01
SequoiaDB 与 SparkSQL 介绍
02
SequoiaDB 与 SparkSQL 如何整合?
SPARK_CLASSPATH="/media/psf/mnt/sequoiadb-driver-2.9.0-SNAPSHOT.jar:/media/psf/mnt/spark-sequoiadb_2.11-2.9.0-SNAPSHOT.jar"用户修改完 spark-env.sh 配置后,重启 spark-sql 或者 thriftserver 就完成了 Spark 和 SequoiaDB 的对接。
03
SequoiaDB 与 SparkSQL 性能优化
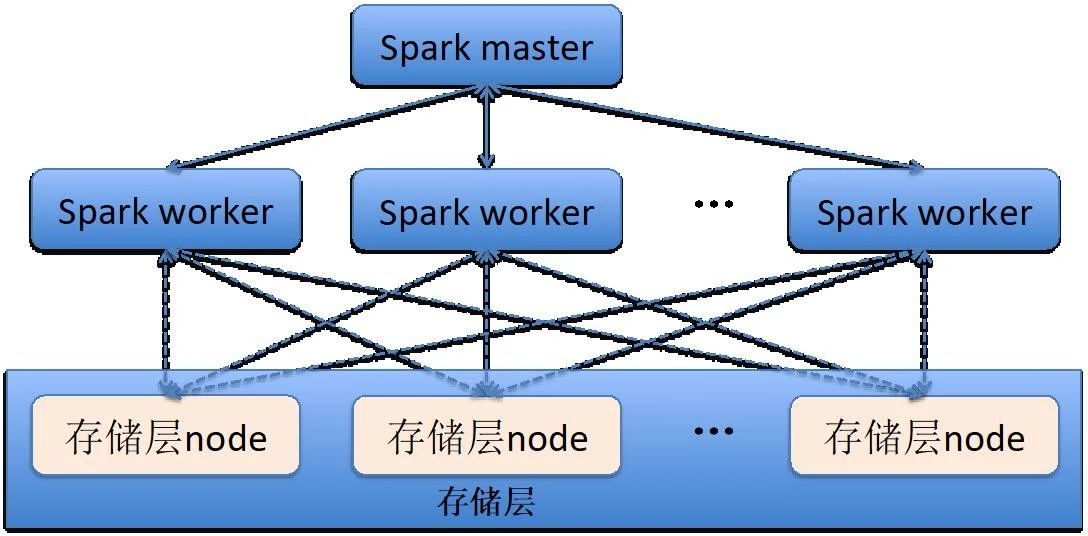
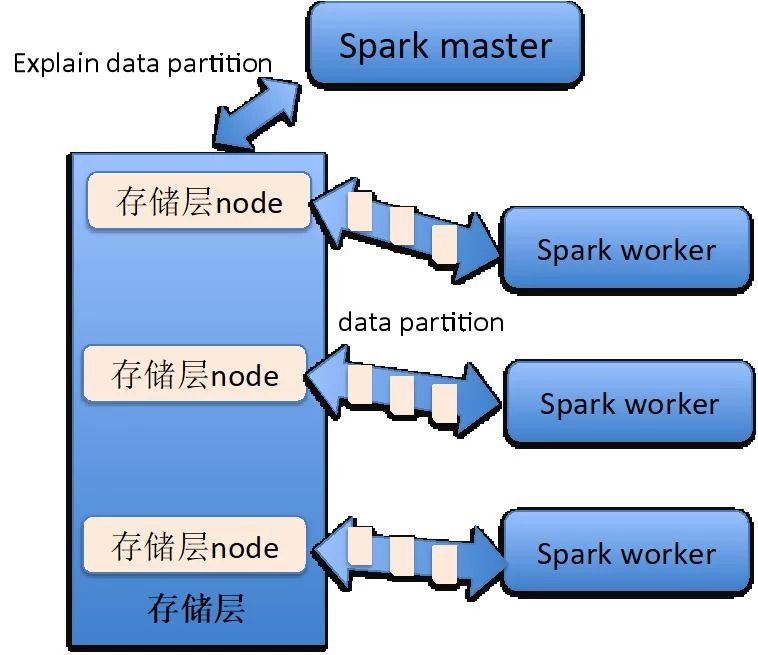
Spark 产品虽然为用户提供了多种功能模块,但是都只是数据计算的功能模块。Spark 产品本身没有任何的存储功能,在默认情况下,Spark 是从本地文件服务器或者 HDFS 上读取数据。而 Spark 也将它与存储层的接口开放给广大开发者,开发者只要按照 Spark 接口规范实现其存储层连接器,任何数据源均可称为 Spark 计算的数据来源。
下图为 Spark worker 与存储层中 datanode 的关系。
create [temporary] <table|view> <name>[(schema)] using com.sequoiadb.spark options (<options>);
create table tableName (name string, id int) using com.sequoiadb.spark options (host 'sdb1:11810,sdb2:11810,sdb3:11810', collectionspace 'foo', collection 'bar', username 'sdbadmin', password 'sdbadmin');
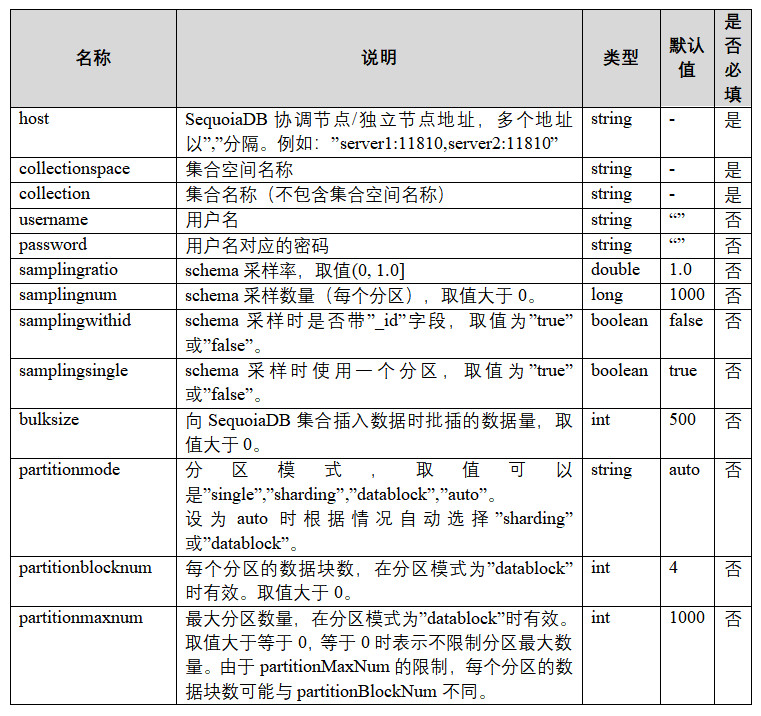
SparkSQL for SequoiaDB 的建表 options 参数列表如下:
3.2 SparkSQL 优化
用户如果要使用 SparkSQL 对海量数据做统计分析操作,那么应该从3个方面进行性能调优:
1. 调大 Spark Worker 最大可用内存大小,防止在计算过程中数据超出内存范围,需要将部分数据写入到临时文件上;
2. 增加 Spark Worker 数目,并且设置每个 Worker 均可以使用当前服务器左右 CPU 资源,以提高并发能力;
3. 调整 Spark 的运行参数;
用户可以对 spark-env.sh 配置文件进行设置,SPARK_WORKER_MEMORY 为控制 Worker 可用内存的参数,SPARK_WORKER_INSTANCES 为每台服务器启动多少个 Worker 的参数。
如果用户需要调整 Spark 的运行参数,则应该修改 spark-defaults.conf 配置文件,对优化海量数据统计计算有较明显提升的参数有:
1. spark.storage.memoryFraction, 该参数控制 Worker 多少内存比例用户存储临时计算数据,默认为0.6,代表60%的含义;
2. spark.shuffle.memoryFraction, 该参数控制计算过程中 shuffle 时能够占用每个 Worker 的内存比例,默认为0.2,代表20%的含义,如果临时存储的计算数据较少,而计算中有较多的 group by, sort, join 等操作,应该考虑将spark.shuffle.memoryFraction 调大,spark.storage.memoryFraction 调小,避免超出内存部分需要写入临时文件中;
3. spark.serializer, 该参数设置 Spark 在运行时使用哪种序列化方法,默认为 org.apache.spark.serializer.JavaSerializer, 但是为了提升性能,应该选择 org.apache.spark.serializer.KryoSerializer 序列化。
3.3 SequoiaDB 优化
SparkSQL+SequoiaDB 这种组合,由于数据读取是从 SequoiaDB 中进行,所以在性能优化应该考虑三点
1. 尽可能将大表的数据分布式存储,所以建议符合二维切分条件的 table 应该采用主子表+ Hash 切分两种数据均衡方式进行数据分布式存储;
2. 数据导入时,应该避免同时对相同集合空间的多个集合做数据导入,因为同一个集合空间下的多个集合是共用相同一个数据文件,如果同时向相同集合空间的多个集合做数据导入,会导致每个集合下的数据块存储过于离散,从而导致在 Spark SQL 从SequoiaDB 获取海量数据时,需要读取的数据块过多;
3. 如果 SparkSQL 的查询命令中包含查询条件,应该对应地在 SequoiaDB 中建立对应字段的索引。
3.4 connector 优化
SequoiaDB for Spark 连接器的参数优化,主要分两个场景,一是数据读,另外一个是数据写入。
数据读取的参数优化,用户则需要关注 partitionmode, partitionblocknum 和 partitionmaxnum 三个参数。
partitionmode,连接器的分区模式,可选值有single、sharding、datablock、auto,默认值为auto,代表连接器智能识别。
1. single 值代表 SparkSQL 在访问 SequoiaDB 数据时,不考虑并发性能,只用一个线程连接 SequoiaDB 的 Coord 节点,一般该参数在建表做表结构数据抽样时采用;
2. sharding 值代表 SparkSQL 访问 SequoiaDB 数据时,采用直接连接 SequoiaDB 各个 datanode 的方式,该参数一般采用在 SQL 命令包含查询条件,并且该查询可以在 SequoiaDB 中使用索引查询的场景;
3. datablock 值代表 SparkSQL 访问 SequoiaDB 数据时,采用并发连接 SequoiaDB 的数据块进行数据读取,该参数一般使用在SQL命令无法在 SequoiaDB 中使用索引查询,并且查询的数据量较大的场景;
4. auto 值代表 SparkSQL 在向 SequoiaDB 查询数据时,访问 SequoiaDB 的方式将由连接器根据不同的情况分析决定。
partitionblocknum,该参数只有在 partitionmode=datablock 时才会生效,代表每个 Worker 在做数据计算时,一次获取多少个 SequoiaDB 数据块读取任务,该参数默认值为4。如果 SequoiaDB 中存储的数据量较大,计算时涉及到的数据块较多,用户应该调大该参数,使得 SparkSQL 的计算任务保持在一个合理范围,提高数据读取效率。
partitionmaxnum,该参数只有在 partitionmode=datablock 时才会生效,代表连接器最多能够生成多少个数据块读取任务,该参数的默认值为1000。该参数主要是为了避免由于 SequoiaDB 中的数据量过大,使得总的数据块数量太大,导致 SparkSQL 的计算任务过多,最后使得总体计算性能下降。
04
总结






