一、概述
在数据作为生产资料的今天,数据早已成为各行各业的生命源泉,数据安全的重要性不言而喻。数据备份是数据安全的基础,完整的备份和有效的恢复手段是应对一切突发状况的重要保障。同时数据备份也对数据的重新利用,发挥数据更大价值,有着重大的作用。
计算与存储分离的架构,也使得巨杉数据库拥有多种多样的备份恢复方法。在巨杉数据库的存储引擎层和SQL实例层都可以达到对数据库备份恢复的目的。
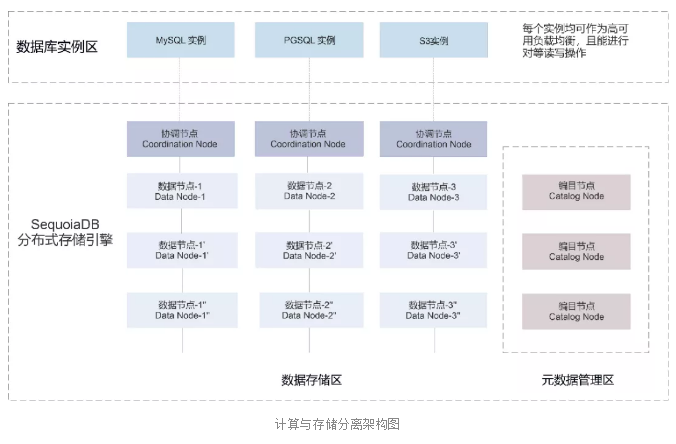
二、存储引擎层的备份恢复
巨杉数据库采用自研的 SequoiaDB 分布式存储引擎,支持物理备份(db.backup)与逻辑备份(sdbexprt)。
物理备份是指转储数据库物理文件(如数据文件、日志文件等),一旦数据库发生故障,可以利用这些文件进行还原;通常可以分为全量备份与增量备份。巨杉数据库物理备份可以针对全库进行或者指定数据组进行;
巨杉数据库做物理备份和恢复工作时,要注意分布式数据库与关系型数据库的不同,即分布式数据库数据恢复会涉及到多台服务器的数据库物理文件,而不只是某一台服务器上的数据库物理文件。逻辑备份是指对数据库对象(如用户、表、存储过程等)利用工具进行导出,同时也可以利用工具把逻辑备份文件导入到数据库。巨杉数据库逻辑备份可以将集合(表)导出为json或者csv 格式,实现快速平滑的迁移。
下面采用3台机器的巨杉数据库集群(3副本),来说明存储引擎层的物理备份恢复方法。
1. 前期准备
主机信息备注:
IP | Hostname | SequoiaDB用户 | 备注 |
192.168.1.3 | sdb03 | sdbadmin | |
| 192.168.1.4 | sdb04 | sdbadmin | |
| 192.168.1.5 | sdb05 | sdbadmin | 备份磁盘(挂载目录/sdbdata/backup) |
通过NFS将备份目录共享
[root@sdb05 ~]# cat /etc/exports/sdbdata/backup *(insecure,rw,sync,no_wdelay,insecure_locks,no_root_squash)[root@sdb03 ~]# mount -t nfs -o rw,bg,hard,nointr,tcp 192.168.1.5:/sdbdata/backup /sdbdata/backup[root@sdb03 ~]# chown -R sdbadmin:sdbadmin_group /sdbdata/backup[root@sdb04 ~]# mount -t nfs -o rw,bg,hard,nointr,tcp 192.168.1.5:/sdbdata/backup /sdbdata/backup[root@sdb04 ~]# chown -R sdbadmin:sdbadmin_group /sdbdata/backup[root@sdb04 ~]# df -hFilesystem Size Used Avail Use% Mounted on/dev/mapper/centos-root 15G 4.4G 11G 29% //dev/vdb 985G 129G 806G 14% /sdbdata/dev/vda1 497M 172M 326M 35% /boot/dev/vda3 50G 13G 38G 26% /opt192.168.1.5:/sdbdata/backup 985G 129G 807G 14% /sdbdata/backup
2. 全量备份
全量备份脚本
[sdbadmin@sdb05 ~]#cat backup_full.sh#!/bin/bashdate/opt/sequoiasql/mysql/bin/mysqldump --login-path=mysql -A -d > /sdbdata/backup/full/create`date +%y%m%d%H`.sql/opt/sequoidb/bin/sdblist -l -m list > /sdbdata/backup/full/sdblist`date +%y%m%d%H`.sql/opt/sequoiadb/bin/sdb 'db=new Sdb()'/opt/sequoiadb/bin/sdb 'db.backup ( { Name : "cluster_backup", Path : "/sdbdata/backup/full/%g", Overwrite : true, Description : "full_backup" } ) ;'datedb.backup()备份常用参数说明Name:备份名称,缺省则以当前时间格式命名,如“2016-01-01-15:00:00”,格式为“YYYY-MM-DD-HH:mm:ss”。Description:备份用户描述信息。Path:本次备份的指定路径,缺省为配置参数“bkuppath”中指定的路径。EnsureInc:备份方式,true 表示增量备份,false 表示全量备份,缺省为 false。OverWrite:对于同名备份是否覆盖,true 表示覆盖,false 表示不覆盖,如果同名则报错;缺省为 false。GroupName:对指定组进行备份,缺省为对全系统备份,当需要对多个组进行备份可以指定为数组类型,如:["datagroup1", "data
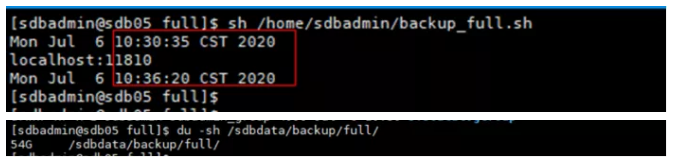
执行全量备份,查看表test100.b 的记录

执行全量备份
增量备份脚本
[sdbadmin@sdb05 ~]#cat backup_incre.sh
#!/bin/bash
date
/opt/sequoiasql/mysql/bin/mysqldump --login-path=mysql -A -d > /sdbdata/backup/full/create`date +%y%m%d%H`.sql
/opt/sequoidb/bin/sdblist -l -m list > /sdbdata/backup/full/sdblist`date +%y%m%d%H`.sql
/opt/sequoiadb/bin/sdb 'db=new Sdb();'
/opt/sequoiadb/bin/sdb 'db.backup ( { Name : "cluster_backup", Path : "/sdbdata/backup/full/%g", EnsureInc : true } );'
date执行增量备份,向表test100.b 中插入100万条数据
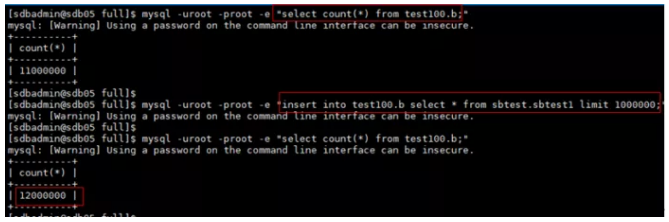
进行增量备份

4. 全量恢复
全量恢复脚本
(1)配置单向ssh 免密服务[sdbadmin@sdb05 ~]#ssh-keygen -t rsa[sdbadmin@sdb05 ~]#ssh-copy-id sdbadmin@sdb03[sdbadmin@sdb05 ~]#ssh-copy-id sdbadmin@sdb04[sdbadmin@sdb05 ~]#ssh-copy-id sdbadmin@sdb05(2)恢复脚本[sdbadmin@sdb05 ~]#cat restore_full.sh#!/bin/bash#停止集群for hostname in {sdb03,sdb04,sdb05}dossh $hostname /opt/sequoiadb/bin/sdbstop -t alldone#全量恢复一份完整的副本数据for groupname in `cat /sdbdata/backup/full/sdblist20200717.sql | awk '{print $8}' | grep -Evi "GroupName|SYSCoord" `do/opt/sequoiadb/bin/sdbrestore -p /sdbdata/backup/full/$groupname/ -n cluster_backup -b 0 -i 0done#删除另外2台服务器之前的副本数据,scp拷贝全量恢复的副本数据for hostname in {sdb03,sdb04}dofor dbpath in `cat /sdbdata/backup/full/sdblist20200717.sql | awk '{print $10}'| grep -Evi "dbpath|*11810"`dossh -t sdbadmin@$hostname "rm -rf "$dbpath*scp -pr $dbpath* $hostname:$dbpath &donedone#启动集群/bin/read -p " Do you want to start SequoiaDB(yes or no)? " Dowhile [[ "$Do" != "no" ]] && [[ "$Do" != "yes" ]]do/bin/read -p "Do you want to start SequoiaDB(yes/no)?" Dodoneif [ "$Do" == "yes" ]thenfor hostname in {sdb03,sdb04,sdb05}dossh $hostname /opt/sequoiadb/bin/sdbstart -t alldoneelif [ "$Do" == "no" ]thenecho "please start SequoiaDB by hand"fisdbrestore数据恢复常用参数:--bkpath -p:备份源数据所在路径。--increaseid -i:需要恢复到第几次增量备份,缺省恢复到最后一次 ( -1 )。--beginincreaseid -b:需要从第几次备份开始恢复,缺省由系统自动计算 ( -1 )。--bkname -n:需要恢复的备份名。--action -a:恢复行为,“restore”表示恢复,“list”表示查看备份信息,缺省为“restore”。--diaglevel -v:恢复工具自身的日志级别,缺省为 WARNING ( 3 )
执行全量恢复,清空test100.b 表的记录
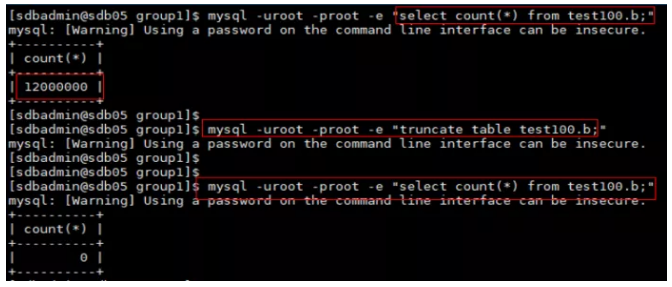
执行全量恢复
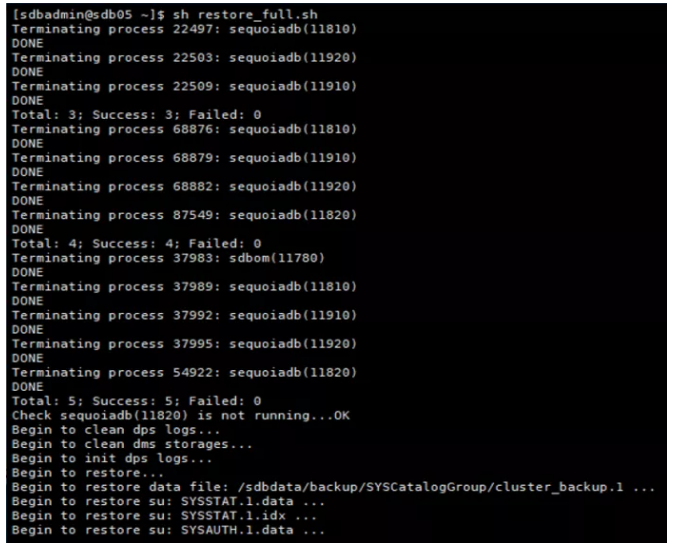
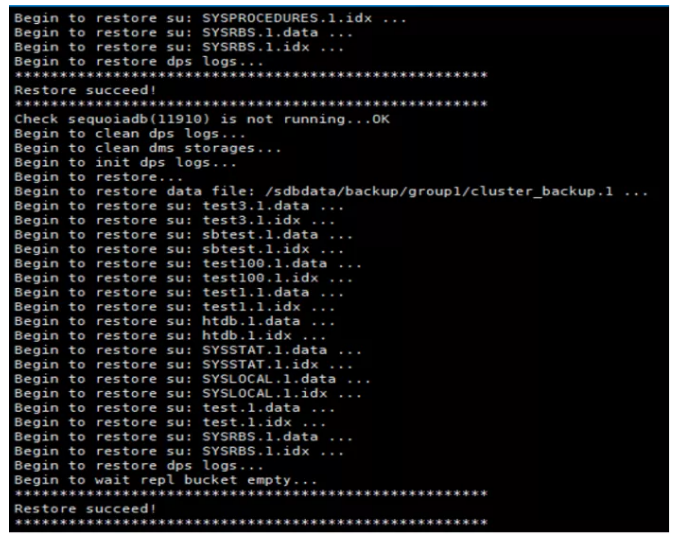
查看全量恢复后test100.b 表的记录条数

5. 增量恢复
增量恢复脚本
[sdbadmin@sdb05 ~]#cat restore_incre.sh#!/bin/bash#停止集群for hostname in {sdb03,sdb04,sdb05}dossh $hostname /opt/sequoiadb/bin/sdbstop -t alldone#增量恢复副本数据for groupname in `cat /sdbdata/backup/full/sdblist20200717.sql | awk '{print $8}' | grep -Evi "GroupName|SYSCoord"`do/opt/sequoiadb/bin/sdbrestore -p /sdbdata/backup/full/$groupname/ -n cluster_backup -b -1done#启动集群/bin/read -p " Do you want to start SequoiaDB(yes or no)? " Dowhile [[ "$Do" != "no" ]] && [[ "$Do" != "yes" ]]do/bin/read -p "Do you want to start SequoiaDB(yes/no)?" Dodoneif [ "$Do" == "yes" ]thenfor hostname in {sdb03,sdb04,sdb05}dossh $hostname /opt/sequoiadb/bin/sdbstart -t alldoneelif [ "$Do" == "no" ]thenecho "please start SequoiaDB by hand"fi
执行增量恢复
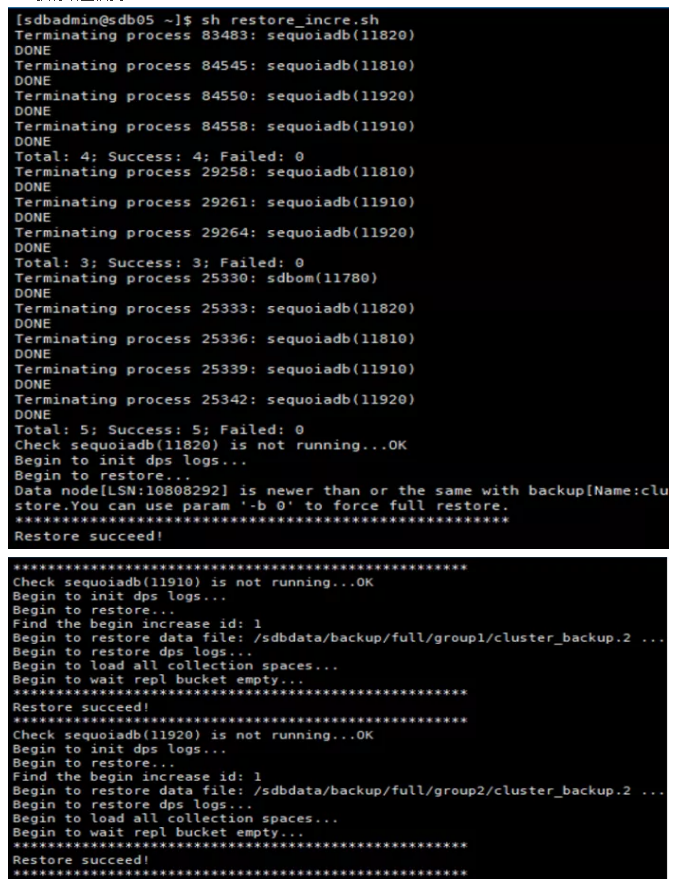
查看增量恢复后test100.b 表的记录条数

增量恢复后,表test100.b数据完全恢复
巨杉数据库自带的逻辑备份恢复工具为 sdbexprt 和 sdbimprt。
1. sdbexprt 工具使用
sdbexprt 常用参数说明
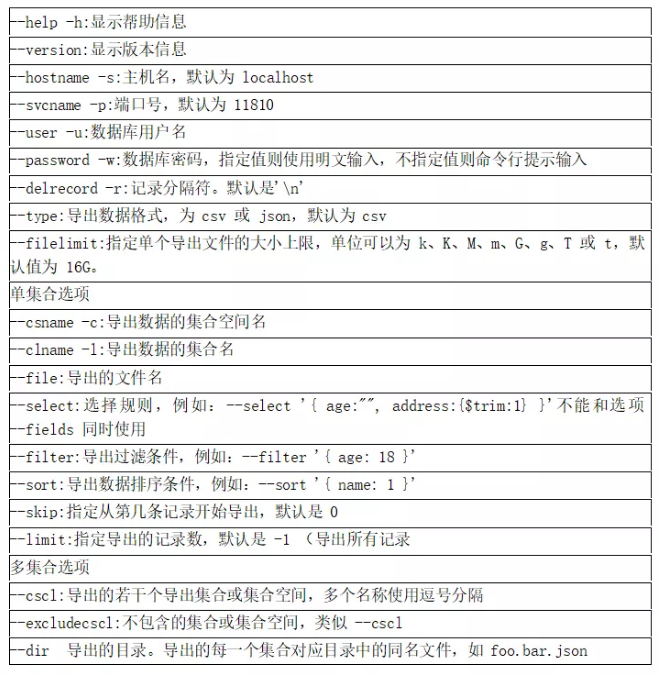
SequoiaDB 采用 json文档类型定义数据存储模型(类对象存储)。逻辑备份恢复采用json格式,更加平滑高效。下面把数据导出 json 格式为例:
(1)导出集合sbtest.sbtest1 的数据sdbexprt \--hostname "localhost" \--svcname "11810" \--user "sdbadmin" \--password "sdbadmin"--type 'json' \--csname 'sbtest' \--clname 'sbtestl' \--file '/tmp/sbtest.sbtest1.json'(2)导出集合空间sbtest下,所有集合的数据sdbexprt \--hostname "localhost" \--svcname "11810" \--user "sdbadmin" \--password "sdbadmin"--type 'json' \--cscl 'sbtest' \--dir '/tmp'
Note: SQL实例层与存储引擎层对应关系为库名等同于底层的集合空间;表名等同于底层的集合。
2. sdbimprt工具使用
sdbimprt 是巨杉数据库自带的数据导入工具,它可以将json格式或csv格式的数据高效平滑的导入到巨杉数据库中。
为了可以最大化提升 I/O 与网络吞吐量,对于百GB级文件建议将数据导入文件切分为多个子文件并且存放于不同服务器,采用多服务器并行加载策略;并且在文件加载过程中使用-j 参数开启多线程。
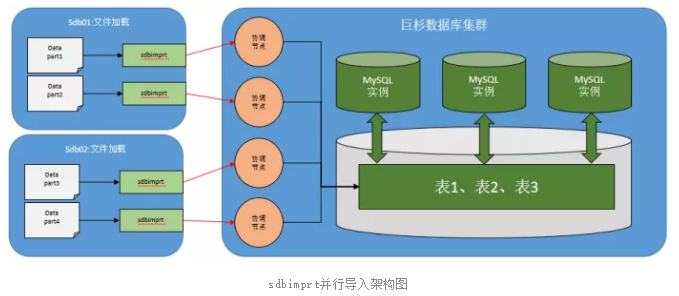
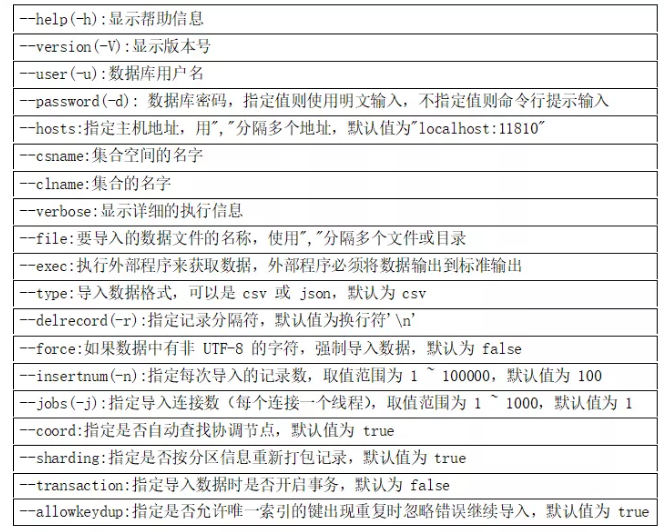
sdbimprt 常用参数说明
下面以导入json 格式数据为例:
sdbimprt \ --hosts 'localhost:11810' \ --user 'sdbadmin' \ --password 'sdbadmin' \ --csname 'sbtest' \ --clname 'sbtest1' \ --insertnum 10000 \ --jobs 20 \ --type 'json' \ --file '/tmp/sbtest.sbtest1.json'--coord false \ --ignorenull true \ --verbose true \ --force false \ --errorstop true \ --sharding true \ --transaction false \ --allowkeydup true
三、SQL 实例层的备份操作
巨杉数据库在联机交易场景下,SQL 实例层主要以 MySQL 为主;原生 MySQL 数据库同样支持物理备份(Xtrabackup等)和逻辑备份(mysqldump、mysqlpump、mydumper)。原生MySQL数据库物理文件只存在于单台服务器与分布式数据库存在较大差异;物理备份工具(Xtrabackup等)并不适用于巨杉数据库SQL实例层。逻辑备份工具(mysqldump、mysqlpump、mydumper)是完全适用的,下面以mysqldump、mydumper 为例进行说明。
1. mysqldump 工具使用
mysqldump 是 MySQL 自带的逻辑备份工具。它的备份原理是,通过协议连接到 MySQL 数据库,将需要备份的数据查询出来,将查询出的数据转换成对应的insert语句。
mysqldump 的优点是简单灵活,数据格式清晰,方便编辑,可以进行不同级别备份。mysqldump 的缺点是备份的过程是串行化的,不能并行的进行备份,速度较慢。
mysqldump 常用参数说明
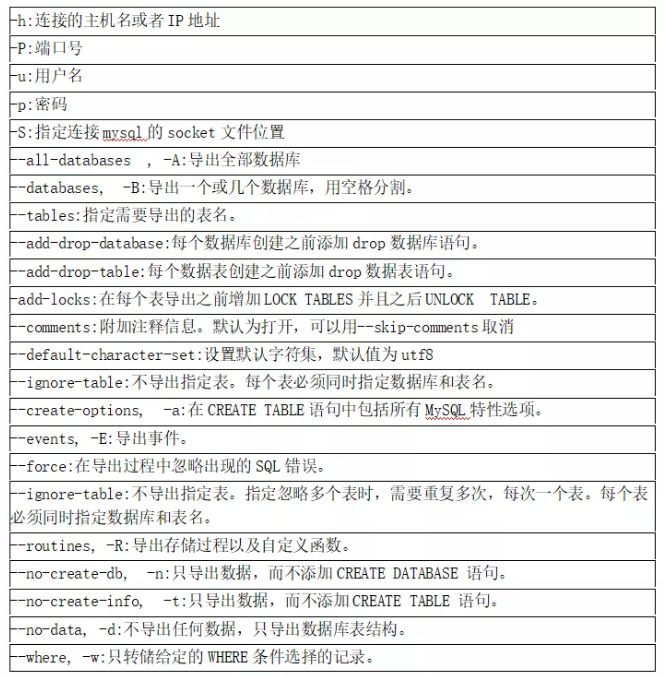
使用mysqldump实现数据库备份,常见场景
(1)备份所有库: mysqldump -h 192.168.3.6 -P 3306 -u root -p root123456 -A > /backup/all.sql (2)备份几个库: mysqldump --h 192.168.3.6 -P 3306 -u root -p root123456 -B 库名1 库名2 > /backup/database.sql (3)备份单个库某几个表(表名用空格隔开即可) Mysqldump -h 192.168.3.6 -P 3306 -u root -p root123456 库名 表名1 表名2> /backup/table.sql (4)mysqldump恢复mysql -h 192.168.3.6 -P 3306 -u root -p root123456 < /backup/all.sql; 或者 MySQL>source /backup/all.sql
2. mydumper&myloader工具使用
mydumper&myloader是用于对MySQL数据库进行多线程备份和恢复的开源 (GNU GPLv3)工具。开发人员主要来自MySQL、Facebook和SkySQL公司,目前由Percona公司开发和维护。
mydumper常用参数说明:

myloader常用参数说明:
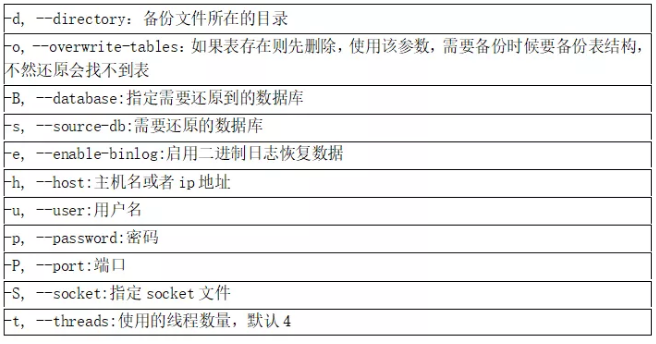
示例:备份恢复sbtest
$time mydumper -h 192.168.3.6 -P 3306 -u root -p root123456 -t 6 -c -e -B sbtest -o /home/data/ $time myloader -h 192.168.3.6 -P 3306 -u root -p root123456 -t 6 -B sbtest -o -d /home/data
小结
除了上文介绍到的一些技术点,我们在实际应用中也可以选择第三方备份软件或者数据备份一体机进行集中的数据备份管理;实现对数据库、文件、操作系统、虚拟机的实时、定时备份。这里大家可以也和我们互动一下,一起分享一下大家使用第三方工具、软件进行数据恢复备份的一些经验。






