近年来,银行各项业务发展迅猛,客户数目不断增加,后台服务系统压力也越来越大,系统的各项硬件资源也变得非常紧张。因此,在技术风险可控的基础上,希望引入大数据技术,利用大数据技术优化现有IT系统实现升级改造,搭建一个统一存储和管理历史、近线数据的服务平台,同时能够对外支持高并发、低延时的数据查询服务,以提高IT系统的计算能力,降低IT系统的建设成本,优化IT系统的服务体系,为各个业务部门提供更加优质的IT服务。
这类服务平台在整个IT系统架构中实质上是一个为联机业务系统减负的系统。SequoiaDB 巨杉数据库是一款开源的金融级分布式关系型数据库,主要对高并发联机交易型场景提供高性能、可靠稳定以及无限水平扩展的数据库服务。用户可以在 SequoiaDB 巨杉数据库中创建多种类型的数据库实例,如MySQL、PostgreSQL 与 SparkSQL,以满足上层不同应用程序各自的需求。SequoiaDB巨杉数据库支持海量分布式数据存储,并且支持垂直分区和水平分区,利用这些特性可以将历史、近线数据存储到SequoiaDB中,并能够对外支持高并发、低延时的数据查询服务。
目前,巨杉数据库已经成为许多银行大数据平台的一个重要组成部分,承担着历史数据平台、影像平台等多个重要业务的支撑工作。
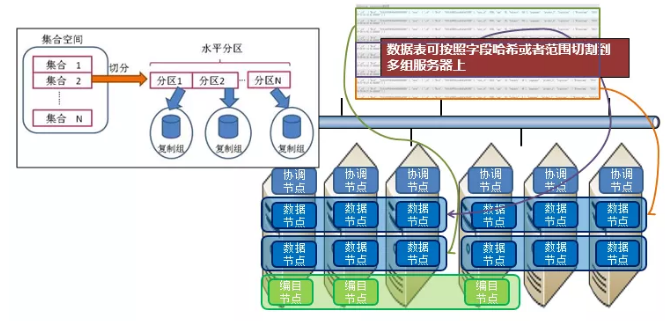
水平分区
垂直分区
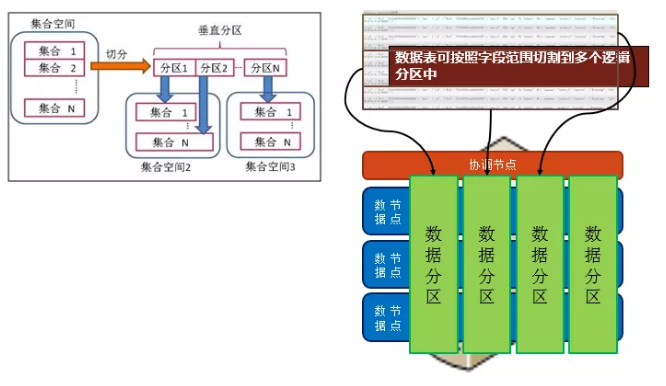
垂直分区是指在一个节点内集合数据按某字段,分成成多个数据段。每个范围代表一个垂直分区。数据查询、写入时自动分发至相应分区中。垂直分区极大减少硬盘数据访问,降低网络I/O,加速查询。垂直分区共享资源(同一台物理机),出发点在于将冷热数据隔离,如图所示:
1.2 复制组和域
分区组又被称为复制组,一个复制组内可以包含一个或多个数据节点(或编目节点),节点之间的数据使用异步日志复制机制,保持最终一致。
域(Domain)是由若干个复制组(ReplicaGroup)组成的逻辑单元。每个域都可以根据定义好的策略自动管理所属数据,如数据切片和数据隔离等。
以3台服务器为例,每台服务器9块磁盘。复制组的物理部署和域的逻辑组成如图所示:
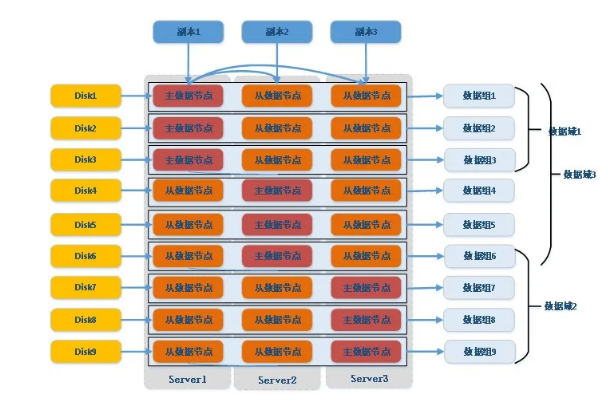
采用3副本,按磁盘部署数据节点,每台机器部署9个数据节点,3台机器横向组成数据组,共9个数据组。如图域1包括数据组1-3,域2包括数据组5-9,域3包括数据组1-6,因此域在逻辑上由数据组组成,并且组成的数据组可以重叠。
随着用户的增加、业务的发展,银行业务系统的数据量越来越大,而且原有系统绝大部分基于关系型数据构建,表结构复杂,每个查询都需要关联若干张大数据表,导致关联查询的性能非常低。因此可以利用SequoiaDB存储海量历史、近线数据并开发数据查询统一入口,按照数据生命周期管理的规则对历史、近线数据进行统一在线存储。另外平台提供高并发、实时查询服务,解决了关系型数据库海量数据关联查询性能慢的问题。
根据业务系统历史、近线数据的需求,建立历史、近线数据存储区用于存储从源系统直接导入的原始数据,包括超出生产系统保存期限的数据以及需要按时点备份的数据。同时为提供在线、中高并发,小结果集的数据处理能力,可根据源系统不同划分多个存储区域,集群内部使用划分数据域的方式进行分类管理。
SequoiaDB 在集群的管理上定义了数据域概念,一个数据域可以将多个数据组包含进来。一个集群可以根据不同的业务系统来划分不同的数据域,不仅实现将不同业务系统数据在物理层面的隔离存储,同时也实现了不同业务系统数据的统一调度管理,而且以后的集群扩容也可以根据域的使用需求而只针对此域进行集群扩容。
所以在进行扩容时,我们需要结合 SequoiaDB 数据域和业务系统需求进行扩容规划及实施。结构化数据在扩容时,可针对结构化数据所在数据域增加数据组再进行数据均衡切分到新扩容的机器上或者使子表所属数据组在新扩容机器的数据组上;非结构化数据表创建时所属数据组直接指定到新扩容机器的数据组上。
根据数据调研信息对业务系统进行分类,以确定业务系统的存储量、并发大小、数据生命周期等,为结构化数据在巨杉数据库中的存储规划提供信息支撑。业务系统结构化数据存储到巨杉数据库可利用数据域技术对业务系统的数据区域进行功能划分,具体划分方式如下:
这类业务系统的特点是业务查询并发较大,数据所占存储空间较大,对cpu、内存、网络要求较高,利用域对这类系统进行隔离,可以使数据在写入、读取时充分利用集群中域所在机器的物理资源以提升性能。
这类业务系统一般对cpu、内存、网络要求较低,所占存储空间较小。因此这类系统可以和其他并发、所占存储较小的业务系统的数据域共享数据组以节省机器资源。
对业务系统的结构化数据和非结构化分开存储,即结构化数据存储的数据组与非结构化数据的数据组不相同,防止在同一个数据组中高并发写入、读取时产生的IO争用。
银行部分业务系统存在夜间以跑批的方式将非结构化数据通过接入平台写入到巨杉数据库中,这类系统在跑批会产生大量的网络请求和IO,对服务器的流量和磁盘IO有较高要求,可以对这些系统进行物理隔离,在规划时应该利用域进行物理隔离并且域中的数据组不共享,使其独占集群中部分硬件资源提升跑批性能。
db.createDomain( <name>, <groups>, [options] )
创建一个域,包含两个复制组:
db.createDomain( 'mydomain', [ 'group1', 'group2' ] )
创建一个域,包含两个复制组,并且指定自动切分。
db.createDomain( 'mydomain', [ 'group1', 'group2' ], { AutoSplit: true } )3.2 列出域
枚举系统中所有由用户创建的域。
db.listDomains()
3.3 获取指定域
db.getDomain( <name> )
3.4 删除域
db.dropDomain( <name> )
删除一个之前创建的域:
db.dropDomain( 'mydomain' )
删除一个包含集合空间的域,返回错误:
> db.dropDomain( 'hello' ) (nofile):0 uncaught exception: -256 > getLastErrMsg( -256 ) Domain is not empty
3.5 更改域的属性
domain.alter( <options> )
示例1:
1.首先创建一个域,包含两个复制组,开启自动切分
var domain = db.createDomain( 'mydomain', ['data1', 'data2'], { AutoSplit: true } )v2.从域中删除一个复制组 data2,添加另一个复制组 data3,最后域中包含 data1 和 data3 两个复制组
domain.alter( { Groups: ['data1', 'data3'] } )var domain = db.createDomain( 'mydomain', ['group1'] )
2.从域中删除原复制组,添加另一个复制组,将因把拥有数据的 group1 从域中删除而报错。
domain.alter( { Groups: ['group2'] } )
(nofile):0 uncaught exception: -256
Domain is not emptyvar catalog=new Sdb
catalog.SYSCAT.SYSCOLLECTIONSPACES.find({“NAME”:”bs_customer”}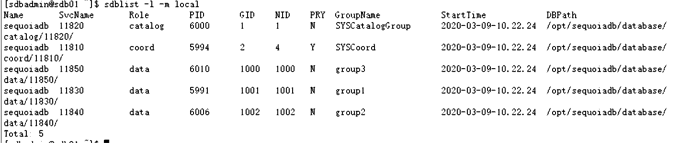
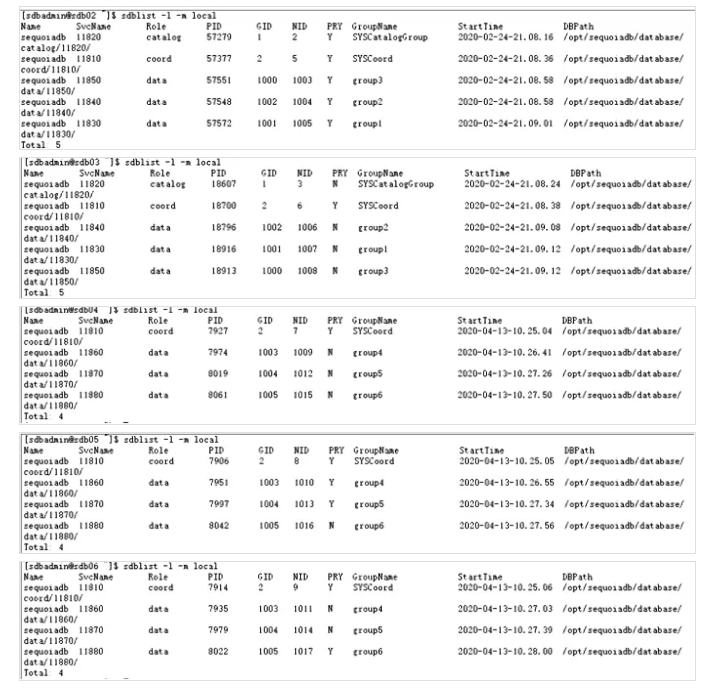
4.2 创建数据域
在sdb上创建两个数据域d2018和d2019。其中,d2018对应group1,group2和group3这三个数据组,d2019对应group4,group5和group6这三个数据组。
db.createDomain("d2018",["group1","group2","group3"])
db.createDomain("d2019",["group4","group5","group6"])
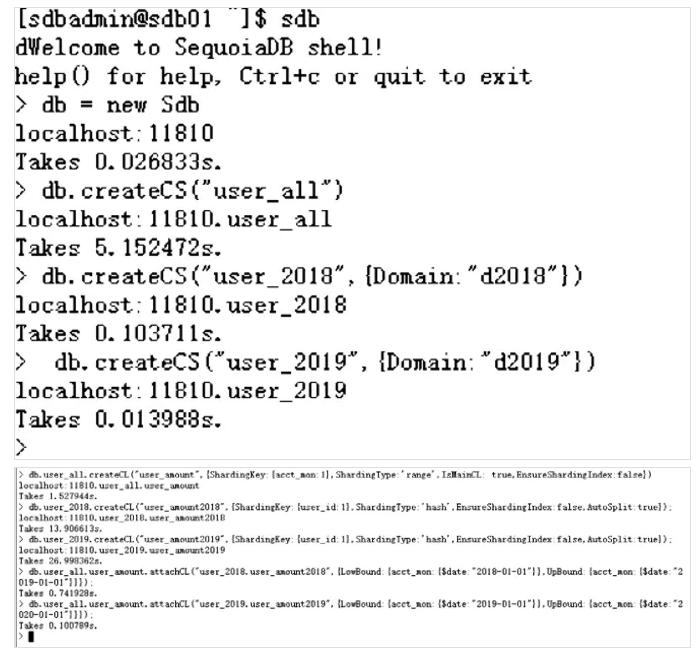
在sdb上创建集合空间和集合
db.createCS("user_all")db.createCS("user_2018",{Domain:"d2018"})db.createCS("user_2019",{Domain:"d2019"})db.user_all.createCL("user_amount",{ShardingKey:{acct_mon:1},ShardingType:'range',IsMainCL: true,EnsureShardingIndex:false})db.user_2018.createCL("user_amount2018",{ShardingKey:{user_id:1},ShardingType:'hash',EnsureShardingIndex:false,AutoSplit:true});db.user_2019.createCL("user_amount2019",{ShardingKey:{user_id:1},ShardingType:'hash',EnsureShardingIndex:false,AutoSplit:true});db.user_all.user_amount.attachCL("user_2018.user_amount2018",{LowBound:{acct_mon:{$date:"2018-01-01"}},UpBound:{acct_mon:{$date:"2019-01-01"}}});db.user_all.user_amount.attachCL("user_2019.user_amount2019",{LowBound:{acct_mon:{$date:"2019-01-01"}},UpBound:{acct_mon:{$date:"2020-01-01"}}});
create database user_all;
use user_all;
create table user_amount
( user_id int not null ,
acct_mon date not null ,
amount int not null )
COMMENT="sequoiadb:{table_options:{ShardingKey:{acct_mon:1},ShardingType:'range',IsMainCL: true,EnsureShardingIndex:false}}" ;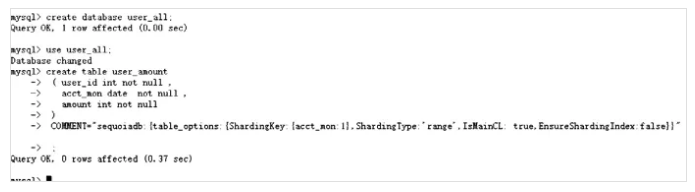
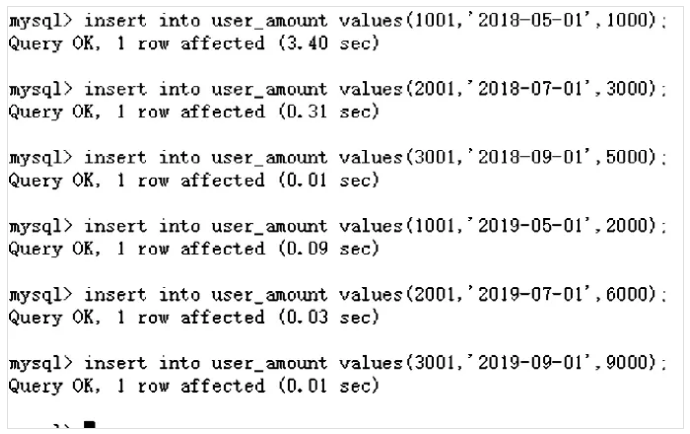
insert into user_amount values(1001,'2018-05-01',1000); insert into user_amount values(2001,'2018-07-01',3000); insert into user_amount values(3001,'2018-09-01',5000); insert into user_amount values(1001,'2019-05-01',2000); insert into user_amount values(2001,'2019-07-01',6000); insert into user_amount values(3001,'2019-09-01',9000);
db = new Sdb("sdb01",11830)
db.user_2018.user_amount2018.find()
db = new Sdb("sdb01",11840)
db.user_2018.user_amount2018.find()
db = new Sdb("sdb01",11850)
db.user_2018.user_amount2018.find()
db = new Sdb("sdb04",11860)
db.user_2019.user_amount2019.find()
db = new Sdb("sdb04",11870)
db.user_2019.user_amount2019.find()
db = new Sdb("sdb04",11880)
db.user_2019.user_amount2019.find()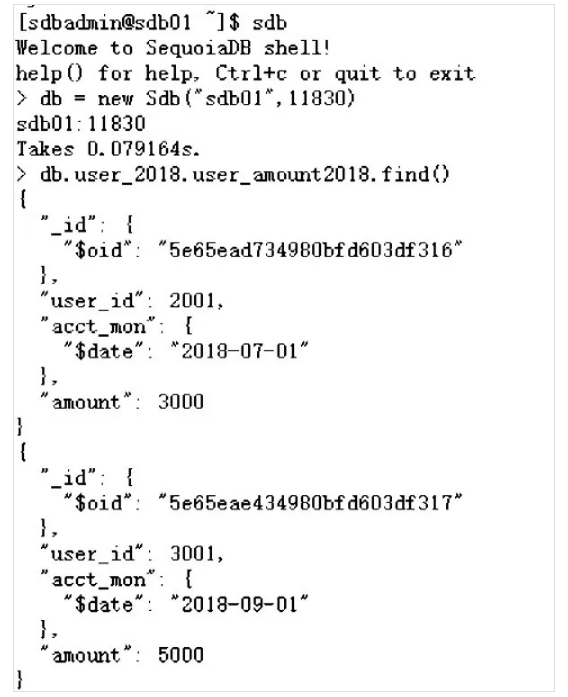
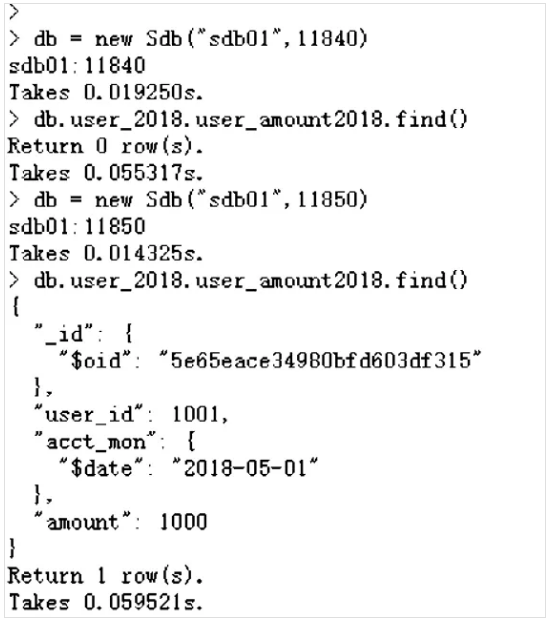
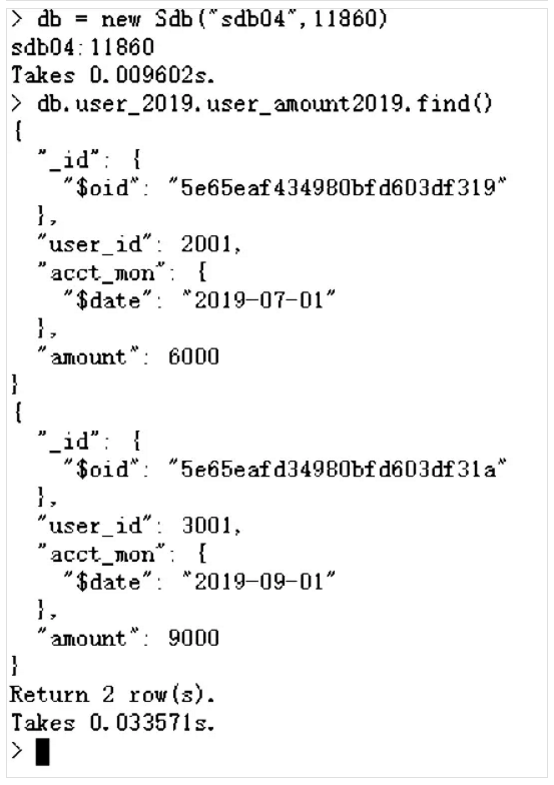
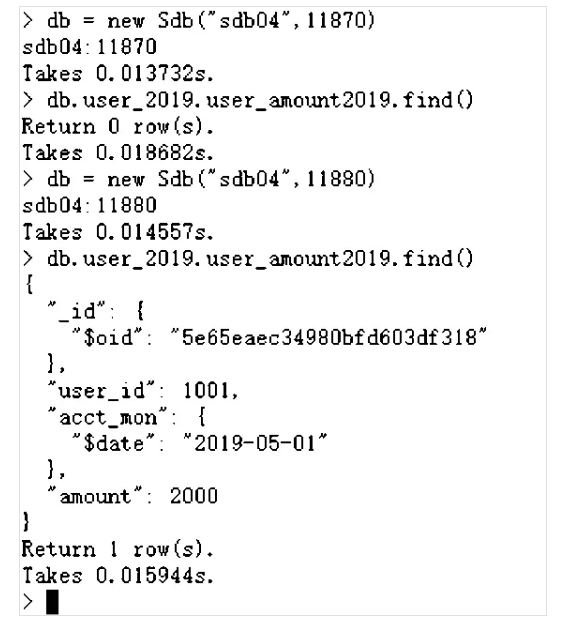
从上述截图可以看出,user_id为2001和3001的用户,其2018年的余额数据在11830这个数据节点上,该节点对应数据组group1,部署在sdb01,sdb02和sdb03这三台主机上。这两个用户2019年的余额数据部署在11860这个数据节点上,该节点对应数据组group4,部署在sdb04,sdb05和sdb06这三台主机上。user_id为1001的用户情况类似,其2018年的余额数据部署在sdb01,sdb02和sdb03这三台主机上,其2019年的余额数据部署在sdb04,sdb05和sdb06这三台主机上。
从上述操作演示可以看出,通过数据域可以很方便的将不同时间周期的数据存放到不同的主机上。当2020的数据即将生成时,只需在新扩的主机上创建相应的子表,然后在挂载到主表user_amount上,即可存放2020年的用户余额数据。






