缺乏一致性/隔离性、不保证执行数据质量等,这样的短板决定了,让数据湖来承载读写访问、批处理、流作业是不现实的。这样一来,当初构建数据湖的目标并没有实现,而且在很多情况下,还失去了传统数据仓库原有的优势。
企业对于数据访问灵活性、高性能的需求从未降低,以此来支撑各种各样的应用系统,如包括数据分析、实时监控、数据科学和机器学习等。另一方面,对非结构化数据的处理(文本,图像,视频,音频),已经成为了人工智能的前沿、热点领域,而这却是数据仓库不擅长处理的。
目前,多系统共存是企业中比较常见的架构,例如一个数据湖,加上多个数据仓库,以及其他的专用系统,例如流、时间序列、图形和图像数据库等。这种架构的复杂性,带来了运维的难题,因为技术人员始终需要在不同系统之间移动或复制数据。更重要的是,数据的传输引入了延迟,不能提高数据的时效性。
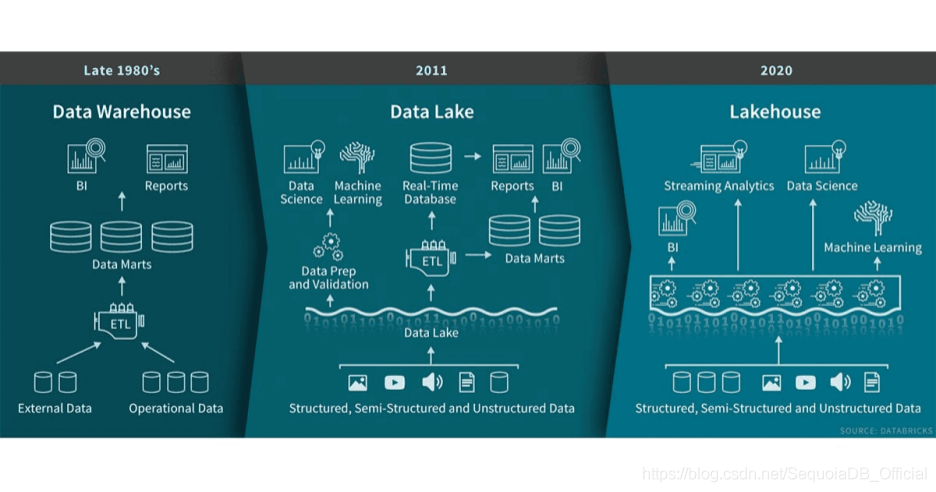
为了解决数据湖的局限性,一些新系统开始选择数据「湖仓一体」(Lakehouse)。「湖仓一体」是一种新型开放式架构,将数据湖和数据仓库的优势充分结合,它构建在数据湖低成本的数据存储架构之上,又继承了数据仓库的数据处理和管理功能。
数据「湖仓一体」具有以下关键特征:
事务支持:在企业中,数据往往要为业务系统提供并发的读取和写入。对事务的ACID支持,可确保数据并发访问的一致性、正确性,尤其是在SQL的访问模式下。
数据的模型化和数据治理:「湖仓一体」可以支持各类数据模型的实现和转变,支持DW模式架构,例如星型模型、雪花模型等。该系统应当保证数据完整性,并且具有健全的治理和审计机制。
BI支持:「湖仓一体」支持直接在源数据上使用BI工具,这样可以加快分析效率,降低数据延时。另外相比于在数据湖和数据仓库中分别操作两个副本的方式,更具成本优势。
存算分离:存算分离的架构,也使得系统能够扩展到更大规模的并发能力和数据容量。(一些新型的数据仓库已经采用了这种架构)
开放性:采用开放、标准化的存储格式(例如Parquet等),提供丰富的API支持,因此,各种工具和引擎(包括机器学习和Python / R库)可以高效地对数据进行直接访问。
支持多种数据类型(结构化、非结构化):Lakehouse可为许多应用程序提供数据的入库、转换、分析和访问。数据类型包括图像、视频、音频、半结构化数据和文本等。
支持各种工作负载:支持包括数据科学、机器学习、SQL查询、分析等多种负载类型。这些工作负载可能需要多种工具来支持,但它们都由同一个数据库来支撑。
这是数据「湖仓一体」的一些关键属性。当然,企业级的系统还需要其他的补充功能。其中,数据安全和访问控制是至关重要的,包括数据的审计、保留周期、数据血缘管理,尤其在隐私保护相关法律法规的监管之下,这些需求更为迫切,一些允许数据探索拓展的工具如数据目录(Data Catalog)和数据使用量度(Data Usage Metric),都存在类似需求。在「湖仓一体」架构下,这些企业级的需求功能,都可以在「湖仓一体」平台中部署、测试和管理。
相比数据湖,SequoiaDB「湖仓一体」架构能够支撑实时数据湖、内容数据管理场景,弥补了如Hadoop架构构建数据湖的重大不足。相比数据仓库,SequoiaDB「湖仓一体」作为支持实时处理的统一数据底座,数据可以实时入库,实时分析,无需异步写入另一个数据库再进行分析处理,大大降低了数据处理的成本。
参考文献URL:https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html
参考文献作者:Ben Lorica,Michael Armbrust,Ali Ghodsi,Reynold Xin,Matei Zaharia