身为一个“前浪”开发人员,在疫情期间,我也在持续充实自己,在线上开始学习分布式技术,也因此接触到了巨杉数据库。
整体逻辑
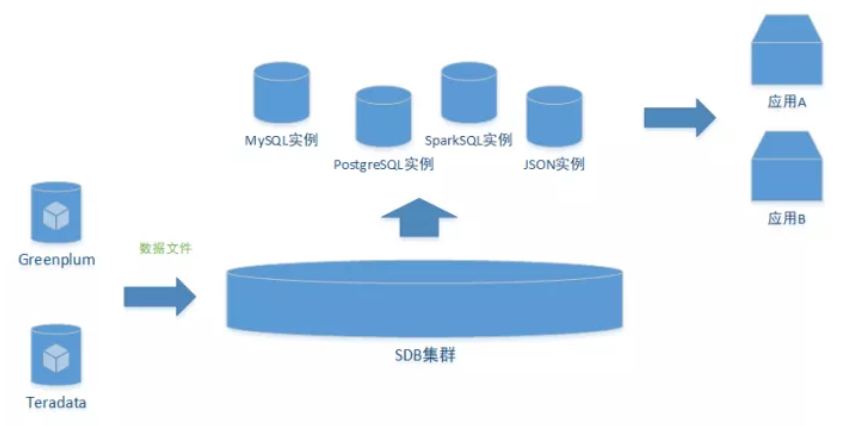
实践过程
步骤1:数据加载
1) 通过文件加载
从Greenplum、Teradata导出的数据文件,为含有自定义分隔符的csv格式数据文件,这种格式的文件,也是主流的数据库导入导出时使用的数据文件。用户可以直接将数据文件导入到 SequoiaDB 集群中去,也可以通过 SequoiaDB 集群上层的各种数据库实例对应的导入工具进行数据导入。
2) 数据不落地直接加载
除了从数据库A导出数据文件,然后向数据B中导入数据文件的这中形式的加载,还可以选择数据不落地的形式加载数据。
通过 SparkSQL 抽取
由于 SequoiaDB 支持在集群上创建 SparkSQL 实例,用户可以向 Spark 集群中提交 SQL 任务,通过 JDBC 连接 Greenplum 和 Teradata,将数据抽取到 SequoiaDB 集群中去。
通过管道连接导入
当数据导入格式是 JSON 时,可以通过管道直连数据库进行导入。例如从其它工具 other 获取数据,导入至集合空间 company 的集合 employee 中,示例如下:
$ other | sdbimprt --hosts=localhost:11810 --type=json -c company -l employee
步骤2:数据存储
在大数据的场景下,用户的业务数据往往有几千万,甚至上亿条记录。在这种场景下,一次简单的查询请求往往需要读取大量的磁盘数据,造成 I/O 的高负载和高时延问题。而在 SequoiaDB 中,通过使用数据分区,可以大大减少读取的数据量,提高数据查询的并发度,从而解决了 I/O 的高负载和高时延问题。在 SequoiaDB 中,通过将集合数据拆分成若干小的数据集进行管理,从而达到并行计算和减小数据访问量的目的。根据管理方式的不同,可以分为以下两种分区类型:
数据库分区:用于描述数据在集合与复制组之间的关系
表分区:用于描述数据在集合与集合之间的关系
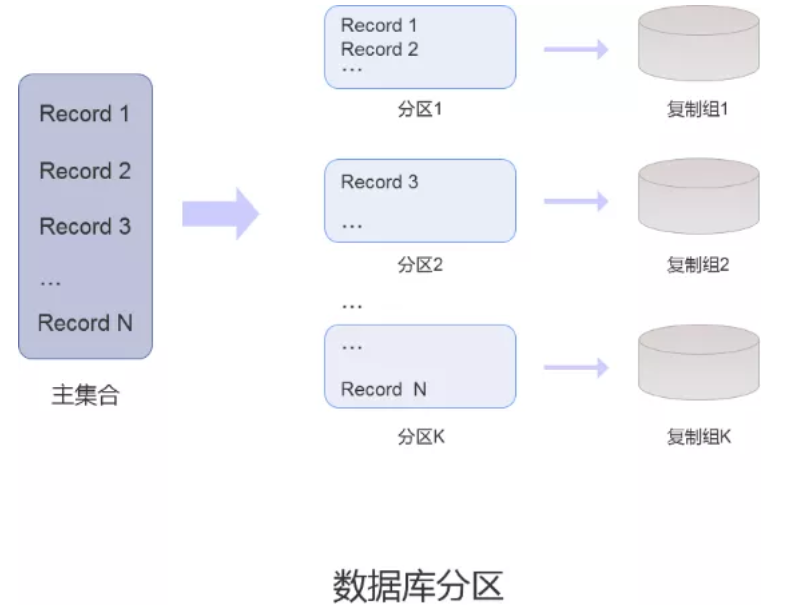
1) 数据库分区
在 SequoiaDB 集群环境中,可以通过将一个集合中的数据划分成若干不相交的子集,再将这些子集切分到复制组中,以达到并行计算的目的,这种数据切分的方法称为数据库分区。而这些不相交的子集称为分区。
![]()
分区内的所有数据记录都是完整的记录
一个分区只能存在于集群中的某一个复制组中,但一个复制组却可以承载多个分区
通过切分操作,可以将分区从一个复制组中移动到另一个复制组中
当同时访问多个分区的数据时,可以同时在分区所在的不同复制组中进行并行计算,从而提高处理速度和性能
2) 表分区
在 SequoiaDB 集群环境中,可以通过将一个集合中的数据划分成若干不相交的子集,再将这些子集映射到另外的集合上,这种数据切分的方法称为表分区。这些不相交的子集称为分区,被数据划分的集合称为主集合,分区映射的集合称为子集合。
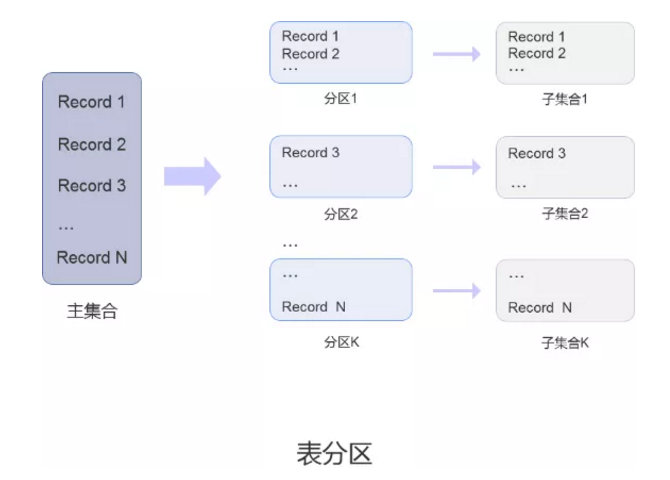
分区内的所有数据记录都是完整的记录
一个分区只能映射到一个子集合中
通过集合挂载操作,可以将分区从一个子集合中映射到另外一个子集合中
当需要访问某个特定范围内的记录时,只会访问所属分区的子集合,避免访问所有分区数据,从而减少了数据访问量
由于巨杉数据库支持创建 SparkSQL 实例,而 Spark 在数据加工场景中被广泛使用,所以 SequoiaDB 集群具备一些简单的数据加工能力。用户可以将加工任务提交到 Spark 集群,Spark 集群连接 SequoiaDB 集群,进行任务的跑批。
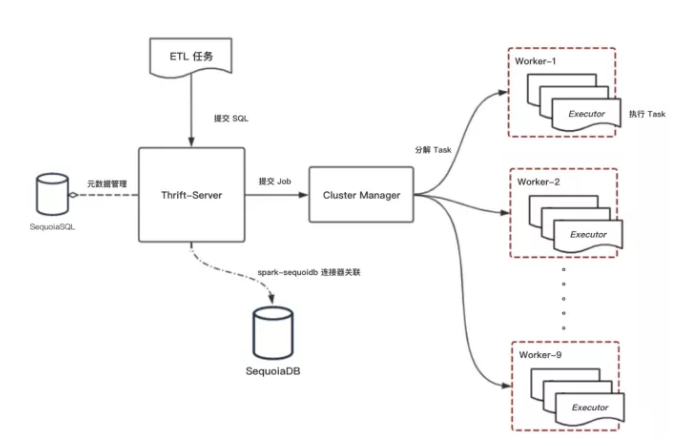
SequoiaDB 集群支持多种实例,例如 MySQL、PostgreSQL、SparkSQL 和 JSON 等主流数据库实例类型,并兼容实例的相关语法。多实例的支持,使得下游应用在对数仓数据进行查询时,连接方式多样化。尤其在系统改造过程中,我们可以依照原系统使用的数据库类型创建实例,对于应用来说是无感知的。
MySQL实例访问
MySQL 是一款开源的关系型数据库管理系统,也是目前最流行的关系型数据库管理系统之一,支持标准的 SQL 语言。SequoiaDB 支持创建 MySQL 实例,完全兼容 MySQL 语法和协议,用户可以使用 SQL 语句访问 SequoiaDB 数据库,完成对数据的增、删、查、改操作以及其他 MySQL 语法操作。
PostgreSQL实例访问
PostgreSQL 是一款开源的关系型数据库,支持标准 SQL,用户可以通过 JDBC 驱动连接 PostgreSQL 进行应用程序开发。SequoiaDB 支持创建 PostgreSQL 实例,完全兼容 PostgreSQL 语法,用户可以使用 SQL 语句访问 SequoiaDB,完成对数据的增、删、查、改及其他操作。
此外,相对于 MySQL 实例,PostgreSQL 在关联查询中,能够支持 Hash Join,在某些场景下具备一定的优势。
SparkSQL实例访问
对于一些计算较多的查询语句,建议通过 SparkSQL 进行查询。如果用户想使用JDBC,也是可以的,直接通过Hive驱动就可以进行数据库的连接和使用了。
JSON实例访问
SequoiaDB 巨杉数据库为用户提供了 JSON 实例, 通过此实例可以与 SequoiaDB 巨杉数据库的分布式引擎进行交互执行。JSON 实例与时下流行的 MongoDB 数据库语法相似,且数据格式都为 JSON 格式。JSON 实例适用于基于 JSON 数据类型的联机业务场景。用户可以使用 JSON 实例对数据库执行集群管理、运行实例检查、数据增删改查等操作。
体验分享
数仓导出分布式数据库提供实时访问查询,是当前企业中经常遇到的一个场景需求,希望本文可以提供一些简单的分享,帮助大家更好处理这类需求场景。
1) 巨杉在支持 SQL 这块做的还不错,终端应用通过几种不同的方式都能顺利快速的获取数据,兼容性这块要赞一个。
2) 数据存储方式,分布式的数据存储说实话是第一次接触,一开始挺懵的。后来去学习了一下巨杉的在线课程之后,终于算是搞明白了。这块也建议大家要认真学习一下,因为传统IT人可能理解上会有一些偏差。
3) 数据加载:这块我们是在社区和巨杉的同学聊了一下,他们提供了一些实践方案,我这边就照着他们的指导尝试了不同的方式,对比我也写在文中了。
最后,也希望国内的技术可以越做越好,作为“前浪”IT人,确实这几年很高兴见到了国内有越来越多的软件产品出现,未来我们也会多多支持国内的技术产品!






