SequoiaDB 一款自研金融级分布式数据库产品,支持标准SQL和分布式事务功能、支持复杂索引查询,兼容 MySQL、PGSQL、SparkSQL等SQL访问方式。SequoiaDB 在分布式存储功能上,较一般的大数据产品提供更多的数据切分规则,包括:水平切分、范围切分、主子表切分和多维切分方式,用户可以根据不用的场景选择相应的切分方式,以提高系统的存储能力和操作性能。
为了能够提供简单便捷的数据迁移和导入功能,同时更方便地与传统数据库在数据层进行对接,巨杉数据库支持多种方式的数据导入,用户可以根据自身需求选择最适合的方式加载数据。
本文主要介绍巨杉数据库集中常见的高性能数据导入方法,其中包括巨杉工具矩阵中的 Sdbimprt导入工具,以及使用SparkSQL, MySQL和原生API 接口进行数据导入,一共四种方式。
sdbimprt 是 SequoiaDB 的数据导入工具,是巨杉数据库工具矩阵中重要组成之一,它可以将 JSON 格式或 CSV 格式的数据导入到 SequoiaDB 数据库中。
下面简单介绍一下如何使用 sdbimprt 工具将 csv 文件导入到 SequoiaDB 集合空间 site 的集合 user_info 中:
1. 数据文件名称为“user.csv”,内容如下:
“Jack”,18,”China” “Mike”,20,”USA”
2.导入命令
sdbimprt --hosts=localhost:11810 --type=csv --file=user.csv -c site -l user_info --fields='name string default "Anonymous", age int, country'
--hosts:指定主机地址(hostname:svcname)
--type:导入数据格式,可以是csv或json
--file:要导入的数据文件名称
-c(--csname):集合空间的名字
-l(--clname):集合的名字
--fields:指定导入数据的字段名、类型、默认值
二、导入性能优化
下面说明使用 sdbimprt 工具时如何提升导入性能:
导入数据时,尽量指定多个 coord 节点的地址,用“,”分隔多个地址,sdbimprt 工具会把数据随机发到不同机器上的 coord,起到负载均衡的作用。
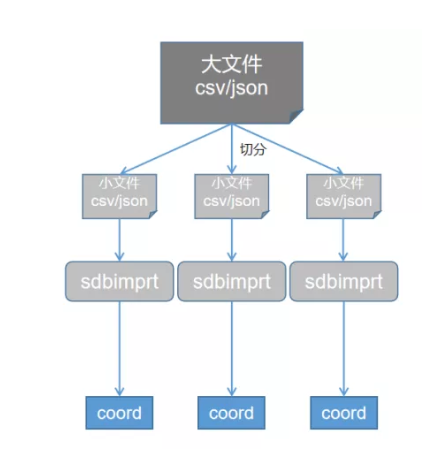
sdbimprt 在导入数据时支持多线程并发导入,但读数据时是单线程读取,随着导入线程数的增加,数据读取就成为了性能瓶颈。这种情况下,可以将一个大的数据文件切分成若干个小文件,然后每个小文件对应启动一个 sdbimprt 进程并发导入,从而提升导入性能。如果集群内有多个协调节点,分布在不同的机器上,那么可以在多台机器上分别启动 sdbimprt 进程,并且每个 sdbimprt 连接机器本地的协调节点,这样数据发送给协调节点时避免了网络传输。
CREATE TABLE hdfstable USING org.apache.spark.sql.execution.datasources.csv.CSVFileFormat OPTIONS ( path "hdfs://usr/local/data/test.csv", header "true" )
2. 将 SDB 的集合映射成 spark 的临时表
create temporary table sdbtable ( a string, b int, c date ) using com.sequoiadb.spark OPTIONS ( host 'sdbserver1:11810,sdbserver2:11810,sdbserver3:11810', username 'sdbadmin', password 'sdbadmin', collectionspace 'sample', collection 'employee', bulksize '500' );
3. 导入
sparkSession.sql("insert into sdbtable select * from hdfstable");host
bulksize
关于如何与MySQL对接,请参考:
http://doc.sequoiadb.com/cn/sequoiadb-cat_id-1521595283-edition_id-302。
1. SQL 文件导入
mysql> source /opt/table1.sql
2. CSV 文件导入。mysql 中提供了 load data infile 语句来插入数据:
mysql> load data local infile '/opt/table2.csv' into table table2 fields terminated by ',' enclosed by '"' lines terminated by '\n';
SequoiaDB 提供了插入数据的 API 接口,即“insert”接口。insert 接口会根据传入的参数不同而使用不同的插入方式,如果每次只传入一条记录,则接口也是将记录逐条的发送到数据库引擎,如果每次传入一个包含多条记录的集合或数组,则接口会一次性把这批记录发送到数据库引擎,最后通过引擎一条一条写入数据库中。






