本文将围绕下面三个方面介绍 SequoiaDB 灾备架构:
1)SequoiaDB“两地三中心”在线灾备系统架构原理
2)如何实战搭建
3)如何实现灾备切换与恢复
1
SequoiaDB异地多活灾备架构
SequoiaDB 已经在内部实现了容灾备份以及“双活”的机制,主要特点包括:
异地容灾:异地的容灾和备份,保证数据安全,中心间距离超过1000km以上;满足金融机构“两地三中心”的监管需求。
同城双活:同城双中心的数据准实时同步,保证数据一致;双中心数据可以实现同时读写,大大提升读写效率;中心切换 RTO 小于 10分钟。
数据压缩机制:节约带宽资源,加快同步和备份过程。
更便捷的灾备管理:系统集群中统一管理灾备中心,简化了维护成本,帮助用户更快上手
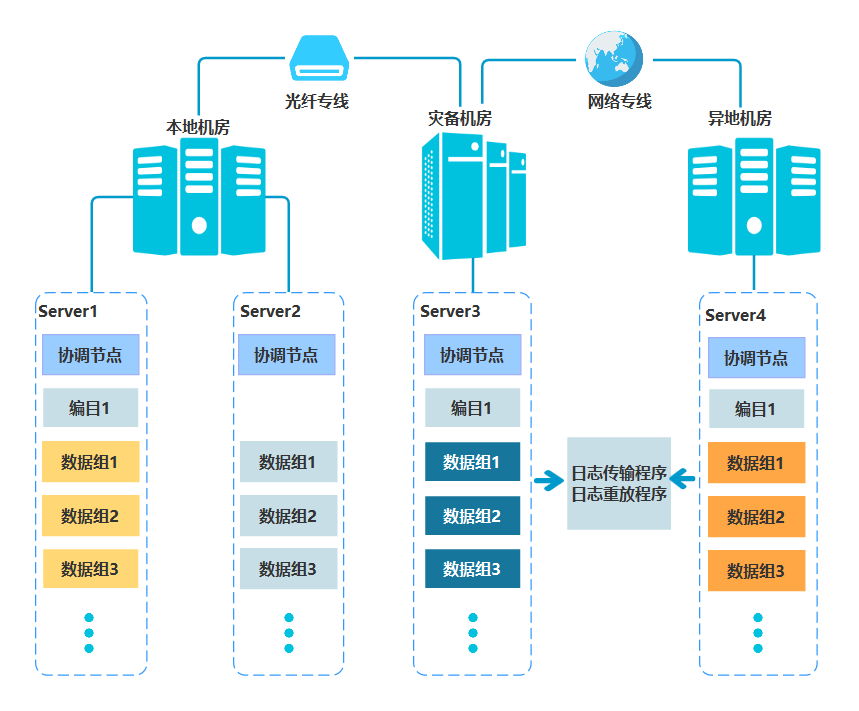
图1 异地容灾部署架构图
2
搭建“两地三中心”实战
1. 两地三中心环境信息
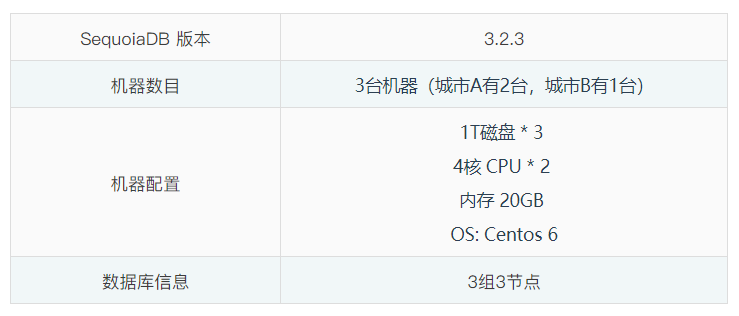
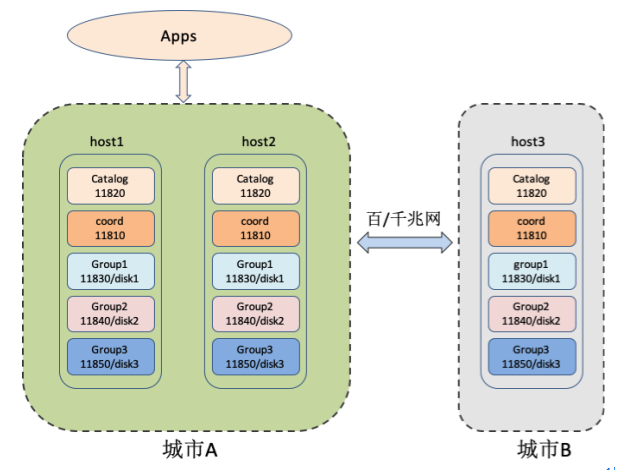
城市A和城市B之前的网络带宽和延时
业务一致性策略
c) 在取值为2时,业务写主节点后,需要等待至少其它1个节点完成数据同步后才返回。由于同城内的网络优于城市间,因此,该情况下保证了同城内节点间的数据同步,在城市A发生整体故障时,数据丢失风险还是较大。建议集合的一致性策略即ReplSize属性取值为-1。
节点数据故障时的处理策略
当城市B的节点出现节点异常或数据严重落后于城市A的节点时,城市B的节点就需要进行数据异常的处理,目前的数据异常处理有3种:
a) 全量同步:会占用大量的带宽,会对业务性能造成影响,建议是在业务低谷期才开启;
b) 节点停止:节点停止运行;
c) 节点保持运行,不进行全量同步,但数据也不对外提供服务:主要是用于保持分区组的心跳和选举稳定性,可以让集群整体可用。对应的节点配置参数为“dataerrorop”,取值0表示c,1表示a,2表示b。建议配置为0,当有节点出现数据故障时,在业务低谷期修改参数为1,并动态生效(执行reload)以让节点自动全量同步,也可以保证减少对业务的影响。
3
异地在线灾备系统搭建
1. 灾备工具对应在版本的安装根路径(本系统中为 /opt/sequoiadb )下
tools |---dr_ha | |----cluster_opr.js | |----init.sh | |---split.sh | |---merge.sh | |---readme.txt
2 . 将上述机器根据城市划分为2个分组SUB1(host1,host2)和SUB2(host3),并在 host1 和 host3 上进行配置的修改
修改 host1 上的 cluster_opr.js 文件
/* 机器登入用户名定义 */
if ( typeof(USERNAME) != "string" ) { USERNAME = "sdbadmin" ; }
/* 机器登入密码定义 */
if ( typeof(PASSWD) != "string" ) { PASSWD = "sdbadmin" ; }
/* 子网1机器定义,必须为字符串数组 */
if ( typeof(SUB1HOSTS) == "undefined" ) { SUB1HOSTS = [ "host1", “host2” ] ; }
/* 子网2机器定义,必须为字符串数组 */
if ( typeof(SUB2HOSTS) == "undefined" ) { SUB2HOSTS = [ "host3" ] ; }
/* 协调节点定义,如果协调节点已经在 Catalog的编目组信息中,则此处填写一个可用Coord即可 */
if ( typeof(COORDADDR) == "undefined" ) { COORDADDR = [ "host1:11810", “host3:11810” ] }
/* 当前子网取值, 1表示子网1,2表示子网2,其它取值非法 */if ( typeof(CURSUB) == "undefined" ) { CURSUB = 1 ; }
/* 是否激活该子网集群,取值 true/false */
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = true ; }修改 host3 上的 cluster_opr.js 文件
/* 机器登入用户名定义 */
if ( typeof(USERNAME) != "string" ) { USERNAME = "sdbadmin" ; }
/* 机器登入密码定义 */if ( typeof(PASSWD) != "string" ) { PASSWD = "sdbadmin" ; }
/* 子网1机器定义,必须为字符串数组 */
if ( typeof(SUB1HOSTS) == "undefined" ) { SUB1HOSTS = [ "host1", “host2” ] ; }
/* 子网2机器定义,必须为字符串数组 */
if ( typeof(SUB2HOSTS) == "undefined" ) { SUB2HOSTS = [ "host3" ] ; }
/* 协调节点定义,如果协调节点已经在 Catalog的编目组信息中,则此处填写一个可用Coord即可 */
if ( typeof(COORDADDR) == "undefined" ) { COORDADDR = [ "host1:11810", “host3:11810” ] }
/* 当前子网取值, 1表示子网1,2表示子网2,其它取值非法 */
if ( typeof(CURSUB) == "undefined" ) { CURSUB = 2 ; }
/* 是否激活该子网集群,取值 true/false */
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = false ; }3. 执行初始化在 host1 的安装目录下执行如下命令
>sh tools/dr_ha/init.sh Begin to check args... Done Begin to check enviroment... Done Begin to init cluster... Begin to update catalog and data nodes's config...Done Begin to reload catalog and data nodes's config...Done Begin to reelect all groups...Done Done
4
灾备切换与恢复
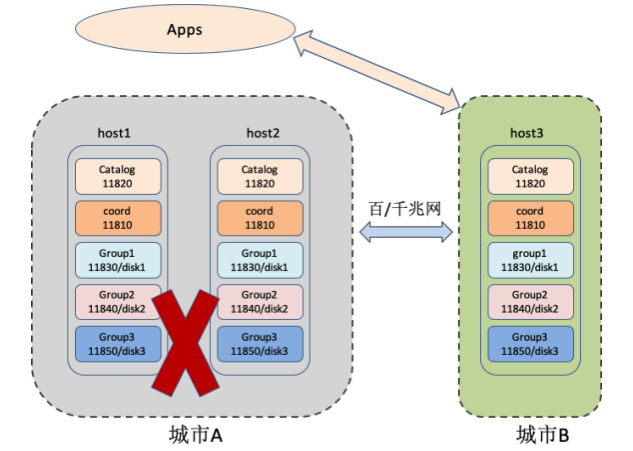
图3. 灾备系统切换
修改 host3 的cluster_opr.js中的配置项
/* 是否激活该子网集群,取值 true/false */
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = true ; }在 host3 的安装目录下执行命令
> sh tools/dr_ha/split.sh Begin to check args... Done Begin to check enviroment... Done Begin to split cluster... Stop 11820 succeed in host3 Start 11820 by standalone succeed in host3 Change host3:11820 to standalone succeed …… Stop all nodes succeed in host3 Restart host3 all nodes succeed Done
城市A的机器在故障恢复后,需要在 host1 上修改 cluster_opr.js 中的配置
/* 是否激活该⼦⽹集群,取值 true/false */
if ( typeof(ACTIVE) == "undefined" ) { ACTIVE = false ; }并在 host1 的安装目录下执行 sh tools/dr_ha/split.sh 命令,让其成为独立的只读集群,进行相应的数据修复。
当城市A的所有故障都完成修复,此时需要将上述2个城市中已分离的独立集群进行合并,形成异地在线灾备系统,恢复最初的状态。用户可以在 host3 和 host1 的安装目录下同时执行命令。
> sh tools/dr_ha/merge.sh Begin to check args... Done Begin to check enviroment... Done Begin to merge cluster... Stop 11820 succeed in host3 Start 11820 by standalone succeed in host3 Change host3:11820 to standalone succeed Restore group[SYSCatalogGroup] to host3:11820 succeed Restore group[group1] to host3:11820 succeed Restore group[group2] to host3:11820 succeed Restore group[group3] to host3:11820 succeed Restore group[SYSCoord] to host3:11820 succeed Restore host3:11820 catalog's info succeed Update host3:11820 catalog's readonly prop succeed …… Start all nodes succeed in host3 Restart host3 all nodes succeed Done
5
总结
在金融级强监管的要求之下,无论是“两地三中心”还是数据的容灾备份等要求,使得金融级的分布式数据库不断地在数据安全方面进行新的创新。未来,分布式数据库作为数据管理的最核心枢纽,也将不断提高数据安全、数据可用性方面的功能。通过双活、多活以及高可用灾备等机制不断创新,数据库安全将会提升一个新的台阶。






