前言
而ELT(Extract-Load-Transform),则提供了更现代化的替代方案,在该方案中,分析师在转换数据之前将数据加载到数据仓库中,从而支持更灵活、更敏捷的工作方式。
无论是ETL,还是ELT,都是把数据从数据源移动到数据仓库的过程。两种方案的根本区别,在于原始数据「转换」和「加载」的先后顺序,以及随后如何执行分析。
在本文中,我们将对两种方案之间的差异,以及ELT的优势展开讨论。
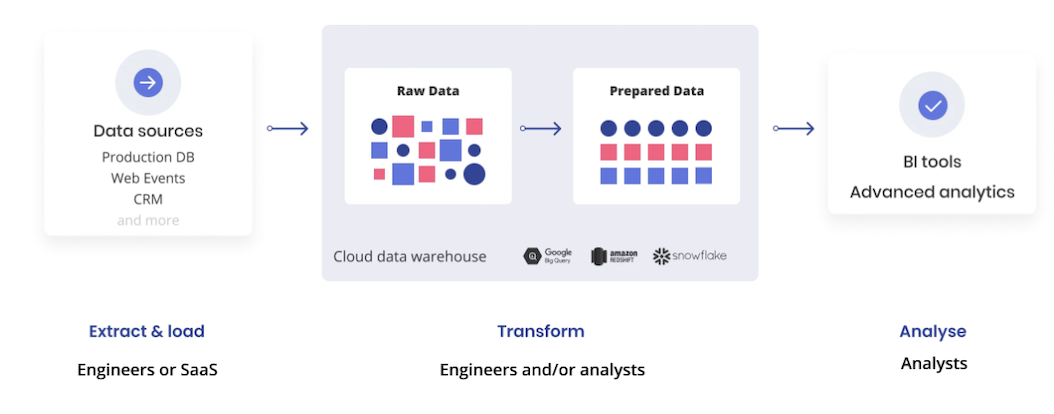
传统ETL
抽取:按照时间戳、触发条件等方式,从数据源中抽取原始数据。在传统的ETL流程中,此数据被放入临时的中间区域(Staging Area)中。
转换:原始数据经过必要的清洗和转换,才能进入数据仓库。如去重、纠错、数据标准统一、按业务规则运算等。
加载:转换后的数据,加载到目的端的数据仓库中。
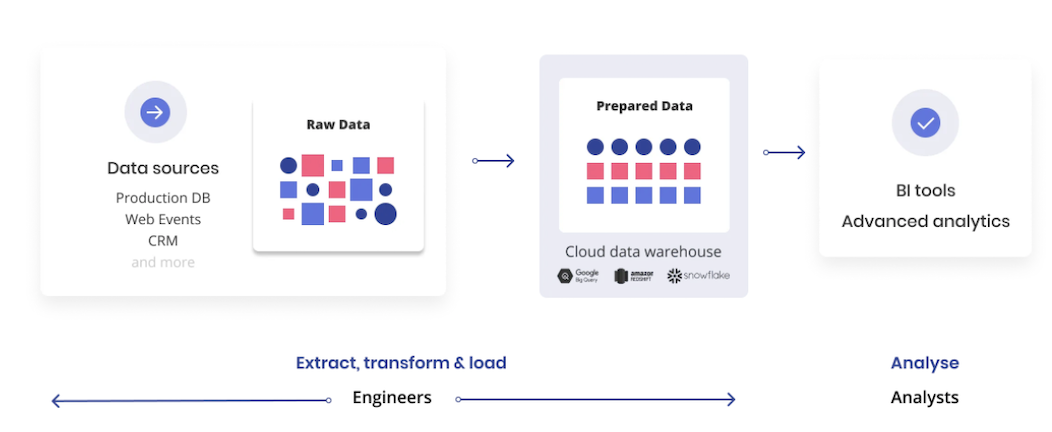
新型ELT
ELT,是传统ETL的新型迭代架构,依托于云数据仓库极强的可扩展性和存算分离架构设计,充分利用数据仓库(或数据湖)优异的计算和存储能力,在数据加载完之后再进行数据转换。由于「转换」过程在数据仓库一侧进行,并且可以通过SQL完成,提供了更加灵活的转换模式,也使得分析人员更清楚地掌控转换规则和逻辑,从而提升分析作业效率。
ETL vs ELT
敏捷性:所有数据都存储在数据仓库中,随用随取。分析人员可按照实际需求灵活地建模,而不用在数据加载之前规划数据模型。
简便性:数据仓库中的转换通常用SQL来实现,而SQL是整个数据团队(如数据工程师、数据科学家、数据分析师等)都能理解的语言。这使得整个团队都可以参与到数据的转换、分析。
自助服务分析:原始数据都在数据仓库内部,因此可以使用BI工具,从聚合的统计信息中,向下钻取获得其原始数据。
错误修正:如果在转换中发现错误,仅需重新运行「转换」步骤来修正数据。而使用传统ETL,则需要重新运行全部「抽取-转换-加载」过程。
数据清理:在敏感数据进入仓库之前(如个人识别信息PII),将其脱敏,保证可以被用户公开访问。
容量控制:在超大容量数据的场景,使用ETL流程,可以对数据进行一定过滤,避免不需要的数据格式进入数据仓库,进而引发性能或容量的问题。
流式转换:大多数数据仓库不支持流式转换。因此,为了保证在海量数据场景下能够实现低延迟、低成本的流式转换,还需要借助传统ETL。
总结