本篇笔记将为大家介绍 SequoiaDB 巨杉数据库查询 SQL 语句的执行过程,以及查询语句执行过程中实例层、协调节点、编码节点、数据节点各自承担的功能。
应用程序或用户想要从数据库查询需要的数据,首先通过 API 或 client 端连接数据库,将查询 SQL 语句发给数据库,数据库解析查询 SQL 语句,执行完成后将结果返回给应用程序或用户。
首先看一下大家熟悉的 MySQL 数据库。
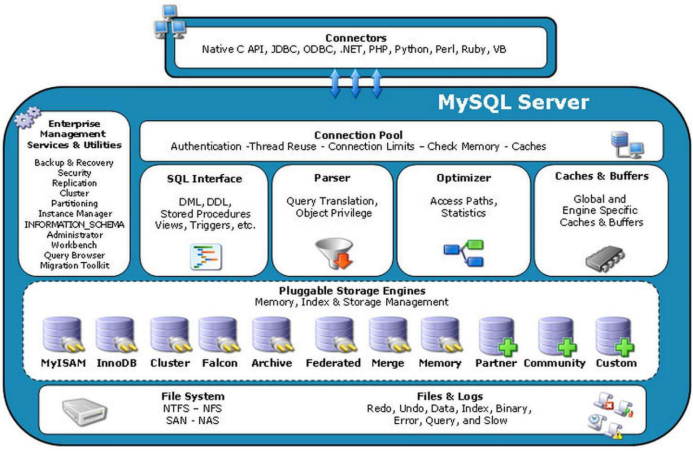
MySQL 总体分为两层:MySQL server层和 InnoDB 等存储引擎层。MySQL server层负责请求处理和数据计算,InnoDB 存储引擎层只负责存储数据。
SQL 语句的大体执行过程为:client 端把查询 SQL 语句发给 MySQL server 层,server 层负责语法解析、语义解析、生成执行计划、执行SQL语句。
前三个过程单独在 server 层完成。执行 SQL 语句时,需要与 InnoDB 层进行交互,将对应的数据加载到 server 层的内存中,最终的计算还在 MySQL server 层实现。RDBMS 类型的数据库的 SQL 语句执行过程都是相似的,通过对 MySQL 数据库的了解,我们更容易理解 SequoiaDB 数据库的查询 SQL 语句执行过程。
根据 SequoiaDB 巨杉数据库官方给出的架构图可以看出:
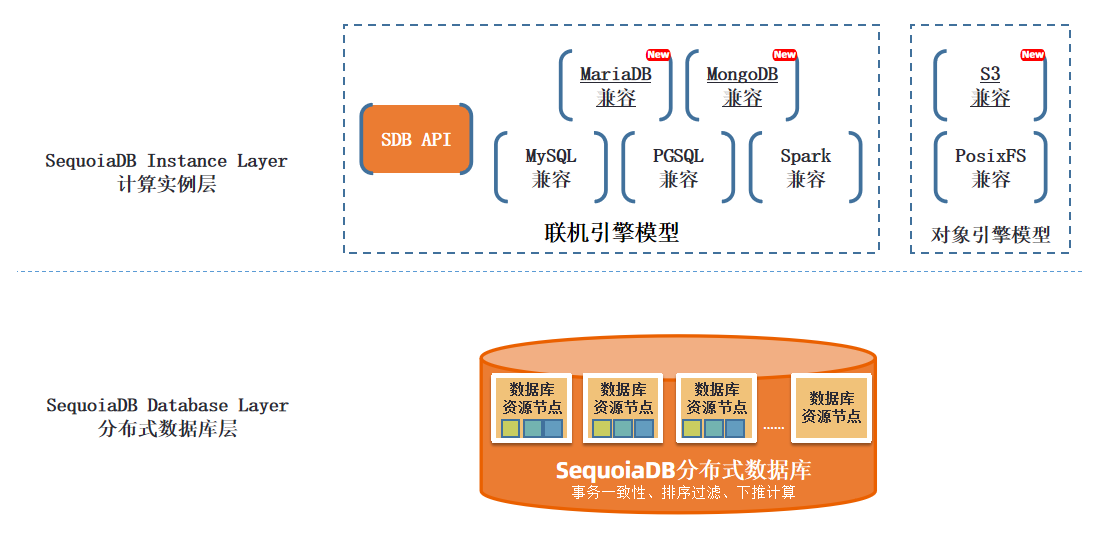
SequoiaDB 巨杉数据库总体分为“计算实例层” 和 “分布式数据库层” 两层。和 MySQL 数据库相比,它使用 SequoiaDB 分布式数据库层替代 InnoDB。实例层支持MySQL、PGSQL、SparkSQL等类型的实例,用于语法解析、语义解析、生成执行计划。SequoiaDB 分布式数据库层包括协调节点、编目节点、数据节点三部分,用于数据存储和计算。
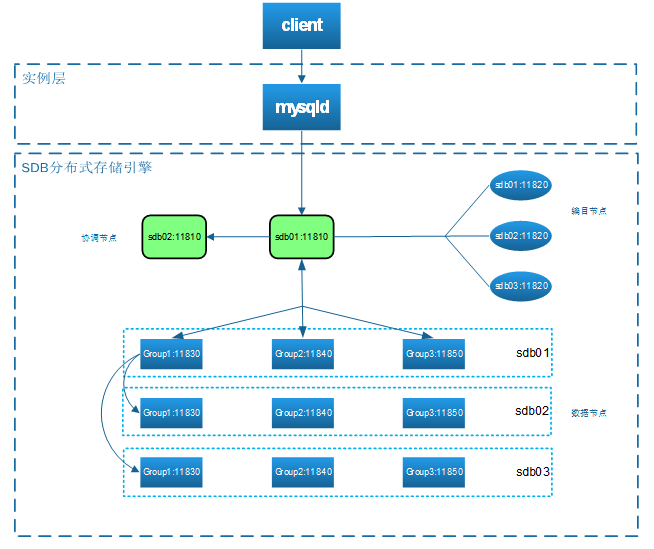
SequoiaDB 巨杉数据库的查询 SQL 语句的执行过程和 MySQL 大体一致,主要的区别在于执行 SQL 语句。下面详细介绍 SequoiaDB 数据库查询 SQL 语句的执行过程。
MySQL实例层解析SQL,生成执行计划,几乎不参与计算。
协调节点承接着与 MySQL 实例层、编目节点、数据节点的交互。
数据节点承担数据计算和数据存储。






