一般来说,在业务系统投产后,由于非结构化数据和业务量的增加,使得集群可使用存储容量越来越小。因此,将业务系统接入集群之前,需要提前考虑在集群存储容量即将耗尽时如何水平扩展整个集群的存储容量。SequoiaDB 巨杉数据库是一款金融级分布式关系型数据库,可以通过集群扩容实现集群性能的近线性增长,同时解决数据存储的容量问题和整个集群的性能问题。
本文将通过详细的演示,与大家分享 SequoiaDB 集群如何实现扩容,以及扩容后如何进行数据迁移。
一、在线扩容
客户的业务系统中会存在许多数据模型,按数据量与时间维度的关系,可分为两大类:资料类和流水类。对于上述两类不同的业务模型,其扩容和数据迁移时采用的策略有所不同。
资料类模型的特点是表中数据总量不会有太大的变化,随着时间的推移,新增的数据量占比很小。主要包含以下几类:
资料类:存放客户和用户资料的表,由于客户总数不会有太大的变化,因此这类表中的数据随着时间的推移,其数据量也不会有太大的变化。
账户类:由于账户总数相对稳定,因此这类表中的数据量也不会有太大的变化。
余额类:记录每个用户的余额,和账户类的情况类似。
维度表:描述模型中的维度信息,数据量很小。
其它满足条件的资料类表
这类模型的特点是随着时间的推移,数据量变化很大,而且通常都会和时间范围成正比,主要包含以下几类:
用户操作流水:比如营业厅每天的开户,销户,转账等操作流水。随着时间的推移,该类流水表中的记录会越来越多,而且和时间范围成正比,例如2018年的操作流水有2亿条,那么2019年的操作流水差不多也有这么多。
用户月度账单:和用户操作流水类似,每个月的账单数据量变化不大,随着时间的推移,账单表中的数据量会越来越多,且和时间范围成正比。
余额收支流水:和用户操作流水类似,记录余额的变化过程。
其它满足条件的流水类表
SequoiaDB采用通用的开放式硬件平台,计算能力和容量均可横向扩展。SequoiaDB 可管理PB级别的数据。SequoiaDB 扩容同时具备以下特点:
集群扩容过程对应用系统透明,应用系统无需修配置、程序。
集群扩容速度快
支持数据均衡分布(rebalance)
如上图所示,SequoiaDB巨杉数据库支持在线扩容,系统扩容升级快速简单。
SequoiaDB巨杉数据库作为一款分布式数据库,在数据库架构设计之初就已经将方便快捷扩容作为设计标准,用户在系统性能不足时,通过快速扩展集群,提升系统整体性能。
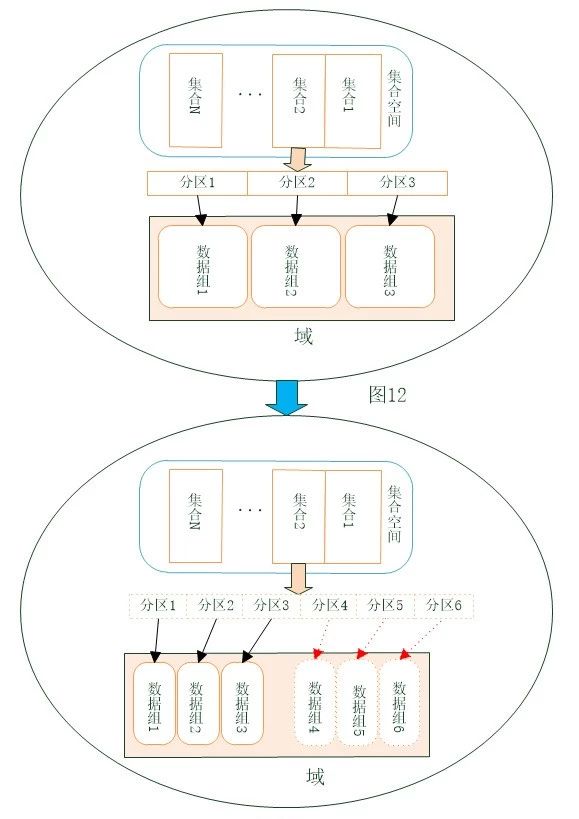
1.将新加入的数据复制组添加到域中;
2.使用split方法对域中的每个集合的数据,手动切分到新加入的数据组中。最常规的一种方式,适用于非多维分区表结构的普通集合,能不停机提供查询操作。
注:在切分的过程中,从协调节点看,集合的数据量会存在波动;对该集合数据的增删改可能会出现问题,建议在没有修改操作的时候进行该切分操作。
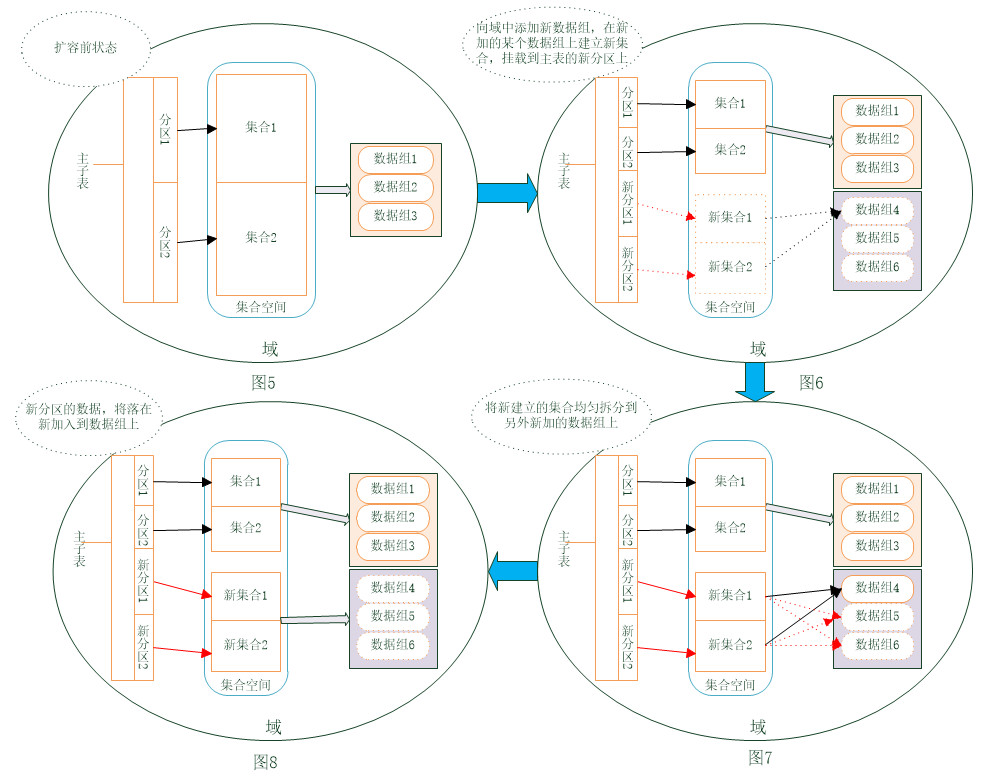
扩容前该多维分区表的每个子分区(集合1、2)数据均匀存放在原数据域内数据组1-3上,目标是新增子分区(新集合1、2),新数据均匀分布到新加入数据组的数据组上。
在建立子分区时,设置autoSplit属性为false,使用Group属性,但使用Group指定集合建立的分组时,只能指定一个数据组,不能指定多个数据组。因此还需要在子分区上,手动使用split方法,将数据范围切分到其他新增的数据组上。通过如下步骤进行扩容:
1. 将新加入的数据复制组添加到域中;
2. 在新加入的某个数据复制组上,建立新的子分区;
3. 使用split手动将新子分区切分到其他新加入的数据组上;
4. 挂载新的子分区到多维分区表上。
此方式适用于多维分区表,且多维分区表和子分区之间带有时间特性,业务系统过来的新增数据存入到新的子分区中。在按年或月信息作多维分区表分区键时,以及当前阶段的子分区数据接近饱和时,通过新增下一阶段的子分区,来存放下一阶段的数据。 对业务系统透明且无任何运转的影响。但由于Group只能指定一个分区组,手动切分比较麻烦。
在使用split方法对数据进行迁移时,如果一条命令迁移的数据量太大会对系统的性能有影响。为了将影响程度降到最低,我们建议对数据进行分批迁移。例如:对一张大表通过一条命令迁移50%的数据,可分为5条命令,每次迁移10%的数据。
二、集群扩容演示
接下来将为大家演示如何使用SAC(巨杉数据库图形化工具)操作集群扩容。现有集群是3台服务器,2个数据组。
192.168.178.145 sdb04
192.168.178.146 sdb05
192.168.178.147 sdb06
下面开始创建节点,添加分区组操作。
1. 登录网页控制台:http://192.168.178.142:8000
2. 点击部署>主机>添加主机
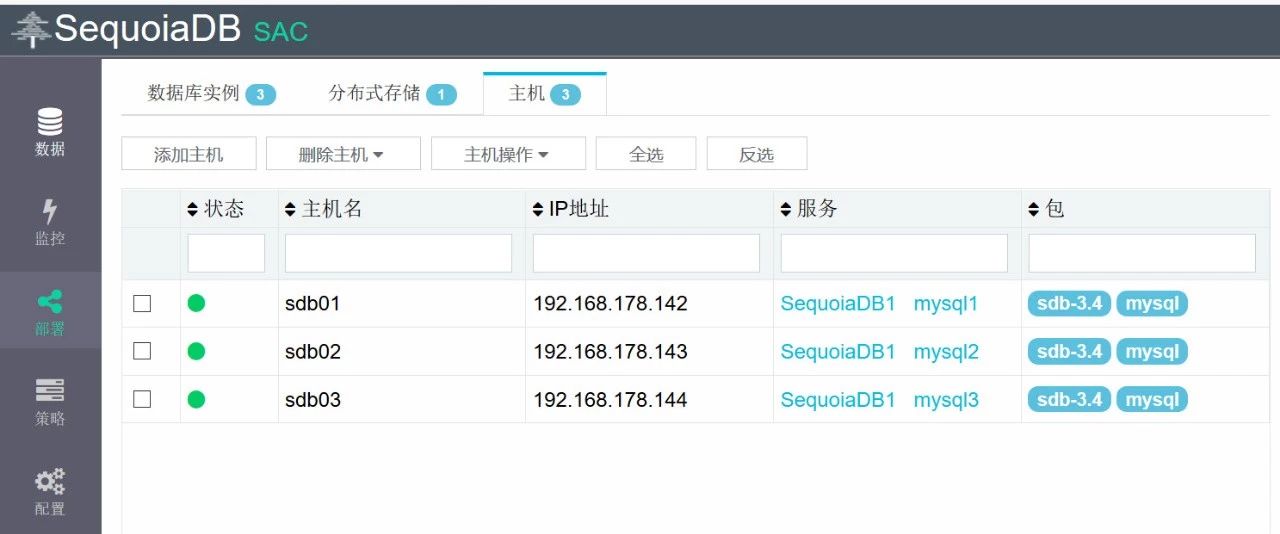
3. 将三台新机器的IP地址和密码填进去,然后点击左侧的扫描,右侧会出现扫描结果,然后点击下一步。
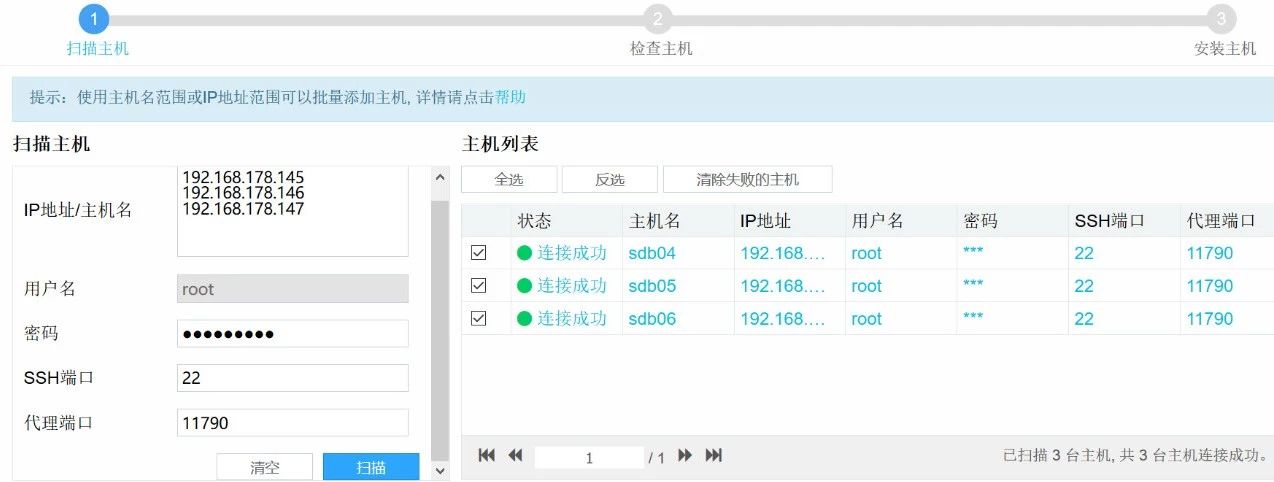
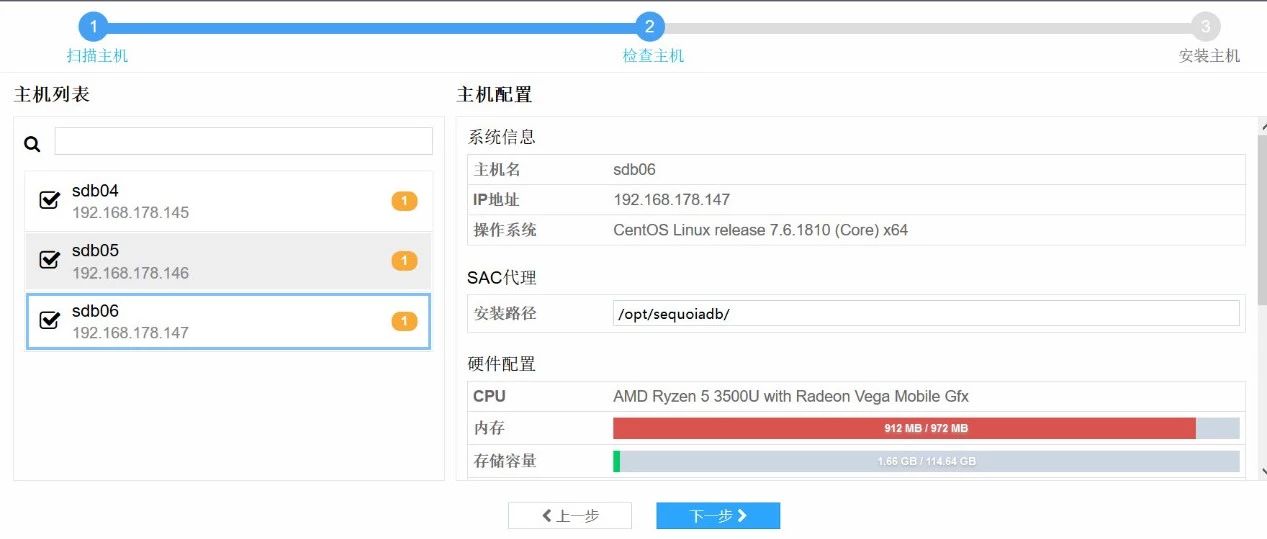
4. 再次扫描新增主机的详细配置信息后,设定安装路径,检查一下磁盘路径后在左侧主机名前面全部打上勾,然后点击下一步。
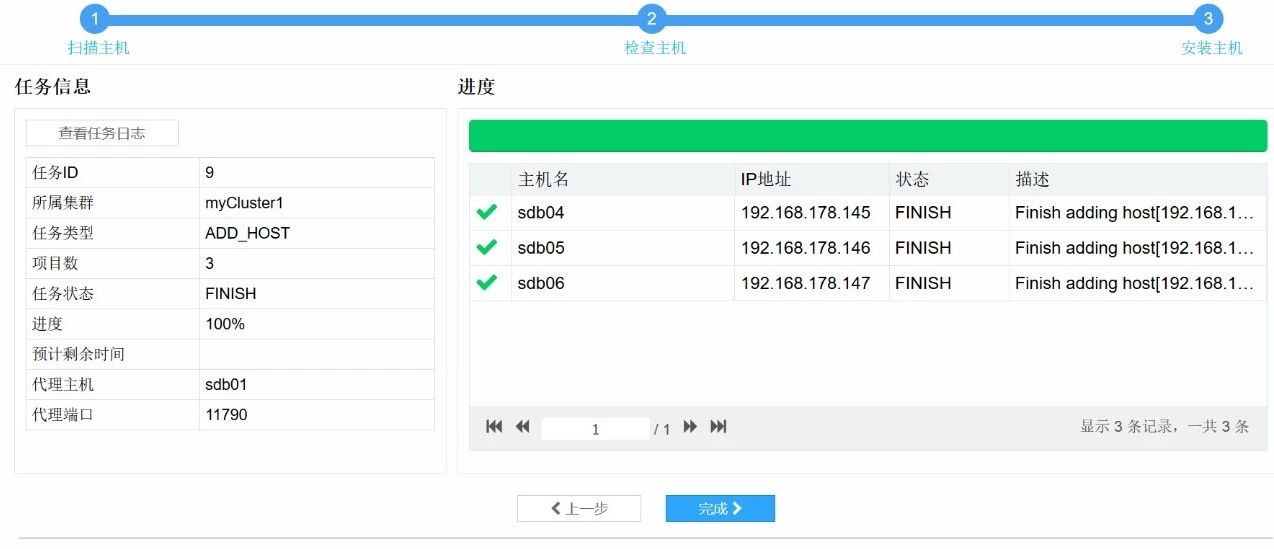
5. 等待进度条走完后点击完成按钮
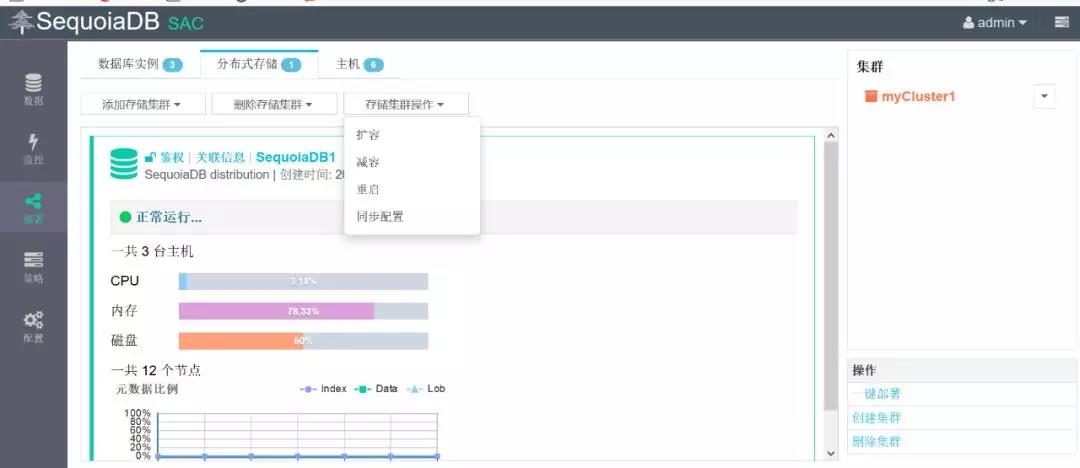
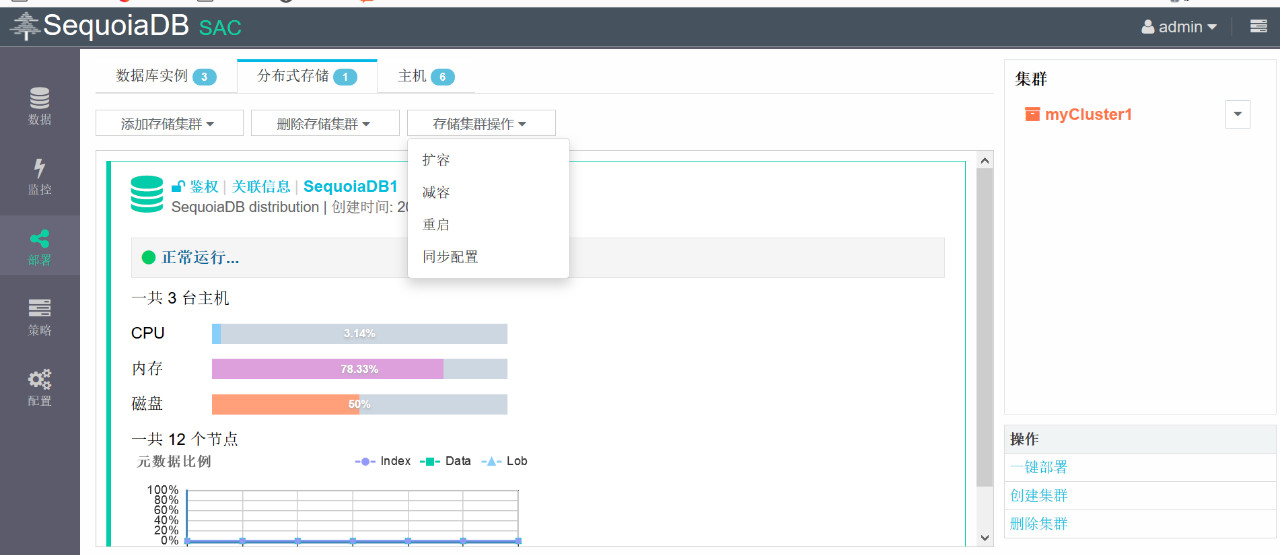
6.点击部署>分布式存储>存储集群操作>扩容,并在弹出的窗口中点击确定
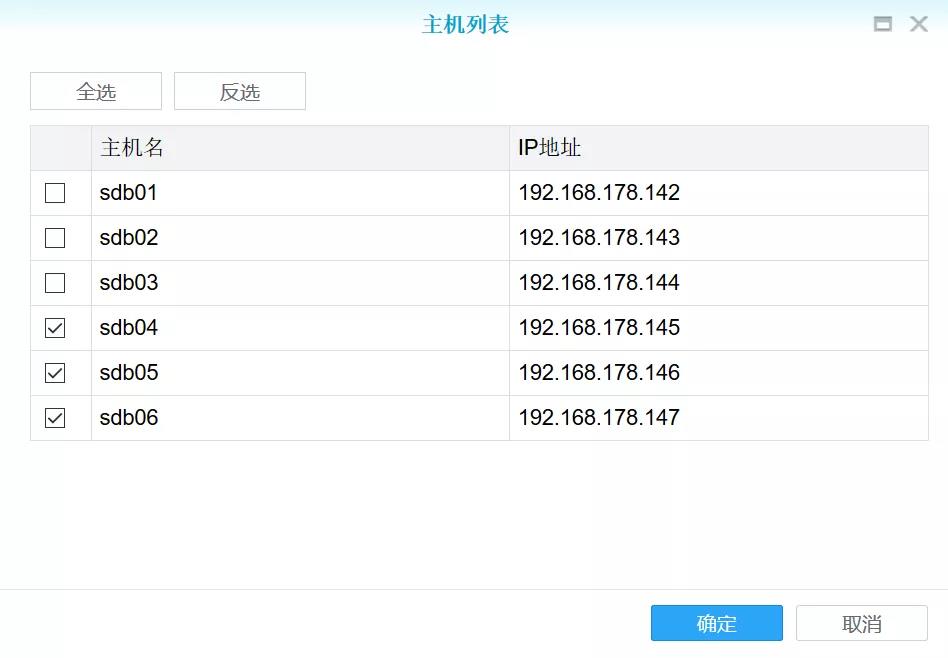
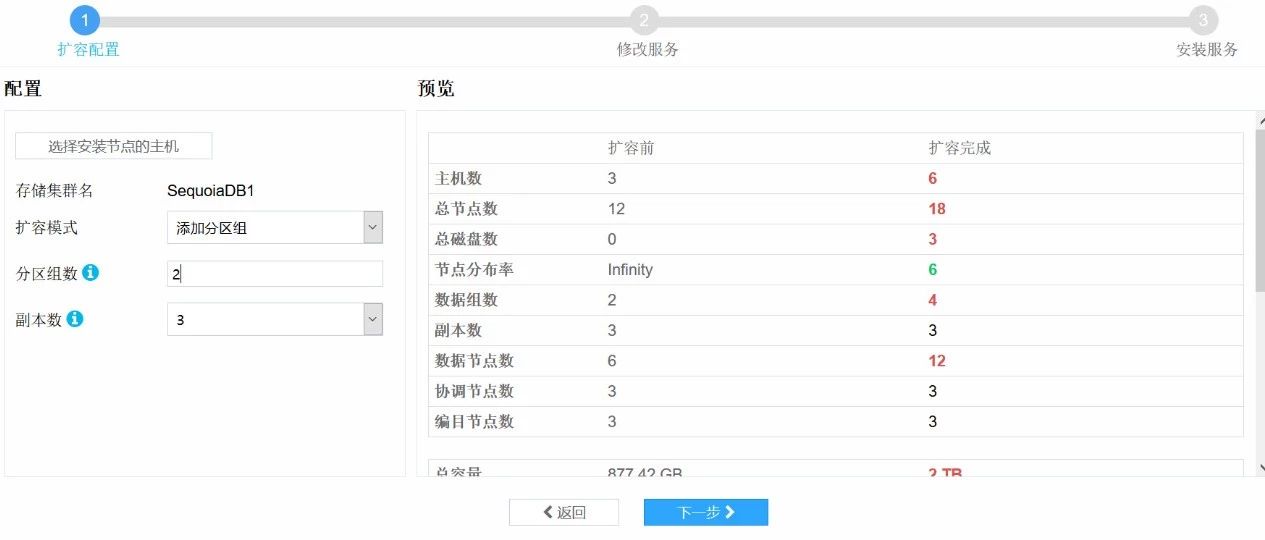
7.点击选择安装节点的主机,只勾选sdb04,sdb05,sdb06,点击确定
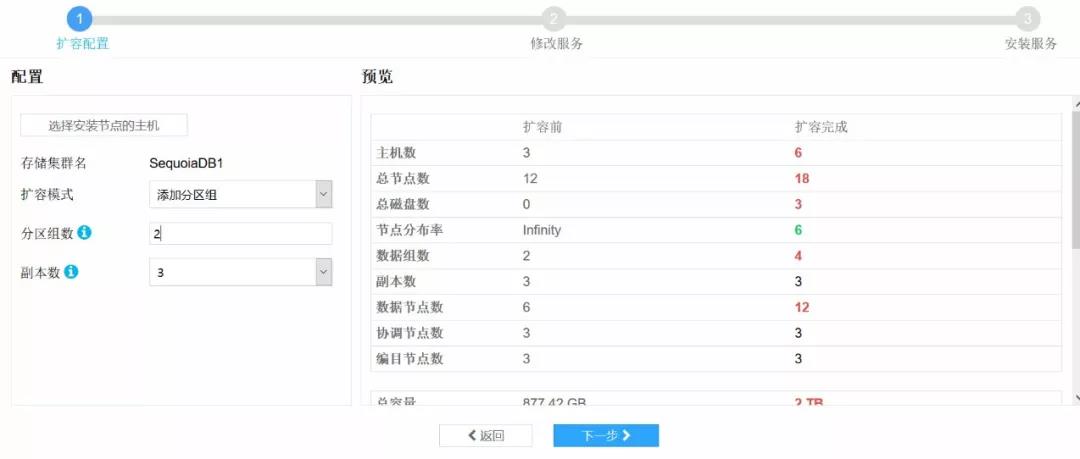
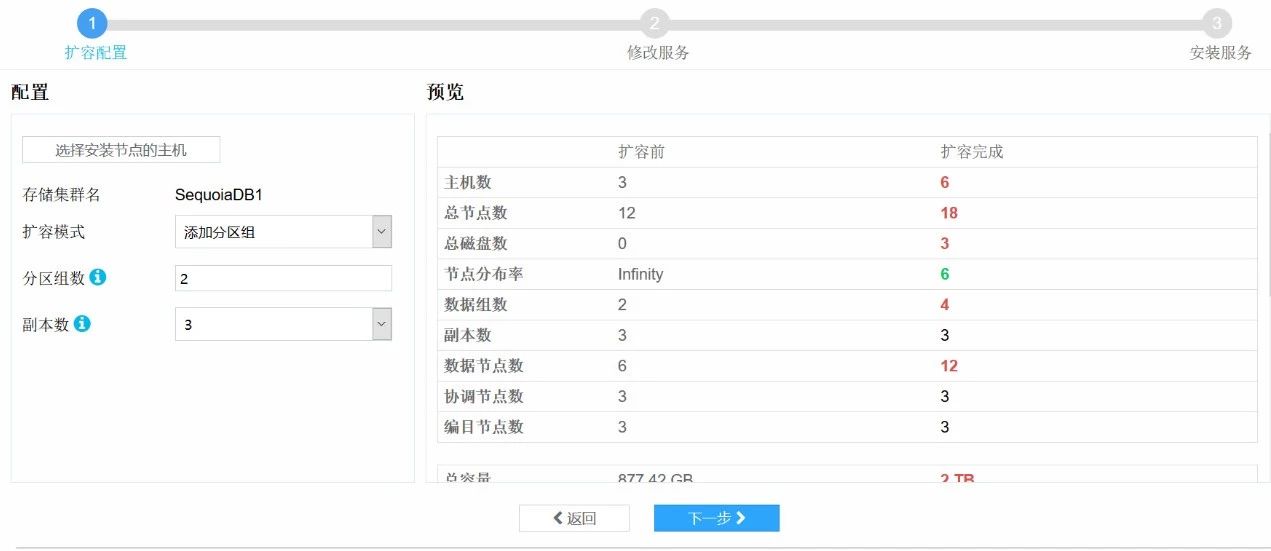
8.设置好分区组数和副本数,点击下一步
9. 修改端口号和路径,点击下一步
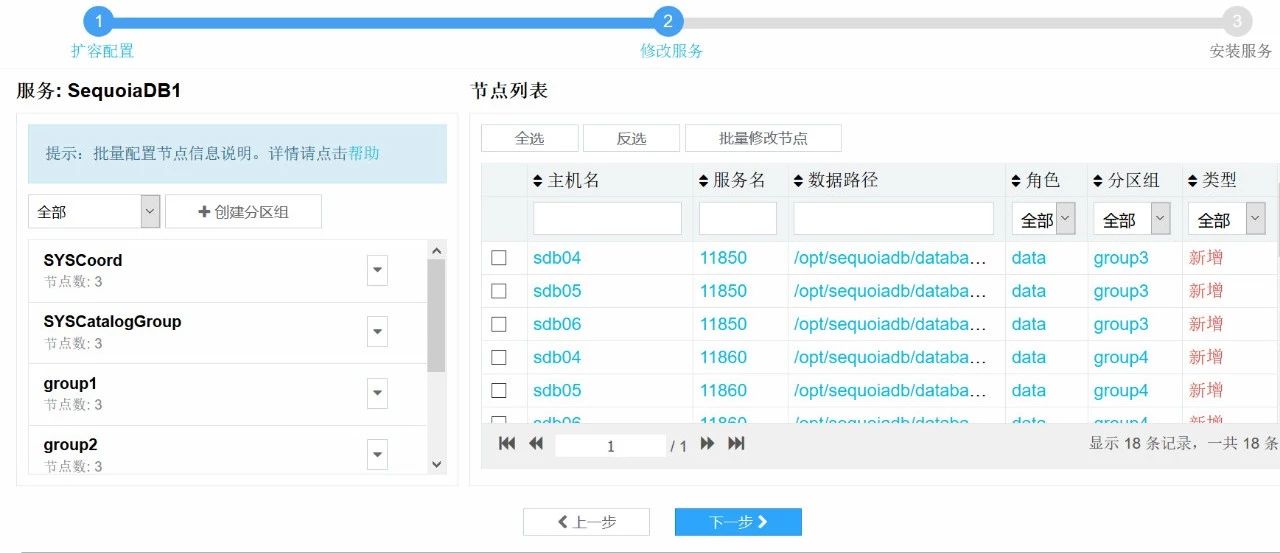
10. 点击完成
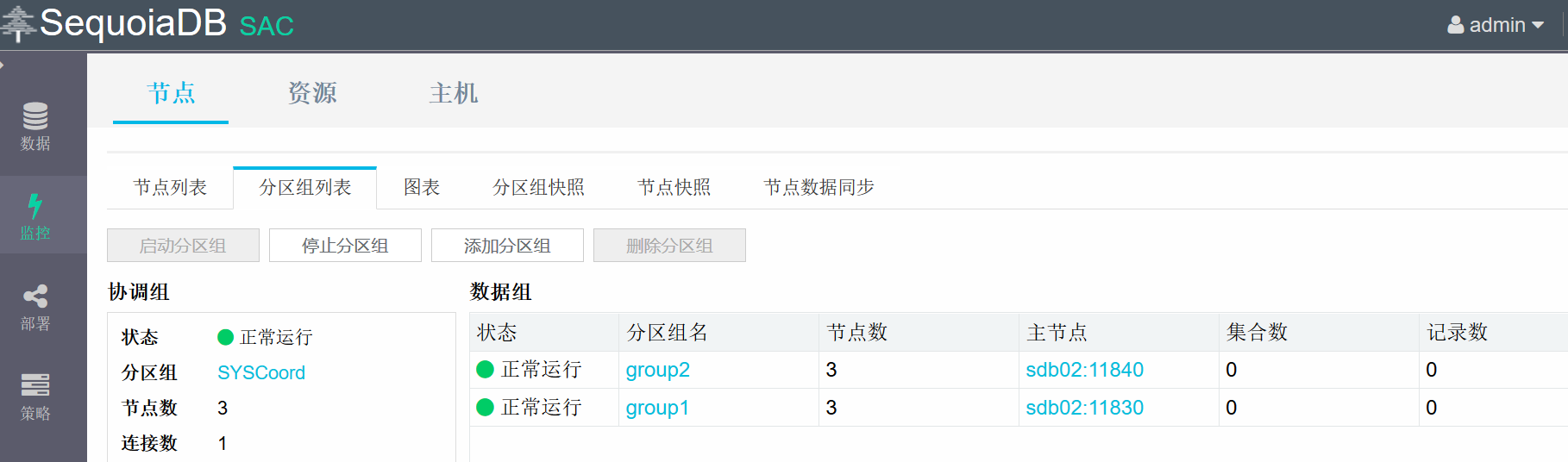
11. 点击监控>节点>分区组列表进行检查
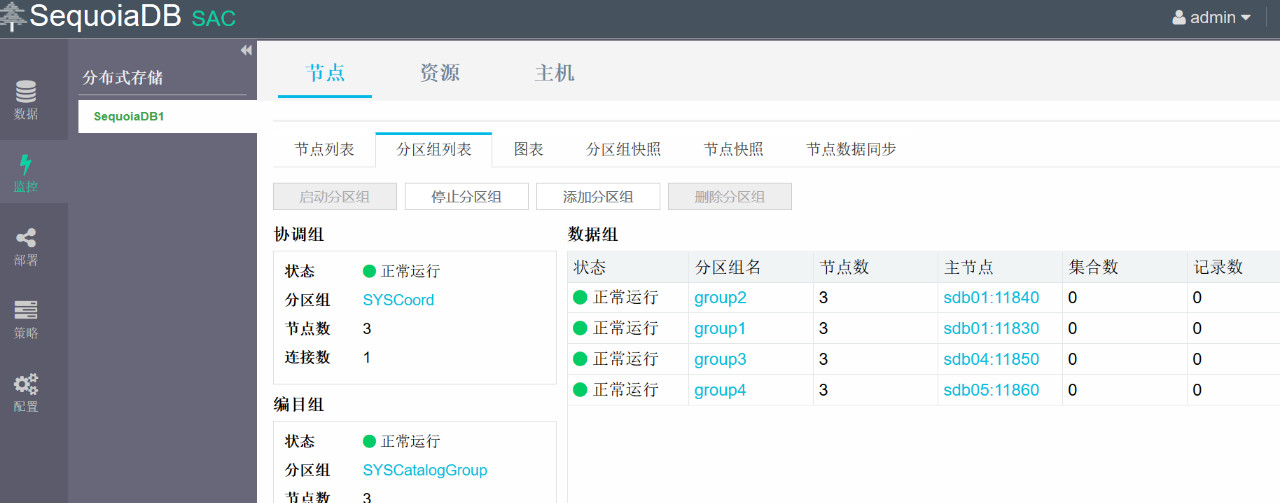
12. 下面开始添加协调节点,点击部署>分布式存储>存储集群操作>扩容,在弹出的窗口中点击确定
13. 点击选择安装节点的主机,只勾选sdb04,sdb05,sdb06,点击确定
14. 在左侧选择添加副本数,设置好协调节点个数和副本数,点击下一步
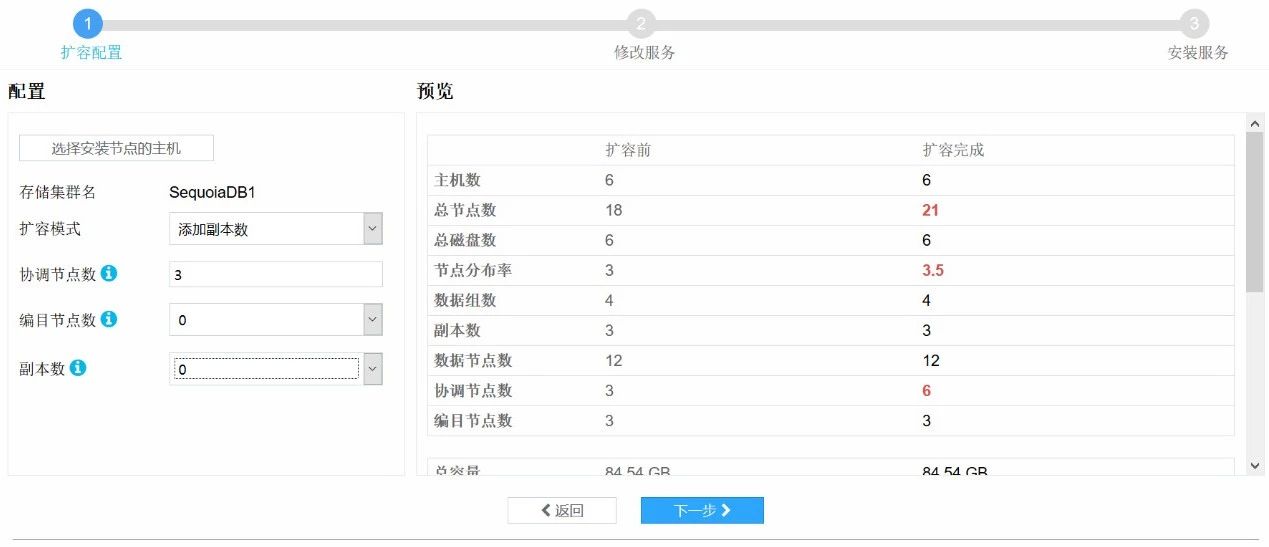
15. 设置好路径和对应的端口号,点击下一步
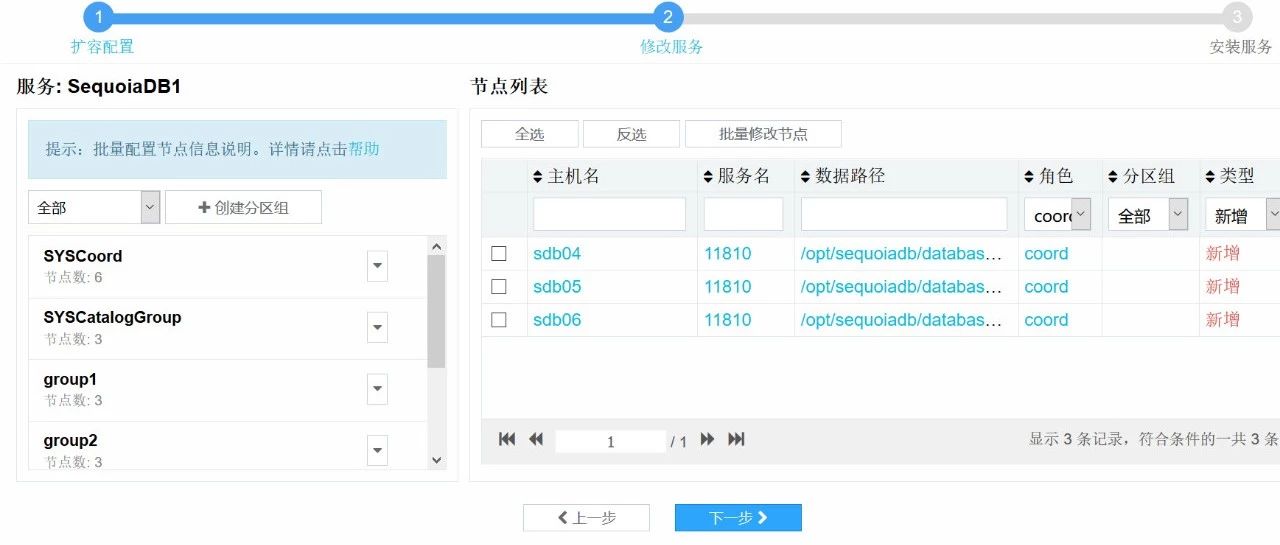
16. 点击完成。
三、数据迁移演示
[sdbadmin@sdb01 ~]$ sdb
Welcome to SequoiaDB shell!
help() for help, Ctrl+c or quit to exit
> db = new Sdb
localhost:11810
Takes 0.008819s.
> db.createDomain("d_12",["group1","group2"])
d_12
Takes 0.054416s.2. 创建集合空间testsp,对应数据域d_12。
> db.createCS("testsp",{Domain:"d_12"})
localhost:11810.testsp
Takes 0.087299s.3. 在testsp上创建一张测试表,插入29条记录。
[sdbadmin@sdb01 ~]$ mysql -D testsp -e "select * from test1" +----+ | s1 | +----+ | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 | | 8 | | 9 | | 10 | | 11 | | 12 | | 13 | | 14 | | 15 | | 16 | | 17 | | 18 | | 19 | | 20 | | 21 | | 22 | | 23 | | 24 | | 25 | | 26 | | 27 | | 28 | | 29 | +----+ [sdbadmin@sdb01 ~]$ mysql -D testsp -e "show create table test1" +-------+-------------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------+-------------------------------------------------------------------------------------------------------------------------------------+ | test1 | CREATE TABLE `test1` ( `s1` int(11) NOT NULL, PRIMARY KEY (`s1`) ) ENGINE=SEQUOIADB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin | +-------+-------------------------------------------------------------------------------------------------------------------------------------+[sdbadmin@sdb01 ~]$
4. 在sdb上连接group1和group2(对应的端口为11830和11840),查看对应的记录数,可以看到,group1上有16条记录,group2上有13条记录。
[sdbadmin@sdb01 ~]$ sdb
Welcome to SequoiaDB shell!
help() for help, Ctrl+c or quit to exit
> db = new Sdb("localhost",11830)
localhost:11830
Takes 0.013035s.
> db.testsp.test1.count()
16Takes 0.006279s.
> db = new Sdb("localhost",11840)
localhost:11840
Takes 0.007240s.
> db.testsp.test1.count()
13
Takes 0.001224s.
>5. 创建新的数据域d_1234 ,包含所有4个数据组。
> db = new Sdb
localhost:11810
Takes 0.004545s.
> db.createDomain("d_1234",["group1","group2","group3","group4"])
d_1234
Takes 0.016816s.6. 修改集合空间testsp的属性,使其对应新的数据域d_1234。
> db.testsp.setAttributes({Domain:"d_1234"})
Takes 0.022994s.7. 将group1和group2上test1的数据split一部分到group3和group4中。
> db.testsp.test1.split("group1","group3",30)
Takes 6.084888s.
> db.testsp.test1.split("group2","group4",40)
Takes 5.020984s.8. 分别连接到4个数据组上,查看对应的记录数,可以看到,group1上有11条记录,group2上有9条记录,group3上有5条记录,group4上有4条记录
> db = new Sdb("localhost",11830)
localhost:11830
Takes 0.015484s.
> db.testsp.test1.count()
11
Takes 0.001464s.
> db = new Sdb("localhost",11840)
localhost:11840Takes 0.007712s.
> db.testsp.test1.count()
9
Takes 0.001094s.
> db = new Sdb("sdb04",11850)sdb04:11850
Takes 0.008238s.
> db.testsp.test1.count()
5
Takes 0.003208s.
> db = new Sdb("sdb04",11860)sdb04:11860Takes 0.008032s.
> db.testsp.test1.count()
4
Takes 0.002765s.3.2 多维分区表使用添加子分区的方式将新数据存放到新机器上
> db = new Sdblocalhost:11810
Takes 0.005286s.
> db.createCS("testdb",{Domain:"d_12"})
localhost:11810.testdb
Takes 0.051754s.
mysql> create table is_trace
-> ( trace_id varchar(16) not null ,
-> trace_time date not null
-> )
-> COMMENT="sequoiadb:{table_options:{ShardingKey:{trace_time:1},ShardingType:'range',IsMainCL: true,EnsureShardingIndex:false}}" ;
Query OK, 0 rows affected (0.02 sec)2. 创建并挂载第一个子分区,挂载条件为trace_time为2018年的某一日。
[sdbadmin@sdb01 ~]$ sdb
Welcome to SequoiaDB shell!
help() for help, Ctrl+c or quit to exit
> db = new Sdb
localhost:11810
Takes 0.005220s.
> db.testdb.createCL("is_trace_1",{ShardingKey:{trace_id:1},ShardingType:'hash',EnsureShardingIndex:false,AutoSplit:true});
localhost:11810.testdb.is_trace_1
Takes 1.397133s.
> db.testdb.is_trace.attachCL("testdb.is_trace_1",{LowBound:{trace_time:{$date:"2018-01-01"}},UpBound:{trace_time:{$date:"2019-01-01"}}});
Takes 0.210895s.
>3. 插入12条记录,trace_time为2018年每个月的1日。
[sdbadmin@sdb01 ~]$ mysql -D testdb -e "select * from is_trace order by 2" +----------+------------+ | trace_id | trace_time | +----------+------------+ | 1 | 2018-01-01 | | 2 | 2018-02-01 | | 3 | 2018-03-01 | | 4 | 2018-04-01 | | 5 | 2018-05-01 | | 6 | 2018-06-01 | | 7 | 2018-07-01 | | 8 | 2018-08-01 | | 9 | 2018-09-01 | | 10 | 2018-10-01 | | 11 | 2018-11-01 | | 12 | 2018-12-01 | +----------+------------+ [sdbadmin@sdb01 ~]$
4. 这些记录在group1和group2上,即sdb01,sdb02,sdb03这三台机器上。从下图可以看出,12条记录都在is_trace_1这个子分区中。
[sdbadmin@sdb01 ~]$ sdb Welcome to SequoiaDB shell! help() for help, Ctrl+c or quit to exit > db = new Sdb localhost:11810 Takes 0.005843s. > db.testdb.is_trace_1.count() 12 Takes 0.012390s.
5. 在group3和group4上创建一个新的数据域d_34和对应的集合空间testdb_34。
> db.createDomain("d_34",["group3","group4"])
d_34
Takes 0.015198s.
> db.createCS("testdb_34",{Domain:"d_34"})
localhost:11810.testdb_34
Takes 0.089378s.6. 在testdb_34中创建并挂载子分区is_trace_2, 挂载条件为trace_time为2019年的某一日。
> db.testdb_34.createCL("is_trace_2",{ShardingKey:{trace_id:1},ShardingType:'hash',EnsureShardingIndex:false,AutoSplit:true});
localhost:11810.testdb_34.is_trace_2
Takes 1.718828s.
> db.testdb.is_trace.attachCL("testdb_34.is_trace_2",{LowBound:{trace_time:{$date:"2019-01-01"}},UpBound:{trace_time:{$date:"2020-01-01"}}});
Takes 0.016109s.7.插入6条记录,trace_time为2019年前6个月的1日。
[sdbadmin@sdb01 ~]$ mysql -D testdb -e "select * from is_trace order by 2" +----------+------------+ | trace_id | trace_time | +----------+------------+ | 1 | 2018-01-01 | | 2 | 2018-02-01 | | 3 | 2018-03-01 | | 4 | 2018-04-01 | | 5 | 2018-05-01 | | 6 | 2018-06-01 | | 7 | 2018-07-01 | | 8 | 2018-08-01 | | 9 | 2018-09-01 | | 10 | 2018-10-01 | | 11 | 2018-11-01 | | 12 | 2018-12-01 | | 13 | 2019-01-01 | | 14 | 2019-02-01 | | 15 | 2019-03-01 | | 16 | 2019-04-01 | | 17 | 2019-05-01 | | 18 | 2019-06-01 | +----------+------------+
8. 进入sdb检查一下,可以看到新插入的2019年的6条记录都在子分区is_trace_2中,该子分区对应的数据组为group3和group4,在新增的三台机器sdb04,sdb05,sdb06上,从而实现了多维分区表在扩容时可以按时间字段将新数据放在新机器上。
[sdbadmin@sdb01 ~]$ sdb
Welcome to SequoiaDB shell!
help() for help, Ctrl+c or quit to exit
> db = new Sdb
localhost:11810
Takes 0.004549s.
> db.testdb_34.is_trace_2.count()
6
Takes 0.013042s.
> db.testdb_34.is_trace_2.find()
{ "_id": { "$oid": "5def87feeea548461b2de751" }, "trace_id": "13", "trace_time": { "$date": "2019-01-01" }}{ "_id": { "$oid": "5def8809eea548461b2de753" }, "trace_id": "15", "trace_time": { "$date": "2019-03-01" }}{ "_id": { "$oid": "5def8811eea548461b2de754" }, "trace_id": "16", "trace_time": { "$date": "2019-04-01" }}{ "_id": { "$oid": "5def8803eea548461b2de752" }, "trace_id": "14", "trace_time": { "$date": "2019-02-01" }}{ "_id": { "$oid": "5def8818eea548461b2de755" }, "trace_id": "17", "trace_time": { "$date": "2019-05-01" }}{ "_id": { "$oid": "5def8820eea548461b2de756" }, "trace_id": "18", "trace_time": { "$date": "2019-06-01" }}
Return 6 row(s).
Takes 0.003040s.本文通过详细的演示为大家分享了巨杉数据库集群的扩展和数据迁移的具体方法,欢迎大家测试使用。






