01 概述
作为一个拥有全分布式系统架构的数据库,SequoiaDB 支持各种灵活的部署方式。本文主要将以三副本为例,介绍SequoiaDB巨杉数据库在单数据中心下部署规划最佳实践。
02 部署规划最佳实践探索
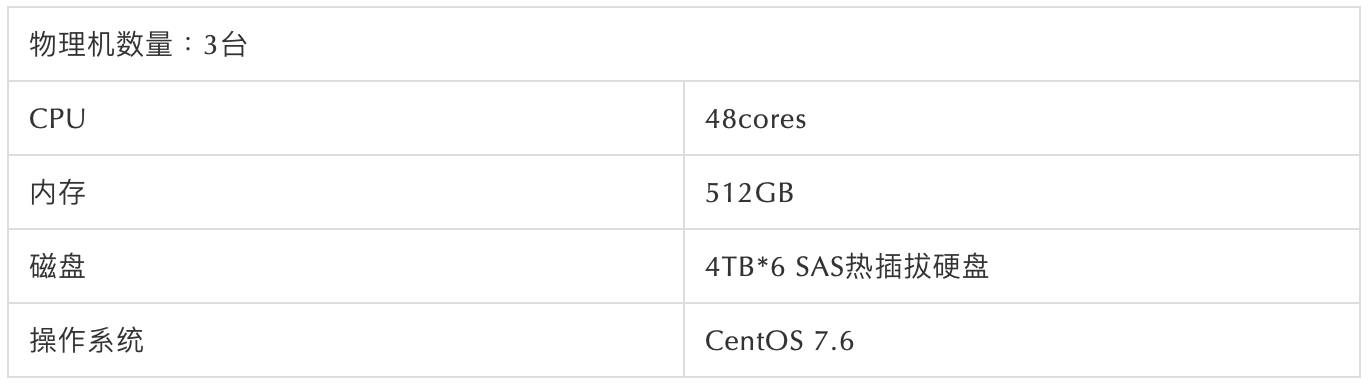
2.2 物理架构部署规划
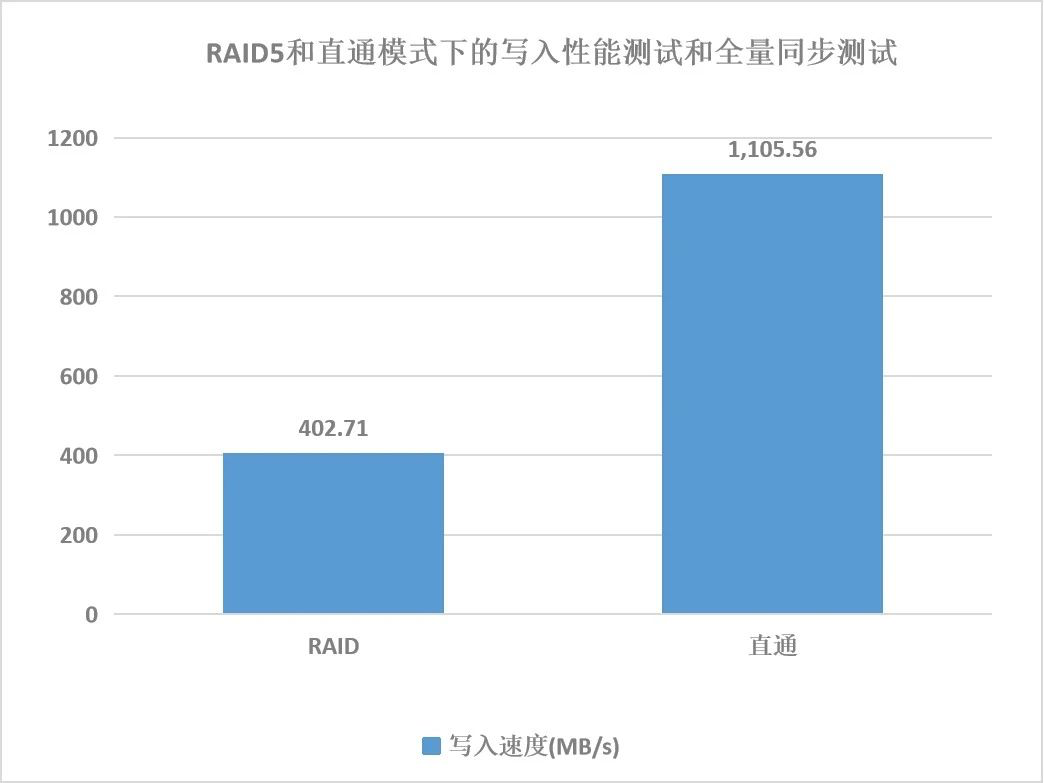
为避免多个数据节点部署在一块盘上,在业务压力大时候发生IO抢占的问题,我们建议按照每块盘上部署一个数据节点的方式来规划,最终数据节点规划方案如下图。
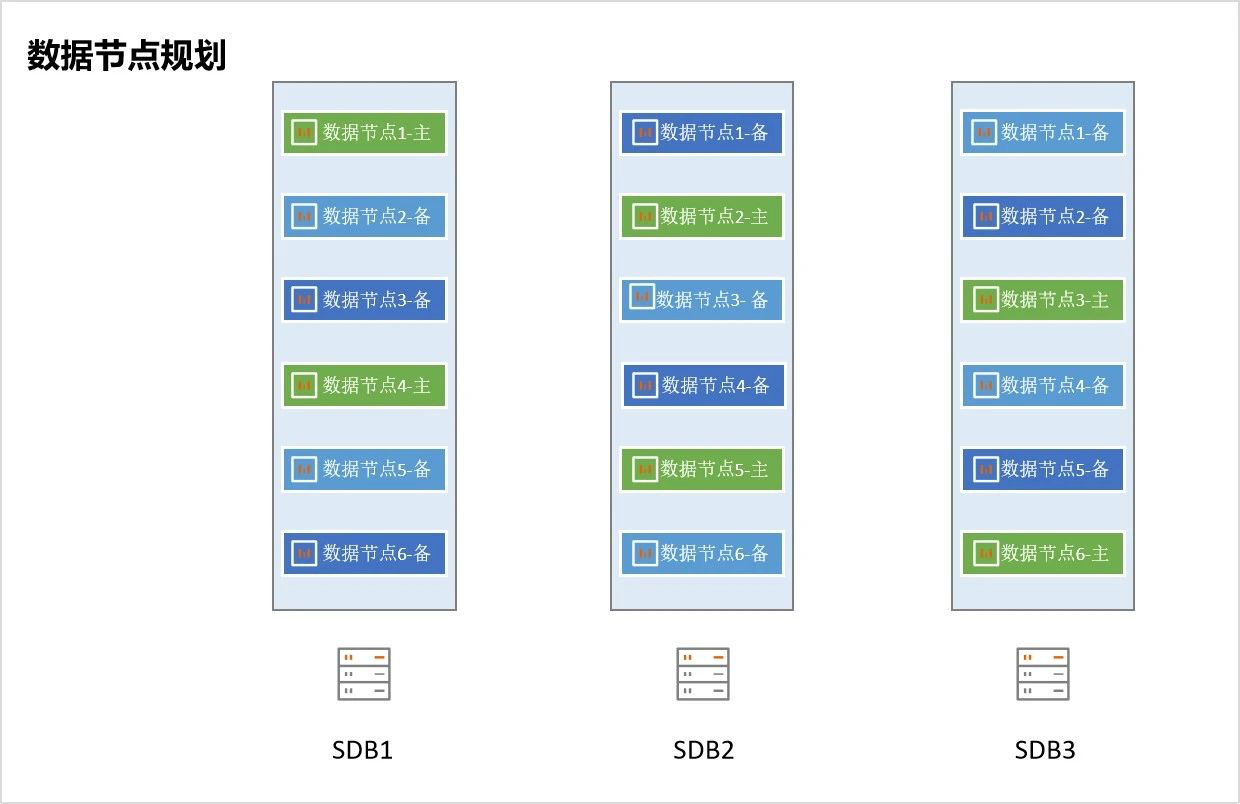
SequoiaDB在集群的管理上定义了数据域、分区组的概念。数据域由若干个复制组(ReplicaGroup)组成的逻辑对象。每个域都可以根据定义好的策略自动管理所属数据,如数据切片和数据隔离等。分区组又被称为复制组,一个复制组内可以包含一个或多个数据节点(或编目节点),节点之间的数据使用异步日志复制机制,保持最终一致。
一个集群可以根据不同的业务系统来划分不同的数据域,不仅实现将不同业务系统数据在物理层面的隔离存储,同时也实现了不同业务系统数据的统一调度管理,而且以后的集群扩容也可以根据域的使用需求而只针对此域进行集群扩容,假定将测试环境的数据域按照存储数据的结构来划,则数据域规划方案如下:
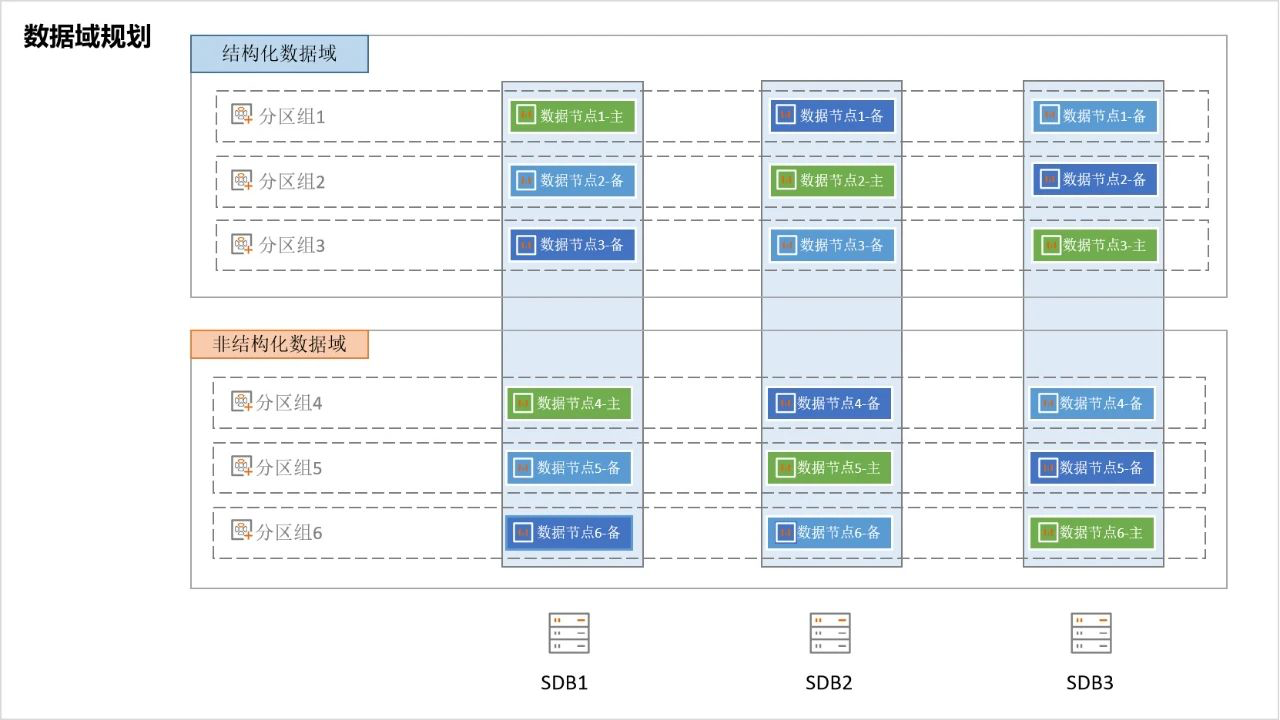
而在一个域内部,则可以根据业务数据的特性采用灵活的分区管理方式,将一张表的存储分散到多个物理位置,大大的减少单次操作读取的数据量,例如对于超大表,多采用多维分区的方式将业务数据集合分成多个子集合,每个子集合的数据分布在数据域内所有的复制组中,对于一些存储配置信息的小表则可以存储在指定复制组中,数据存储示意图如下:
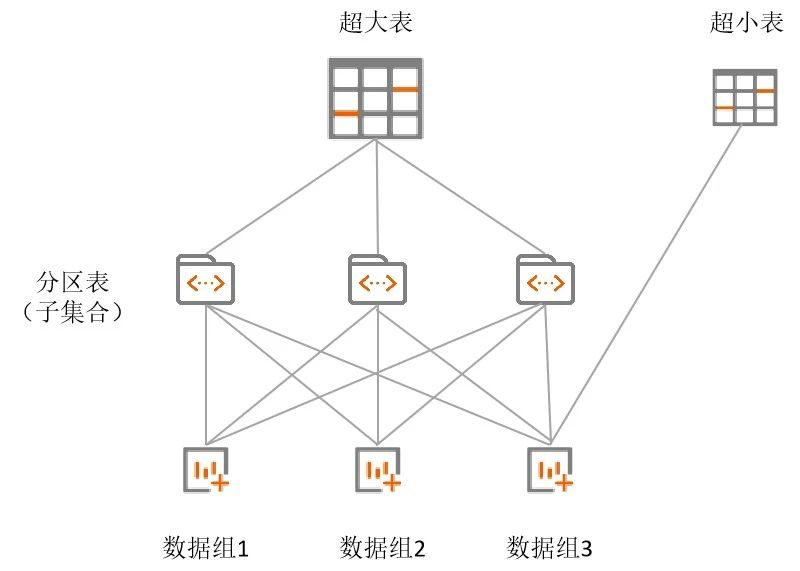
下面演示一下如何划分数据域,以及如何通过不同的分区方式来管理超大表和小表。具体步骤如下。
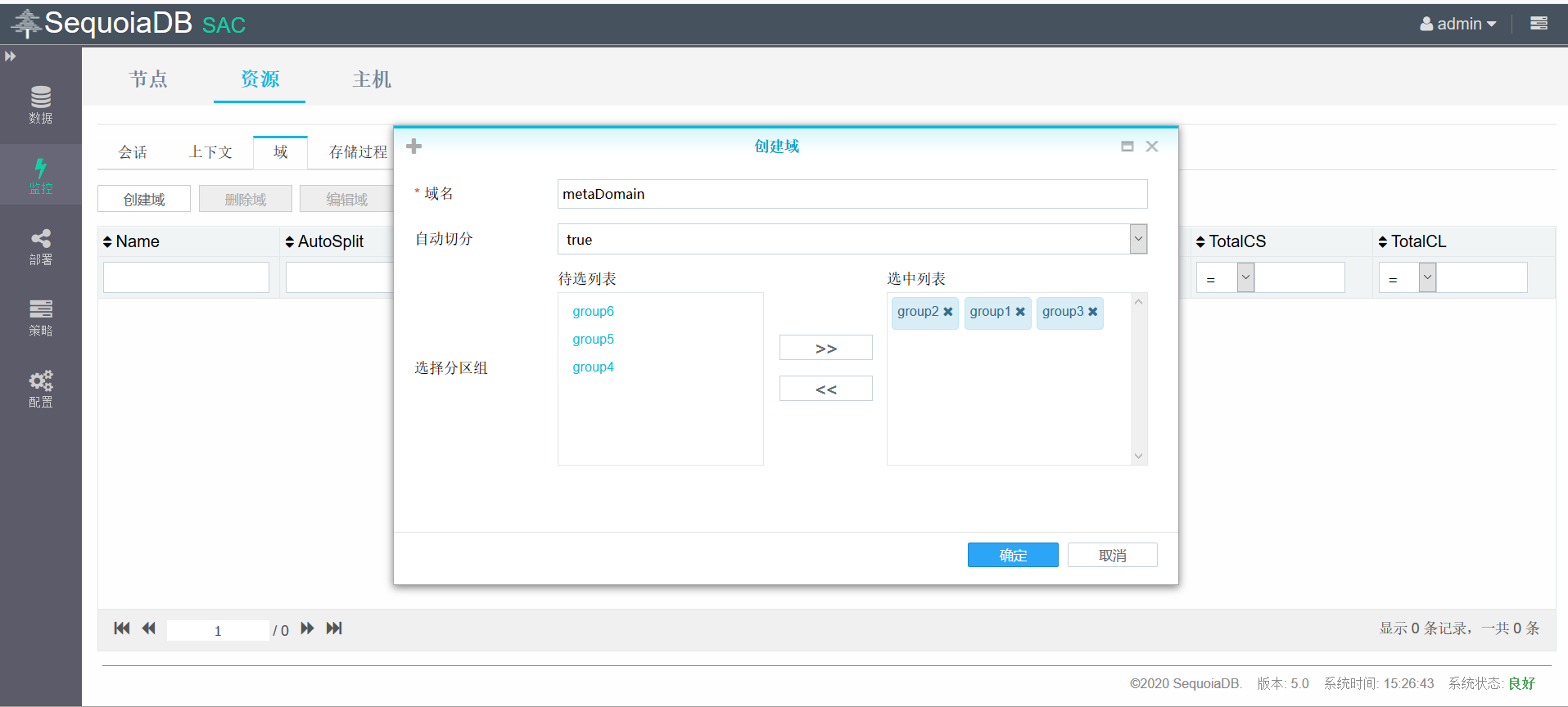
1. 划分数据域
创建结构化域d1
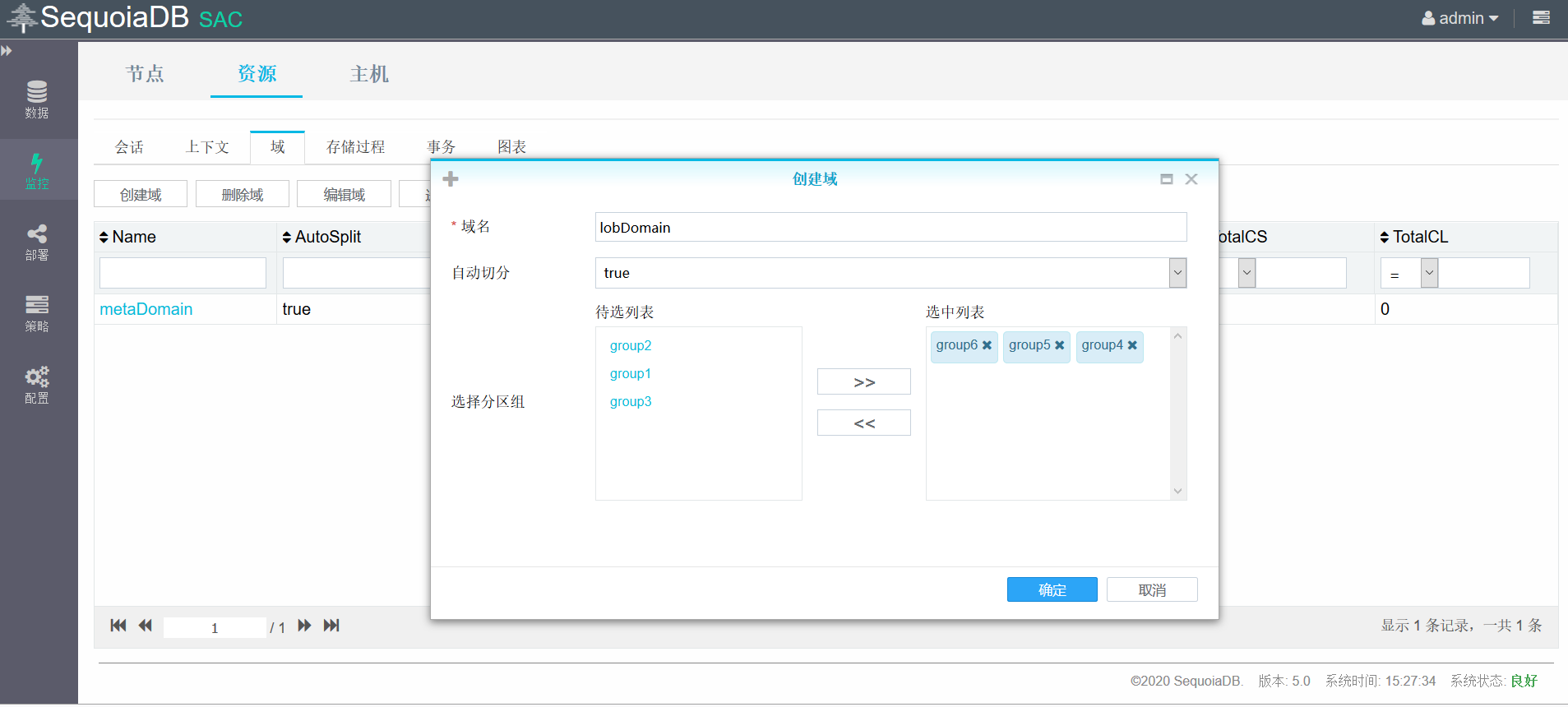
创建非结构化域d2
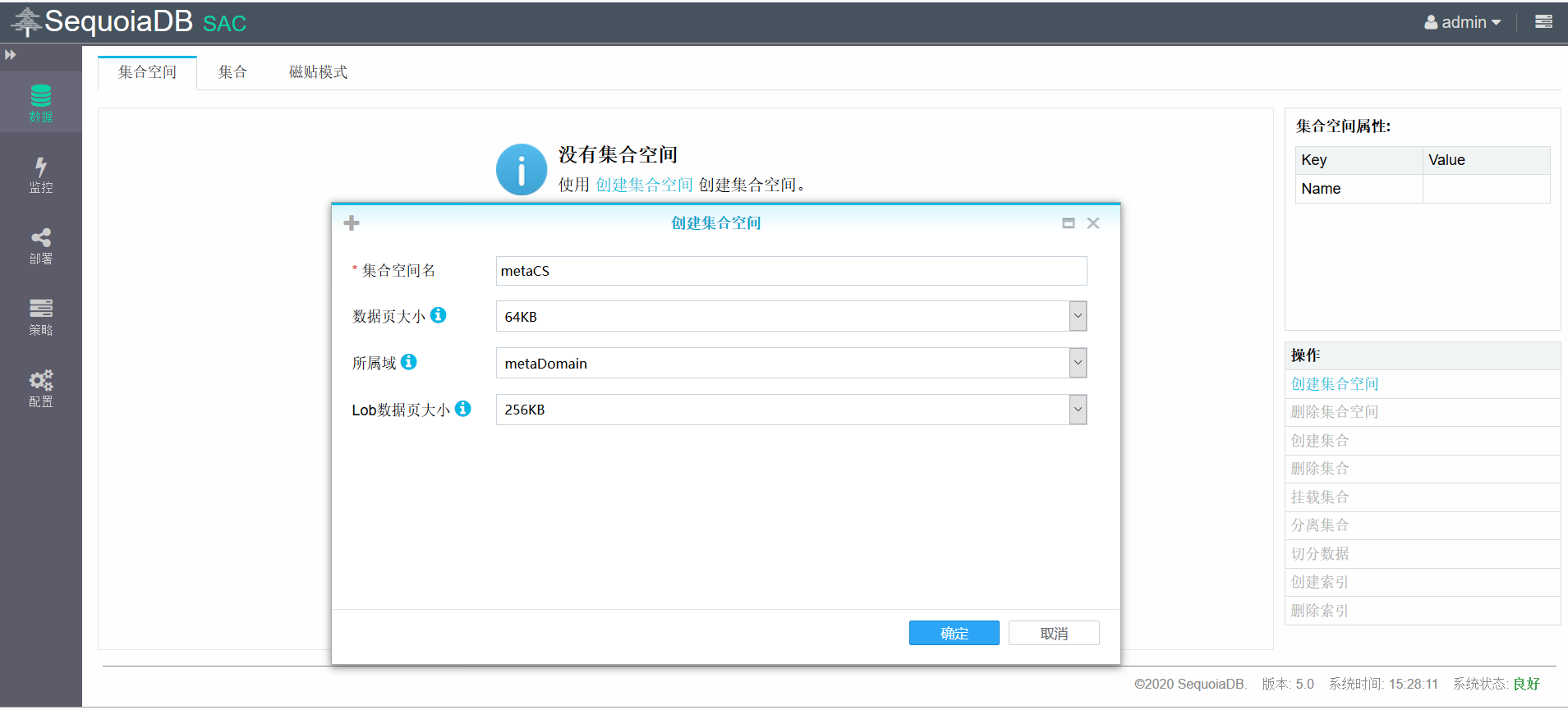
创建表空间metaCS
创建主表’metaCL’
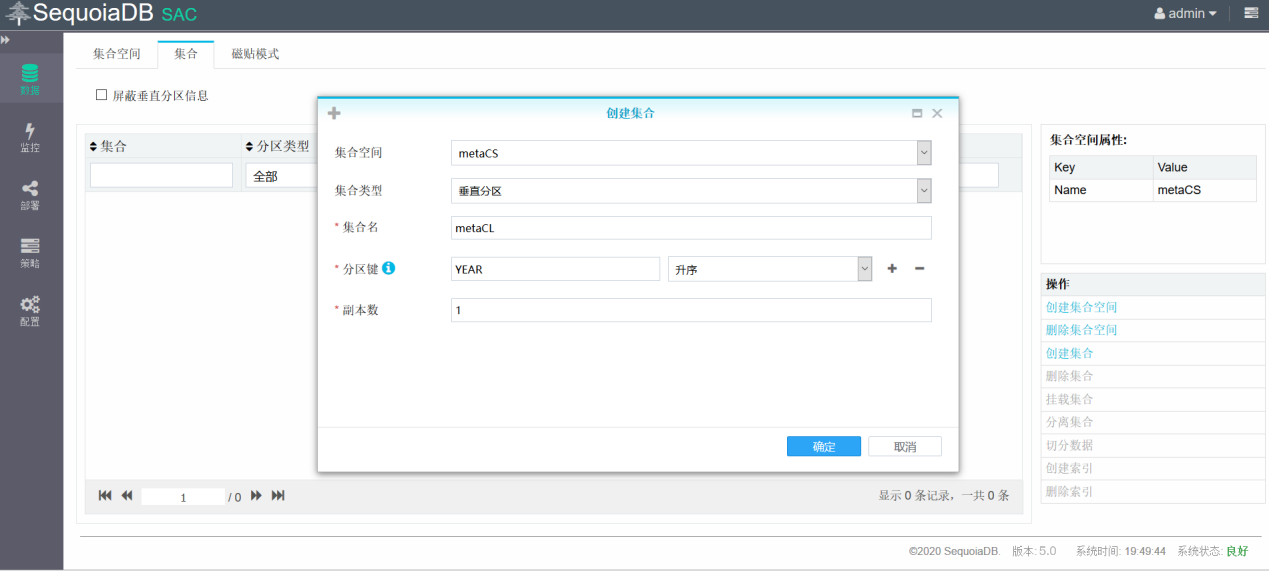
创建子表metaCL2020用于存储2020年的数据
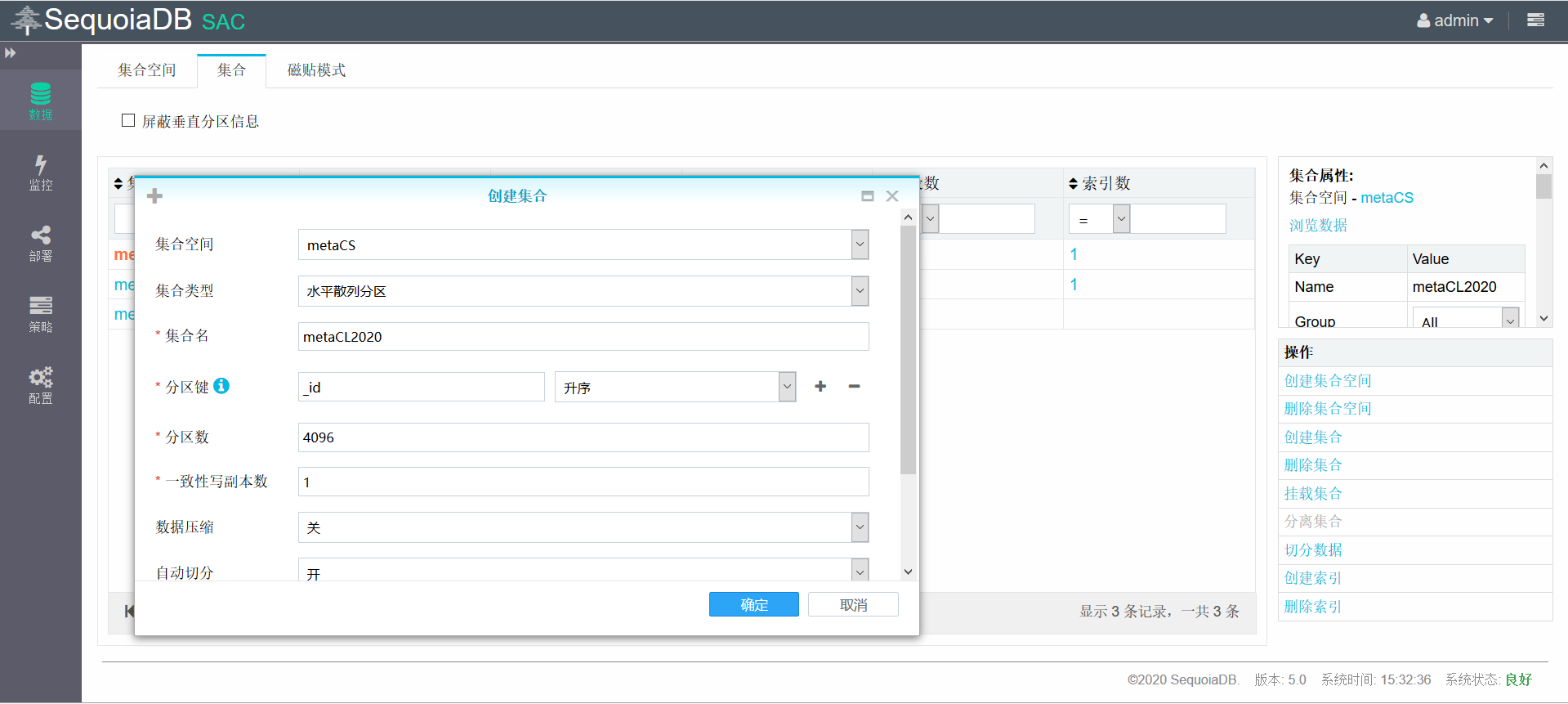
创建子表metaCLMin用于存储2020年以前的数据
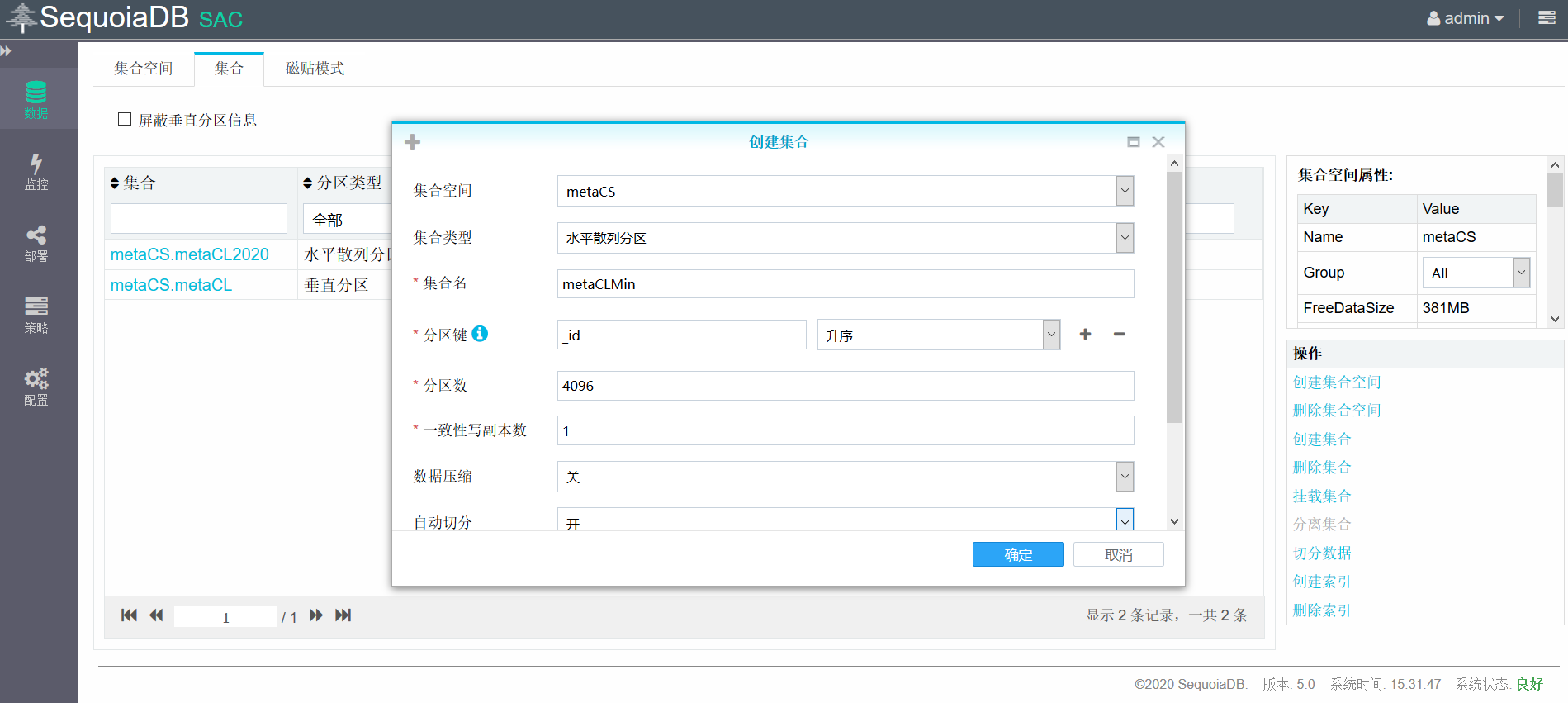
创建子表metaCLMax用于存储2020年之后的数据
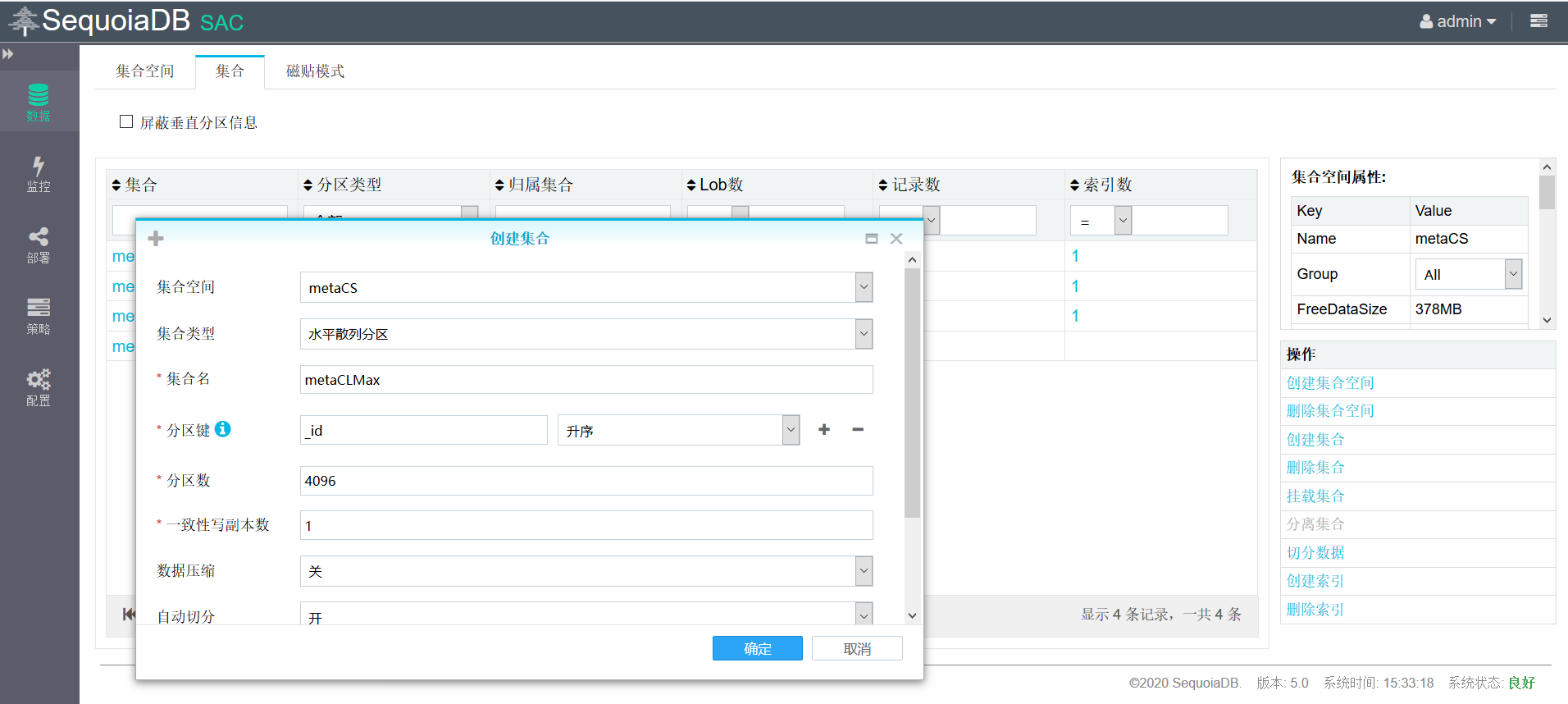
将子表metaCL2020挂载到主集合上,用于存储2020年的数据
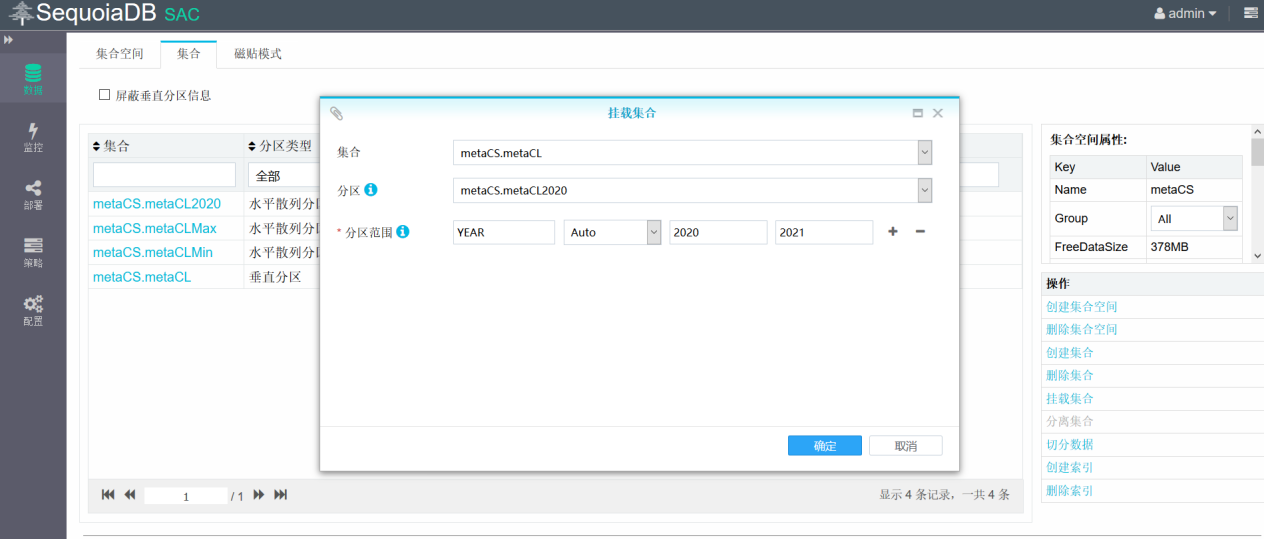
将子表metaCLMin挂载到主集合上,用于存储2020年以前的数据

将子表metaCLMax挂载到主集合上,用于存储2020年以后的数据
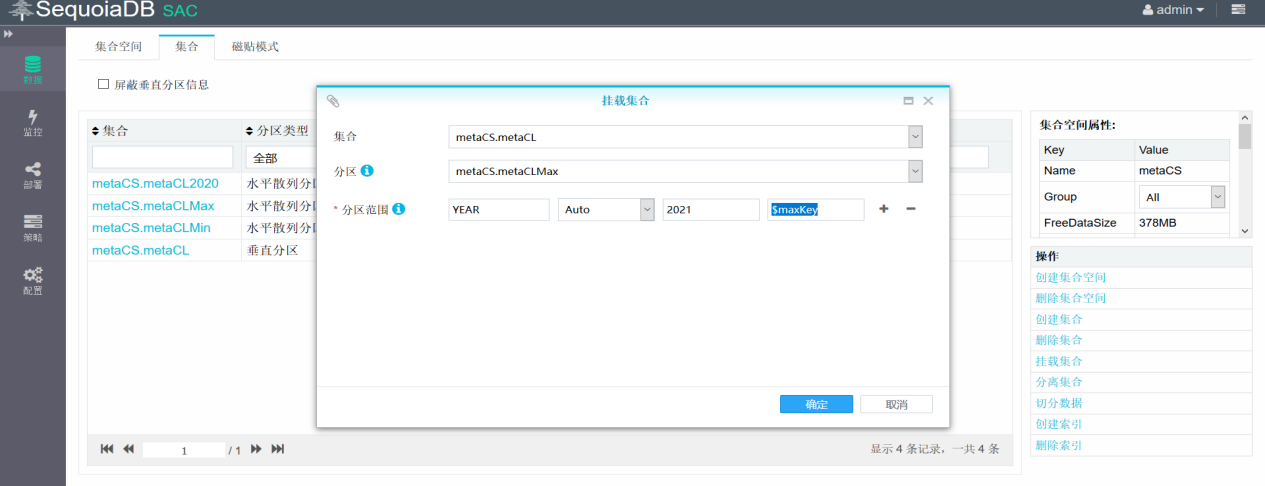
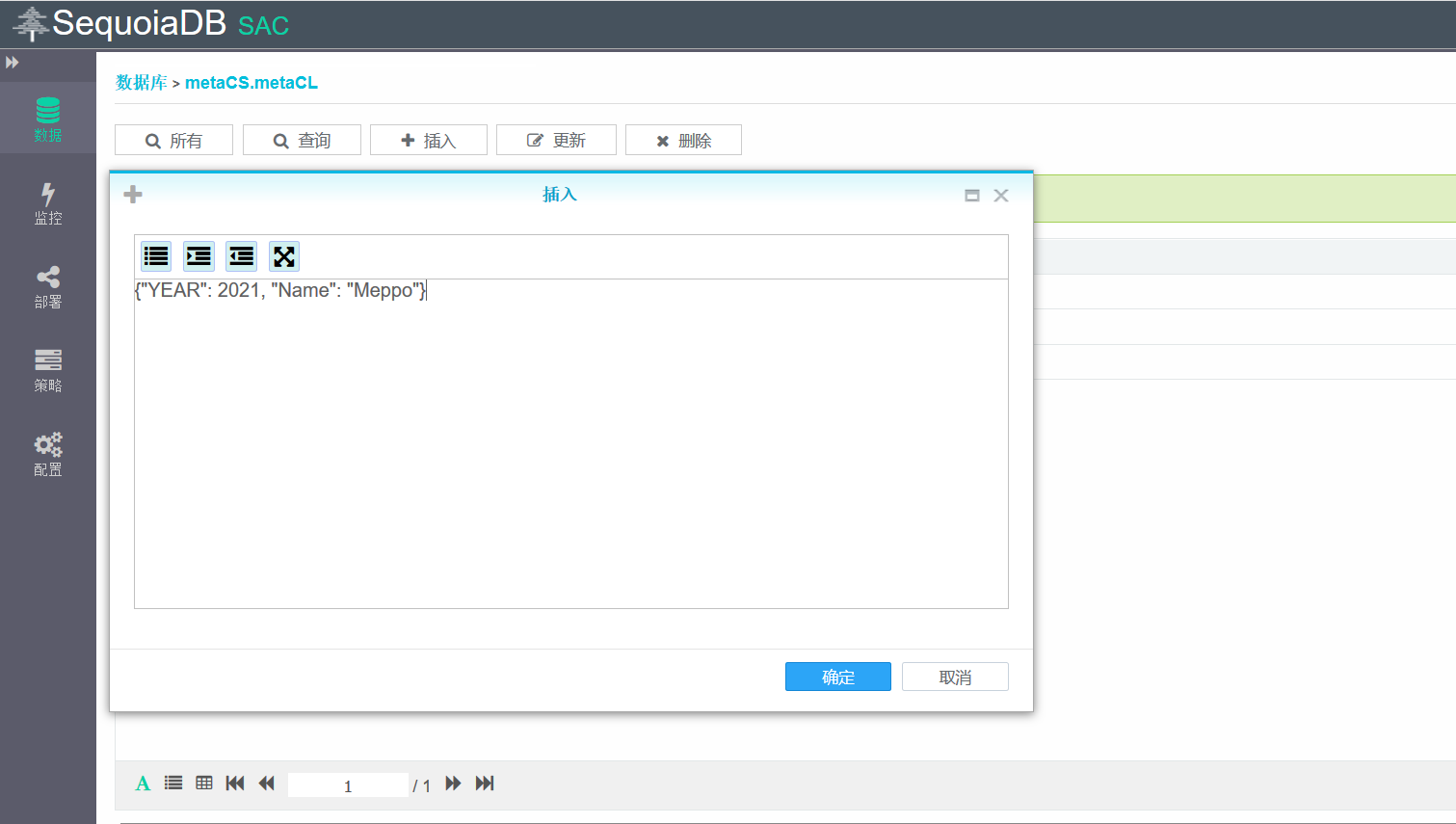
创建完多维分区表之后,我们简单插入几条数据:
{"YEAR": 2021, "Name": "Meppo"}
{"YEAR": 2020, "Name": "Tiny"}
{"YEAR": 2019, "Name": "Tommy"}
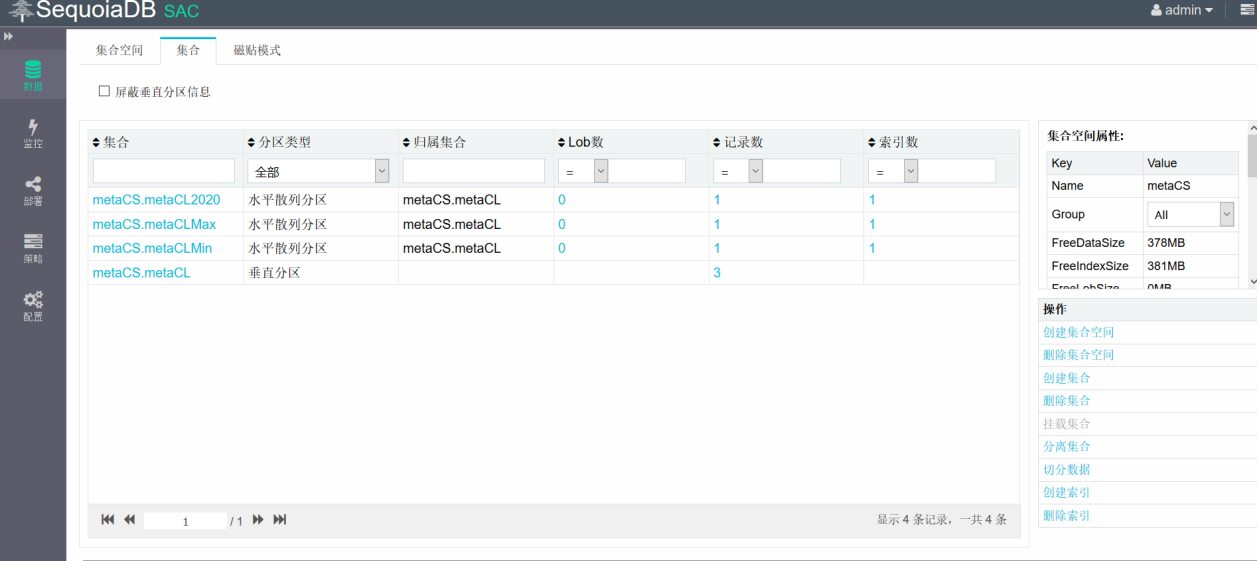
查看数据分布,可以看到数据根据YEAR的分区规则进入了各自的子表中
下面我们再向集合中插入几条数据,验证数据是否会分布在不同复制组中,可以看到新插入的数据都分布到了group2和group3中
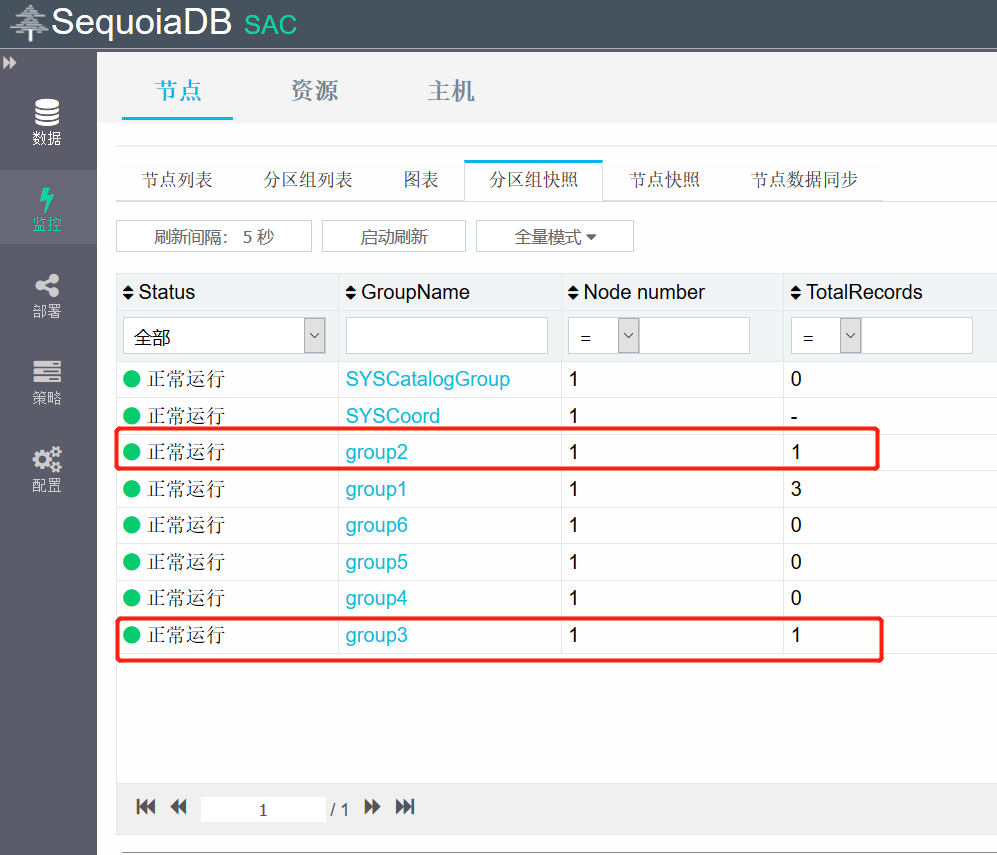
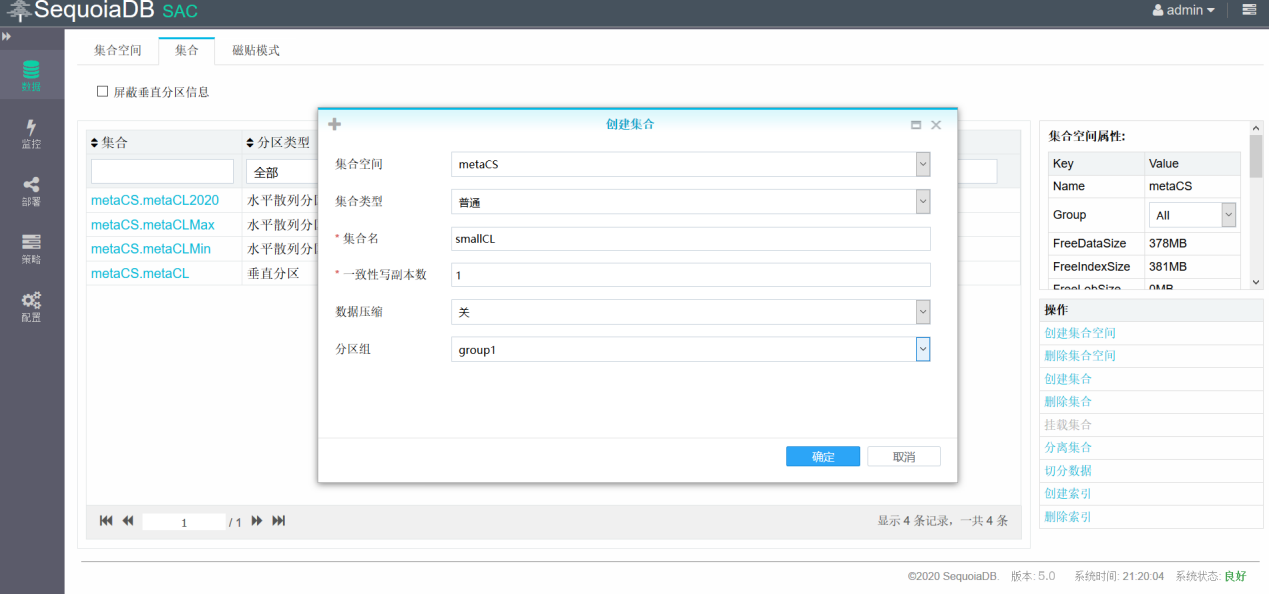
新建smallCL表,分区组指定为group1
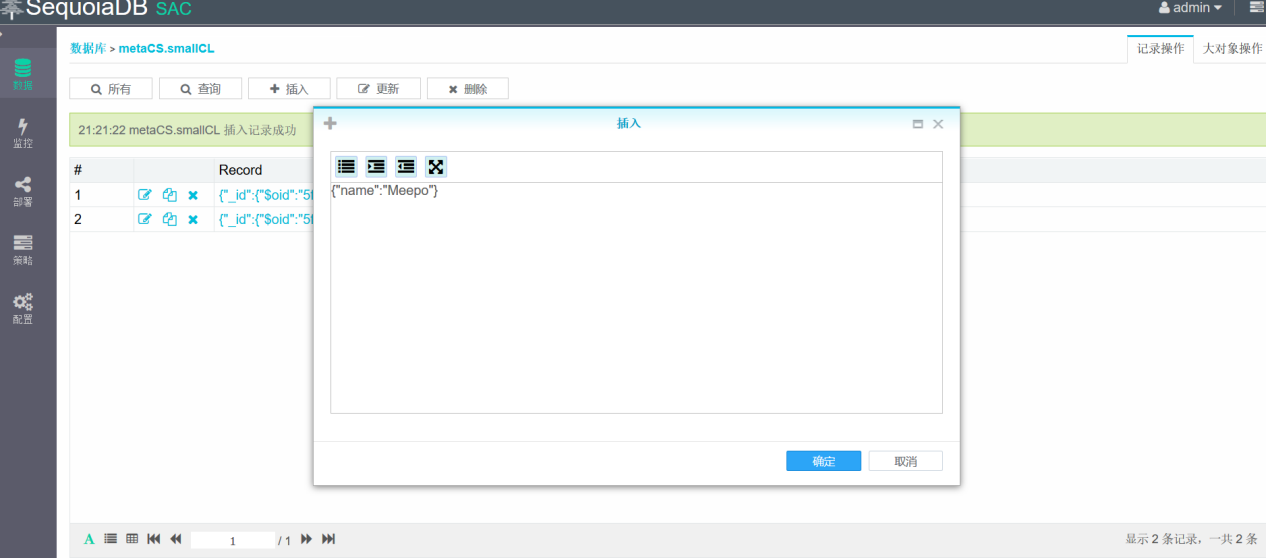
向集合中插入三条测试数据
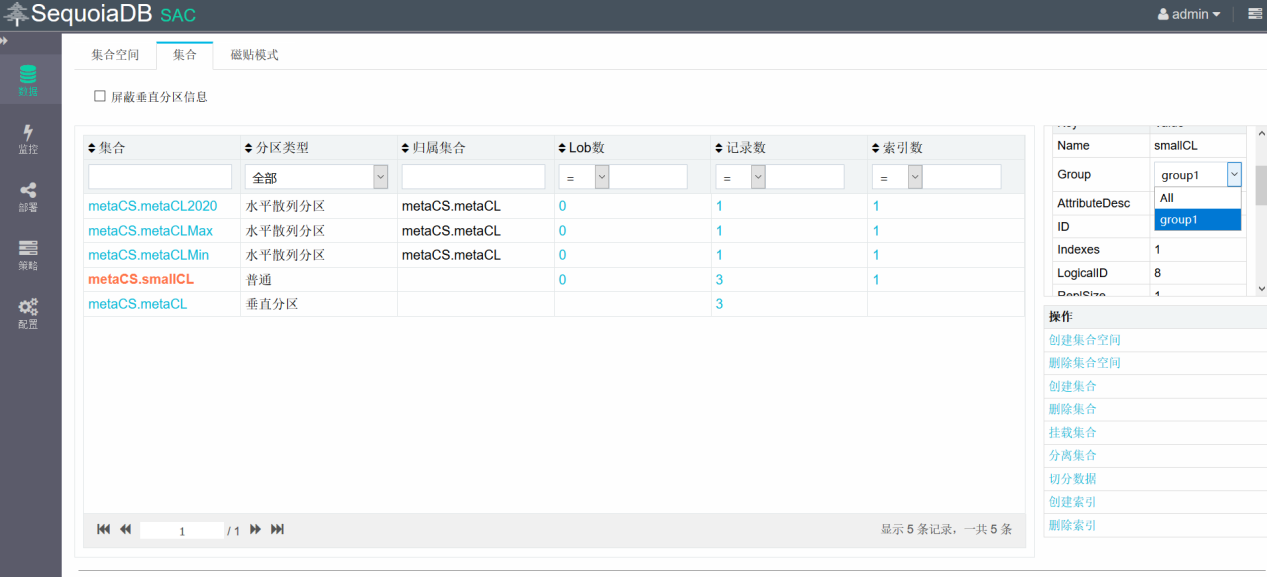
查看smallCL表的数据分布,所有数据全都存在指定的数据组group1上,可以看到所有的数据都存储在group1中
03总结






