由于业务形式的发展,越来越多的需求需要对交易数据进行实时分析,例如推荐、决策、监控等,传统的处理办法是使用ETL的方式联机业务产生的数据同步到分析业务的数据库,导致了数据需要在不同的数据库之间流转,耗费时间成本的同时需要耗费人力成本运维多套数据库产品。
混合负载意味着一个数据库既能支持在线事务处理,又能支持在线分析处理,从而满足大部分企业级应用的需求。相比传统使用多款数据库进行不同的业务处理方式,混合负载数据库能够避免传统复杂的ETL过程,省去数据在不同数据库之间的流转时间;同时避免维护多一套用于分析的数据库,从而节省人力和时间的成本,提高数据的价值。
SequoiaDB巨杉数据库采用“计算存储分离”架构,支持MySQL、PostgreSQL与SparkSQL三种关系型数据库实例、JSON文档类数据库实例、以及S3对象存储非结构化数据实例。在事务场景可以利用SDBAPI、MySQL和PGSQL实例对数据进行操作,在分析场景借助分布式计算框架Spark的并发计算性能,提高计算效率。
巨杉数据库作为一款优秀的混合负载数据库有着许多技术优势:分布式多节点、支持索引、基于代价的优化器、对应用透明的数据分片、高性能与无限水平弹性扩展能力、分布式事务与 ACID 能力、标准SQL兼容、多种物理与逻辑的资源隔离能力。
联机业务关注的是实时在线业务,要求是支持事务、低延时、高吞吐量。而分析业务主要是报表分析等大规模数据分析场景,所以更关注的是数据库的存储和计算能力。结合这两种业务的特点,能够看出SequoiaDB 巨杉数据库的在混合负载场景下的明显优势。本文介绍SequoiaDB巨杉数据结合MySQL和Spark引擎在混合负载场景下最佳实践及性能测试。
服务器分布
服务器 | 服务名称 |
192.168.106.151 | sdbserver1 |
192.168.106.152 | sdbserver2 |
192.168.106.153 | sdbserver3 |
服务器配置
虚拟机数量:3台 | |
CPU | 4CORE |
内存 | 8GB |
磁盘 | 100GB*3 |
操作系统 | Centos 7.4 |
2) 软件配置
操作系统:Centos7.4
JDK版本:1.8.0_80 64位
SequoiaDB版本:3.4
MySQL版本:5.7.24
Spark版本:2.3.4
Sysbench版本:1.0.19
TPC-DS_tools版本: 2.10.0
本文以三台虚拟服务器进行实践,下图为部署的物理架构:
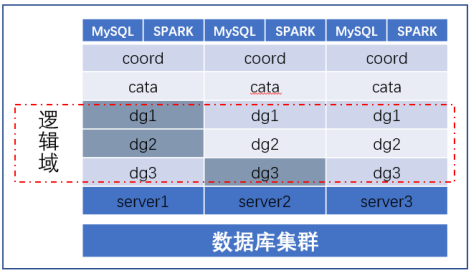
图1 部署架构
本部署架构每台服务均部署了MySQL和Spark实例。部署多个MySQL能够均衡联机事务交易请求,同时避免单点故障。Spark计算引擎在每台机器也部署了计算节点,增强其分析能力。但是需要均衡在线事务处理和在线分析处理进程之间资源。SequoiaDB巨杉数据库在每个磁盘均部署了数据节点,能够充分利用磁盘的读写能力,在Spark计算引擎读写繁忙的情况下,会产生较大的网络传输从而侵占MySQL实例在线事务处理的带宽资源,所以生产环境下Spark和MySQL实例可以配置使用不同的网卡。
1、解压mysql安装包
tar -zxvf sequoiasql-mysql-3.4-linux_x86_64-enterprise-installer.tar.gz
2、运行安装程序(安装MySQL实例需要root用户),后根据提示设置。
./sequoiasql-mysql-3.4-linux_x86_64-enterprise-installer.run --mode text
3、切换用户和目录
su - sdbadmin
4、进入MySQL安装目录
cd /opt/sequoiasql/mysql
5、添加实例
bin/sdb_sql_ctl addinst myinst -D database/3306/
6、查看实例状态
bin/sdb_sql_ctl status
7、配置 SequoiaDB 连接地址
bin/sdb_sql_ctl chconf myinst --sdb-conn-addr=sdbserver1:11810,sdbserver2:11810,sdbserver3:11810
8、登录MySQL Shell
bin/mysql -S database/3306/mysqld.sock -u root
9、设置远程连接
mysql> UPDATE mysql.user SET host='%' WHERE user='root'; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> FLUSH PRIVILEGES; Query OK, 0 rows affected (0.00 sec)
10、设置MySQL的root用户密码
ALTER USER root@'%' IDENTIFIED BY 'xxxxxx';
11、重新登录MySQL Shell
bin/mysql -S database/3306/mysqld.sock -u root -p
12、设置SequoiaDB 存储引擎的用户密码
mysql> SET GLOBAL sequoiadb_user="sdbapp"; Query OK, 0 rows affected (0.00 sec) mysql> SET GLOBAL sequoiadb_password="xxxxxx"; Query OK, 0 rows affected (0.00 sec)
12、创建数据库实例
mysql> CREATE DATABASE company; Query OK, 1 row affected (0.00 sec) mysql> USE company; Database changed
13、创建表
CREATE TABLE employee(id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(128), age INT);
14、插入数据
mysql> INSERT INTO employee(name, age) VALUES("Jacky", 36);15、查询数据
mysql> SELECT * FROM employee; +----+-------+------+ | id | name | age | +----+-------+------+ | 1 | Jacky | 36 | +----+-------+------+ 1 row in set (0.01 sec)
16、使用巨杉数据库shell模式查询数据
sdb> db.company.employee.find()
{
"_id": {
"$oid": "5e06e9fe9e042335be553af6"
},
"name": "Jacky",
"age": 36,
"id": 1
}
Return 1 row(s).
Takes 0.000794s.17、三台服务器均安装MySQL实例后需要进行元数据同步配置
请参考巨杉数据库官网进行配置:http://doc.sequoiadb.com/cn/sequoiadb-cat_id-1572505575-edition_id-0
3.4 Spark部署
1、从spark官网下载使用(sdbadmin用户)
wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
2、解压到opt目录下
tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz -C /opt
3、进入配置文件conf目录
cd /opt/spark-2.4.4-bin-hadoop2.7/conf
4、设置spark-env.sh
SPARK_WORKER_INSTANCES=2 SPARK_MASTER_IP=192.168.106.151
5、设置spark-defaults.conf
spark.sql.cbo.enabled true spark.sql.cbo.joinReorder.dp.star.filter true spark.sql.cbo.joinReorder.dp.threshold 1024 spark.sql.cbo.joinReorder.enabled true spark.sql.cbo.starSchemaDetection true spark.sql.crossJoin.enabled true
6、设置slaves
sdbserver1 sdbserver2 sdbserver3
7、创建设置元数据数据库配置文件hive-site.xml
<configuration> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://sdbserver1:3306/metastore</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>xxxxxx</value> </property> <property> <name>datanucleus.autoCreateSchema</name> <value>true</value> <description>creates necessary schema on a startup if one doesn't exist. set this to false, after creating it once</description> </property> </configuration>
8、拷贝驱动到spark的jars目录下,拷贝sequoiadb 和spark的连接驱动
cp /opt/sequoiadb/spark/spark-sequoiadb_2.11-3.4.jar /opt/spark-2.4.4-bin-hadoop2.7/jars/
拷贝mysql驱动(mysql驱动需要到mysql官网下载)
cp /home/sdbadmin/mysql-connector-java-5.1.47.jar /opt/spark-2.4.4-bin-hadoop2.7/jars/
拷贝sequoiadb的java驱动
cp /opt/sequoiadb/java/sequoiadb-driver-3.4.jar /opt/spark-2.4.4-bin-hadoop2.7/jars/
9、进入MySQL Shell,创建元数据库
mysql> CREATE DATABASE metastore CHARACTER SET 'latin1' COLLATE 'latin1_bin';
10、设置免密
三台机器均执行ssh-keygen生成公钥和密钥
ssh-keygen
在sdbserver1机器执行ssh-copy-id,把公钥拷贝到其他两台机器
ssh-copy-id sdbadmin@sdbserver1 ssh-copy-id sdbadmin@sdbserver2 ssh-copy-id sdbadmin@sdbserver3
11、分发Spark到另外两台机器
scp -r /opt/spark-2.4.4-bin-hadoop2.7 sdbadmin@sdbserver2:/opt/ scp -r /opt/spark-2.4.4-bin-hadoop2.7 sdbadmin@sdbserver3:/opt/
12、启动Spark
/opt/spark-2.4.4-bin-hadoop2.7/sbin/start-all.sh
13、启动thriftserver
/opt/spark-2.4.4-bin-hadoop2.7/sbin/start-thriftserver.sh --master spark://sdbserver1:7077 --executor-cores 2 --total-executor-cores 12 --executor-memory 2g
14、进入beeline测试sql
/opt/spark-2.4.4-bin-hadoop2.7/bin/beeline
15、连接thriftserver
beeline> !connect jdbc:hive2://localhost:10000
16、创建Spark-sql映射表
0: jdbc:hive2://localhost:10000> create database company; 0: jdbc:hive2://localhost:10000>create table company.employee( id int, name string, age int ) using com.sequoiadb.spark OPTIONS ( host 'sdbserver1:11810,sdbserver2:11810,sdbserver3:11810' ,collectionspace 'company', collection 'employee', username 'sdbapp',password 'xxxxxx');
17、运行分析类SQL,测试是否部署对接成功。
0: jdbc:hive2://localhost:10000> select avg(age) from company.employee; +-----------+--+ | avg(age) | +-----------+--+ | 36.0 | +-----------+--+ 1 row selected (1.838 seconds)
四、 性能测试
4.1 混合交易分析业务管理场景测试
为了测试联机业务和分析业务同时运行时对集群性能的影响,使用MySQL基准测试工具Sysbench进行测试MySQL,使用TPC-DS决策支持系统测试基准测试Spark-sql。本次Sysbench测试场景有:读写(oltp_read_write)、点查(oltp_point_select)、索引更新(oltp_update_index)三个场景。TPC-DS测试场景选取99条SQL中的前30条进行测试,测试案例包含了较高的IO负载和CPU计算需求,同时具有利用巨杉数据库的特性对数据进行优化的特点。
测试结果如下:
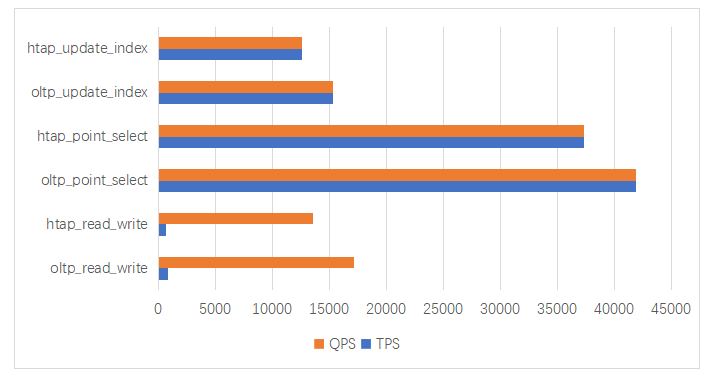
图2 联机业务和混合交易分析业务管理场景下Sysbench的测试结果
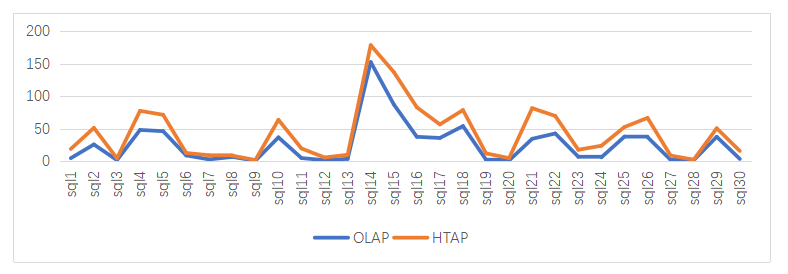
图3 分析业务和混合交易分析业务管理场景下TPC-DS的测试结果
通过上面图表展示的测试结果,可以看到联机业务与分析业务和混合交易分析业务管理场景下的对比,可以出SequoiaDB巨杉数据库在混合交易分析业务管理混合场景下依然能表现优异性能,对各自场景性能影响较小。
5.1 数据存储规划
根据复制组和域的概念实现的资源隔离与分区方式结合,可以把不同的数据类型使用域的逻辑概念把复制组进行隔离,然后使用适当的分区方式把数据打散到不同的复制组。
基于多租户架构规划:一个数据库通常承载着多种业务系统,为了避免不同业务之间的性能影响,根据业务系统的存储量、并发大小、数据生命周期等划分不同的数据域承载相应的数据读写。
基于数据分区方式规划:结合当前表的数据特性选择合适的分区方式,如:
1、档案类数据类数据 ,可以使用水平分区按ID散列到不同的数据组保证数据均衡无热点。
2、流水类数据选择混合分区的方式创建多维分区表进行存放,把不同时间段的数据分布在不同的数据组。多维分区表的好处有:1、当访问某时间范围的数据能够直接定位到子分区,避免扫描全表数据从而降低IO。2、在集群扩容时,把扩展的子表创建在新的机器,无需执行rebalance的操作即可完成表存储空间的扩容。
5.2 SequoiaSQL-MySQL优化
1、高可用。集群的MySQL实例均可以提高读写操作,由于各实例的元数据均只存储在该实例本身,SequoiaSQL-MySQL 提供了元数据同步工具,用来保证 MySQL 服务的高可用。同步工具及部署操作可以参考官网。
2、提高MySQL实例最大连接数。
3、为每个MySQL实例配置多个协调节点,均衡协调节点压力,防止单个协调节点失效,引发MySQL实例单点故障。
4、其他优化项详细可参照巨杉数据库官网的配置项列表。
5.3 Spark计算引擎优化
1、Spark开启CBO基于代价的优化,根据数据的特点选择代价最小的物理执行计划,决定是否进行广播优化。
2、适当增大WORKER的数量,设置合理的WORKER核数和内存。
3、选择高效的序列化方式。默认为org.apache.spark.serializer.JavaSerializer,但是为了提升性能,应该选择org.apache.spark.serializer.KryoSerializer 序列化。
4、设置合理的shuffle分区数,使shuffle后的数据能够加入更多的的task数量,从而提高SQL执行的并行度。
5、设置Spark读取数的节点为从节点,避免从主节点读取大量数据造成压力。
SequoiaDB巨杉数据库采用计算存储分离架构,在计算层可以创建多种实例以满足同一集群不同场景的业务需要。本文讲述了MySQL和Spark实例的部署和SequoiaDB巨杉数据库进行对接操作,并利用Sysbench和TPC-DS工具分别在联机业务、分析业务和混合交易分析业务管理场景下进行性能测试,得出SequoiaDB巨杉数据库在混合交易分析业务管理场景下的性能相互影响较小的结论。






