由于互联网金融行业的发展,传统数据库的处理能力出现了瓶颈,数据库扩张的成本压力也越来越大。本次演讲将主要与大家分享应对这些问题的分布式架构与分布式数据库发展趋势及应用实践。
传统数据库曾尝试使用集群技术,即将多台服务器连接组合成为一个集群,用多台机器去扩展整个数据库的处理能力。但是这种方法的问题是,当机器的数量到达一个值之后,由于数据访问的冲突问题,必定会出现瓶颈,也就限制了集群扩展的规模。同时,集中式系统本身的购买和运维成本过高。以金融行业为例,由于银行的全年业务峰值仅出现在某些时间点,如双十一零点和春节前3-5天等,如果按照这样的特定时间点峰值付费,在峰值过后会造成资源的浪费。

总结来看,集中式架构存在以下问题,这些问题也是分布式架构转型的驱动力:
集中式架构普遍缺乏弹性伸缩的能力,随着交易量和数据量的增长,系统支持的容量容易遇到硬件或技术的瓶颈。尤其在支持面向互联网海量客户相关业务时,不能有效处理瞬时爆发的海量交易,严重制约了海量客户的获取以及大规模业务营销。
集中式架构采用单体应用设计,软件开发和运行管理的最小单元是应用,管理力度较粗,容易“牵一发而动全身”。应用的开发过程不易践行轻量化敏捷开发理念,系统在运行过程中容易出现单点故障,难以有效进行故障隔离。
基于集中式架构的核心系统基础设施使用小型机或大型机,硬件和软件采购成本高,开发和运维主要依赖于服务厂商,服务成本高,也无法做到完全自主掌控。
技术体系封闭,技术的发展高度依赖于厂商,特别是依赖国外厂商,商业银行的IT团队缺乏自主可控能力,在一定程度上存在信息安全风险。
从整个分布式技术的发展历程来看,它经历了原有的大集中架构,到后来SOA的分布式架构,到应用服务器的虚拟化阶段,再到以文件系统和对象存储为代表的数据存储分布式阶段。而现在进入了一个新的阶段,那就是基于分布式数据库技术与微服务架构及容器做整合,在联机交易业务上实现弹性伸缩和扩展。
下面来分享一下分布式架构的演进。
集中式架构,它的好处是部署简单。
应用与数据分离技术,这是SOA最早的理念,其优点是系统分治、并行开发。
使用应用服务器做一个集群,把应用负载做一个分担,提升并行处理能力,但是在数据层面没有实现改进。
Share-Disk数据库集群可以通过两台机器共享一个磁盘,提升数据库性能,但是其扩展能力较差,底层数据并没有实现分布式存储。
Share-Nothing数据库集群(MPP),与前者不同之处在于每个节点是区域自治的,可以把每个数据打散在每台机器上。该架构适合做分析,可以快速把数据分布到多台服务器上,但是不适合高并发联机交易处理。
读/写分离能够将数据库读的负载分担出来,提高读性能。
数据缓存,Cache数据的总量受限,同时存在引入Cache与Data同步问题,且Cache 分片难以管理。
分布式数据缓存和分布式文件系统,通过Redis把常访问的数据在应用服务器上做一个Cache,能够提升性能,增加容错,但是却增加了复杂度。
分布式数据库,底层的服务器是能快速扩展的数据库集群,数据库能根据容量弹性伸缩,也能够适用前端应用的负载变化。
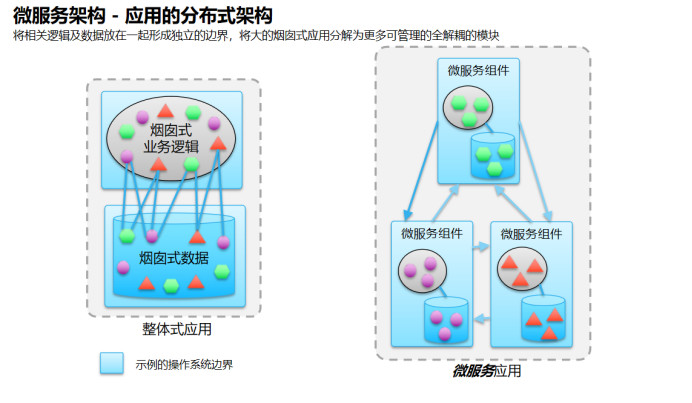
那么这是不是最终的分布式架构呢?我认为真正的分布式架构是在一个微服务集群当中,一个微服务组件能够满足一个业务功能,这个组件当中包含所有应用逻辑,缓存,应用中间件和数据库。一个服务组件分装在一个容器当中,能够实现弹性伸缩,应对业务前端的压力。所以微服务架构才是未来极致的分布式架构,因为它已经把前面讲的这些组件变成了分布式的,支持弹性伸缩和水平扩展。这和传统的架构完全不一样,微服务架构能够实现“去中心化”数据管理(Decentralized Data Management),它带来的演进是设计、开发一体化的技术。
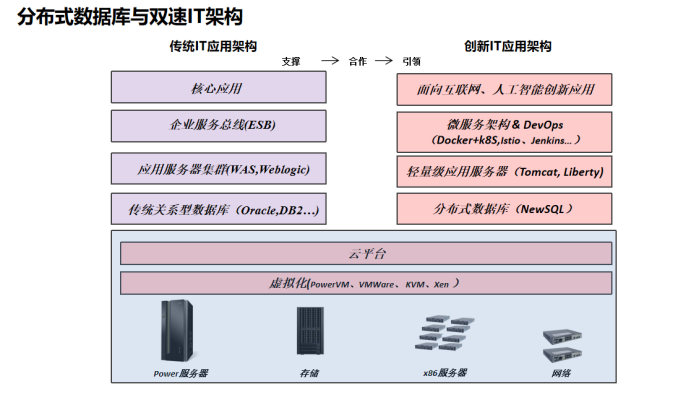
随着 IT 技术不断发展,企业IT系统基础逐步转向云化,应用服务形式也从集中式系统转向微服务形式,传统方案的一个应用、一个平台对应一个数据库的方式不再适用。同时,企业服务渠道也从过去的单一渠道,变成传统渠道、互联网渠道和智能终端渠道并存。传统关系型数据库所能提供的最高数据容量、并发支持能力和支持的数据类型多样性都越来越无法满足业务需求,严重制约了企业的发展。因此,应用分布式数据库能够为企业的微服务架构升级提供极为重要的助力。
目前,国产分布式数据库 SequoiaDB 巨杉数据库已在超过100家500强级别大型商业银行核心生产业务上线, 企业用户总数超过1000家,适用于联机交易、数据中台、内容管理等多种应用场景。
>>场景1:联机交易业务
SequoiaDB 巨杉数据库支持分布式联机交易业务。在多家银行的在线服务交易平台,尤其是近线数据查询、全行的无纸化办公系统当中得到应用。在某大型股份制银行的联机交易服务平台,巨杉数据库每天承载了全省上千万笔交易的查询负载业务量。
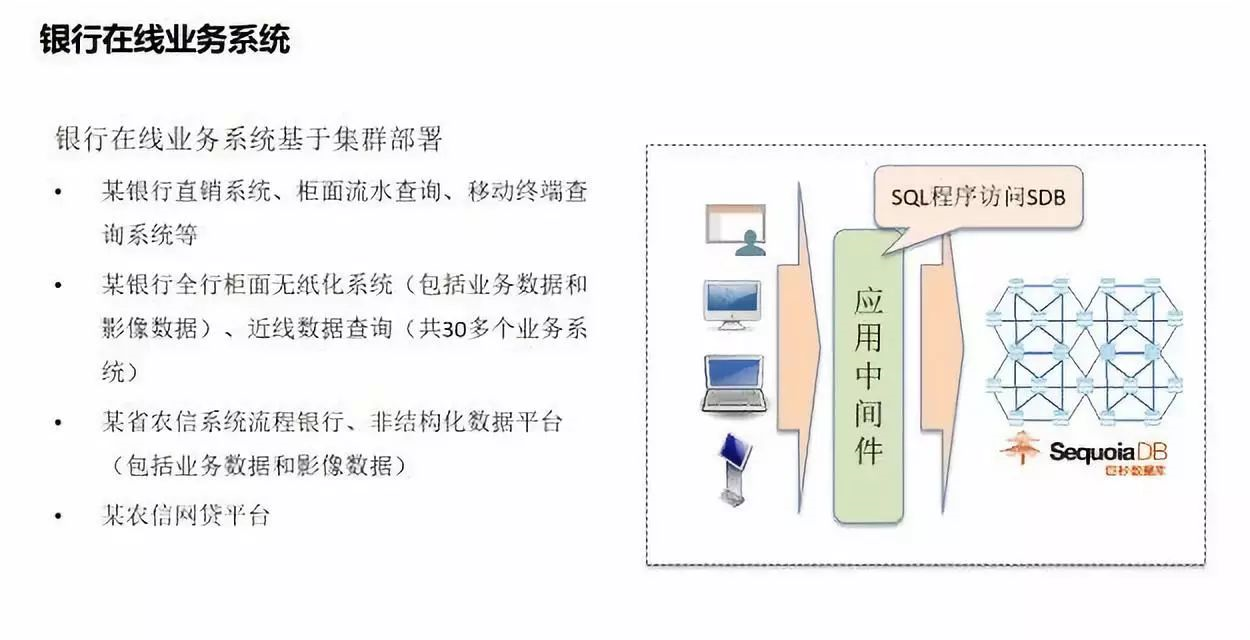
SequoiaDB 巨杉数据库采用计算层与存储层分离设计。数据库底层存储采用 Raft 算法实现分布式环境下数据一致性技术,并且结合多分区、事务隔离等技术,为用户提供完整的分布式事务功能。计算层是数据库的应用服务接入层,支持多种解析协议,包括:MySQL 协议、PostgreSQL 协议、Spark SQL 协议、Hive SQL 协议、S3协议、Posix 协议和 API 协议。用户可以根据不同场景,选择使用合适的计算层协议,完成应用服务开发。
>>场景2:数据中台
除了微服务的应用场景和交易型的场景外,SequoiaDB 巨杉数据库还普遍应用在数据中台上,这也是分布式数据库非常擅长的场景。在某应用场景中,全部历史数据都转移汇聚到了数据中台,集群规模超过150多台,并且还在不断扩展之中,数据无需进行归档动作。
>>场景3:内容管理
内容管理也是非常典型的一个应用场景。随着移动化与互联网技术的发展,影音扫描件数据已经渐渐在诸多行业中占据了越发重要的位置。例如,很多银行开设了无人网点,所有的远程柜员服务以及证照身份核实,均需要依赖影像视频扫描件才能够顺利进行。在新的技术趋势下,传统影像图片的存储机制早已不能满足海量且实时高频的非结构化数据读写访问。
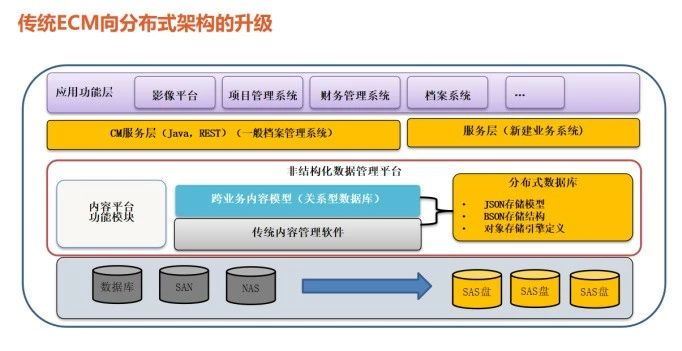
以基于Spring-Cloud框架的微服务架构为基础,SequoiaDB 内容管理解决方案通过可插拔组件与可配置流程,允许用户自由定义不同数据存储容器中对象文件的处理方式。譬如,对于合同扫描件类型的业务,系统可以将OCR文字识别模块直接加入非结构化文件处理流程,使得所有写入该容器的合同自动进行文字识别处理,并直接支持针对其内容的全文检索能力。
大型企业的应用平台正在向微服务架构进行转型。在微服务架构下,应用程序和数据库等底层平台的关系将会被重构,使用分布式架构的SequoiaDB巨杉数据库可以很好的适应微服务化架构转型的趋势。巨杉数据库采用的是计算存储分离的架构,底层是分布式数据库存储引擎,它是数据存储的核心,负责提供整个数据库的读写服务、数据的高可用与容灾、ACID与分布式事务等全部核心数据服务能力。数据库实例模块则作为协议与语法的适配层,用户可根据需要创建包括 MySQL、PostgreSQL与 SparkSQL 在内的结构化数据实例;支持 JSON 实例;以及完全兼容 S3 与 Posix 文件系统的对象存储实例。
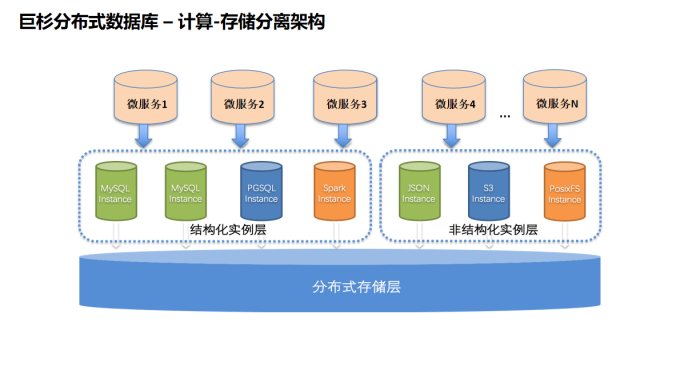
分布式数据库的特性是计算与存储分离,与微服务架构进行融合,保证自身的处理性能。基于微服务架构的创新IT架构所产生的应用都可以快速迭代、弹性伸缩,这也是未来分布式架构非常重要的使用场景。