
![]()
数据湖 & 数据仓库
数据湖
AWS对数据湖的定义如下:数据湖存储着来自业务线应用程序的关系型数据,以及来自移动应用程序、IoT 设备和社交媒体的非关系型数据。捕获数据时,无须定义数据结构或 Schema,用户可以对数据使用不同的方式(如 SQL 查询、大数据分析、全文搜索、实时分析和机器学习)来获得对数据的深入了解。因此,数据湖的意义在于,当我们不清楚某些数据存在的价值时,将数据以原生格式天然沉积在数据湖。数据来源不尽相同,能够同时存储结构化和非结构化数据。同时,可以使用不同的过程将数据注入到数据湖中。最终,都是为了帮助用户,根据自己的需要更好地处理数据。
数据仓库
数据仓库是一个经过优化的数据库,用于分析来自事务系统和业务线应用程序的关系型数据。用户需要事先定义数据结构和Schema,并优化SQL 查询,结果通常用于操作报告和分析。数据经过了清理、丰富和转换,因此可以充当用户可信任的“单一信息源”。可以说,数据仓库中找到的任何数据都将与数据仓库中的所有其他数据密切相关。数据仓库对数据提供高效地存储,便于用户通过报表、看板和分析工具来获取查询结果,从而从数据中获得洞察力、决策指导。
传统的数据湖、数据仓库面临的挑战
可以看出,传统意义上的数据湖、数据仓库,存在着显著的差异:
(下表来自于AWS, https://aws.amazon.com/cn/data-warehouse/)
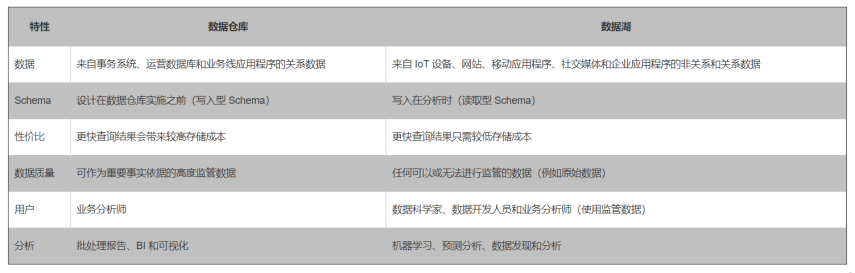
在数据湖中,海量数据以原生格式(或者经过粗加工后)进行积累和沉淀,格式丰富多样,有结构化、半结构化、非结构化类型,强调数据的原始性、灵活性和可用性;
而对于数据仓库,其数据主要来源于业务系统,存储格式以结构化为主,并且历经加工清洗,数据形态显得更加范式化、模型化,因此数据的灵活度较低。
目前,很多企业采用传统的“湖仓分离”模式,独立建设了数据湖和数据仓库,虽然一定程度上实现了功能的互相补充,但企业在数据运营、价值挖掘、运维等方面,也遇到了显著的挑战:
数据湖中的数据模型未经治理,数据混乱,无法进行有效的元数据管理、血缘关系管理,一定程度上形成了“数据沼泽”,数据价值得不到更充分的挖掘。
数据仓库和数据湖之间,不能实现高时效的数据共享,一般需要借助ETL数据传输来打通。同时,数据的冗余存储,带来了资源的浪费。数据湖如果不能充分地进行数据共享,终将成为一组组断开连接的数据池或信息孤岛的集合。
传统的数据湖,对业务的承载能力很有限,无法对外提供海量数据的高性能查询服务。
不同格式的数据在转换处理时,引入大量的开源模块,这使得技术栈更加复杂化,尤其是当数据容量达到一定量级时,管理和维护成本大幅增加。
湖仓一体
近年来,业界开始提出湖仓一体(Data Lakehouse)的概念,旨在为企业提供一个统一的、可共享的数据底座,避免传统的数据湖、数据仓库之间的数据移动,将原始数据、加工清洗数据、模型化数据,共同存储于一体化的“湖仓”中,既能面向业务实现高并发、精准化、高性能的历史数据、实时数据的查询服务,又能承载分析报表、批处理、数据挖掘等分析型业务。
湖仓一体方案的出现,帮助企业构建起全新的、融合的数据平台,打破了数据湖与数据仓库割裂的体系,在架构上将数据湖的灵活性、数据多样性以及丰富的生态,与数据仓库的企业级数据分析能力进行融合。
通过对机器学习和AI算法的支持,实现数据湖+数据仓库的闭环,极大地提升业务的效率。数据湖和数据仓库的能力充分结合,形成互补,同时对接上层多样化的计算生态。
毫无疑问,湖仓一体将会更好地服务于企业,帮助企业实现大数据能力的提升,如降低成本、提升运营效率、业务模式探索等。
SequoiaDB在湖仓一体的技术布局
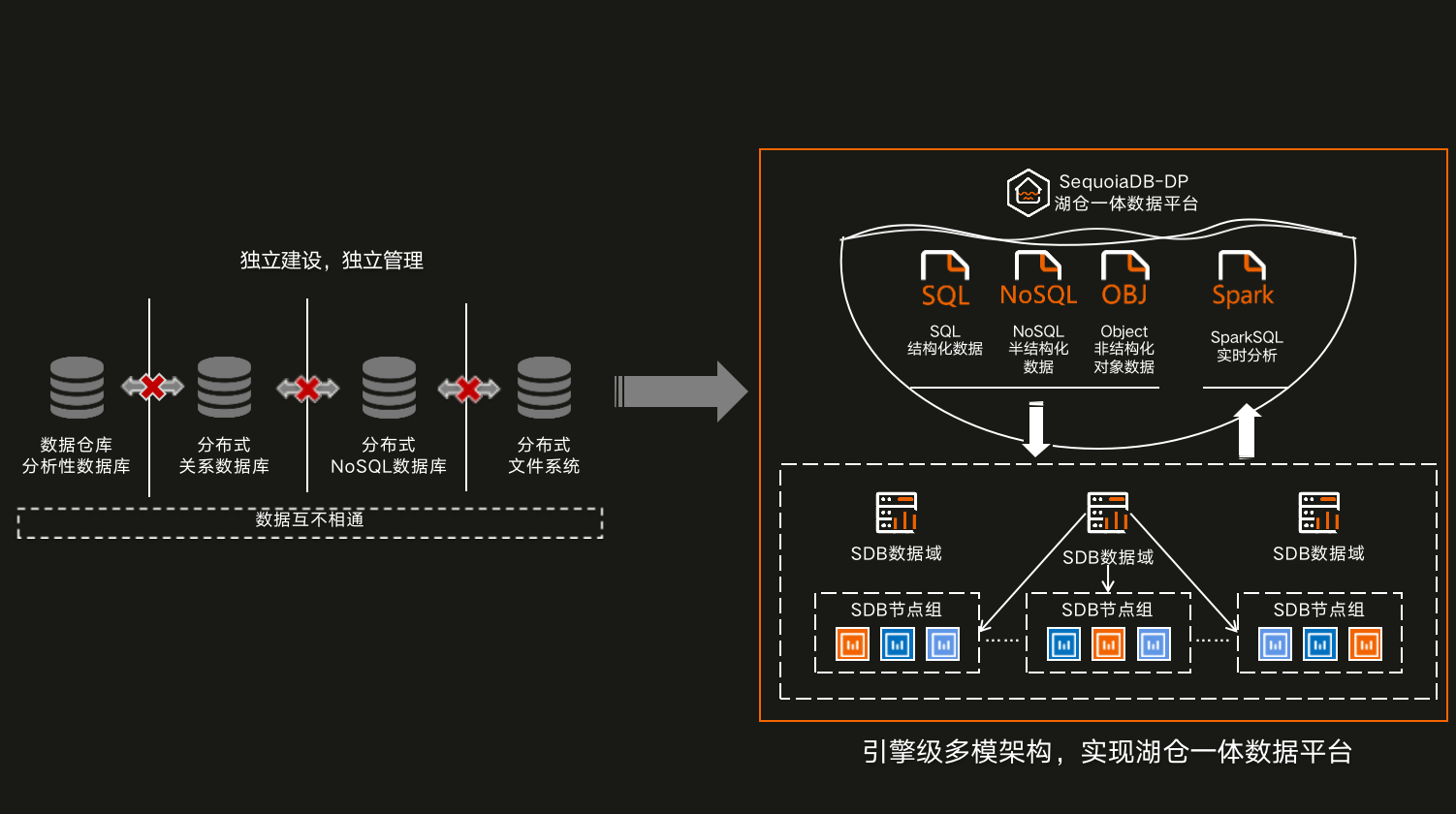
基于100%自研的分布式数据库内核,巨杉数据库即将提供「SequoiaDB-DP」湖仓一体数据平台。面向联机数据中台、历史数据服务平台、IoT物联网等海量数据需求场景,为企业级客户打造数据平台的最佳底座,助力客户实现提升数据管理水平、降低成本、提升运营效率、提升用户体验等目标。

(具体实践案例,可参考:巨杉分享 | 巨杉数据库在数据湖中的应用实践)







