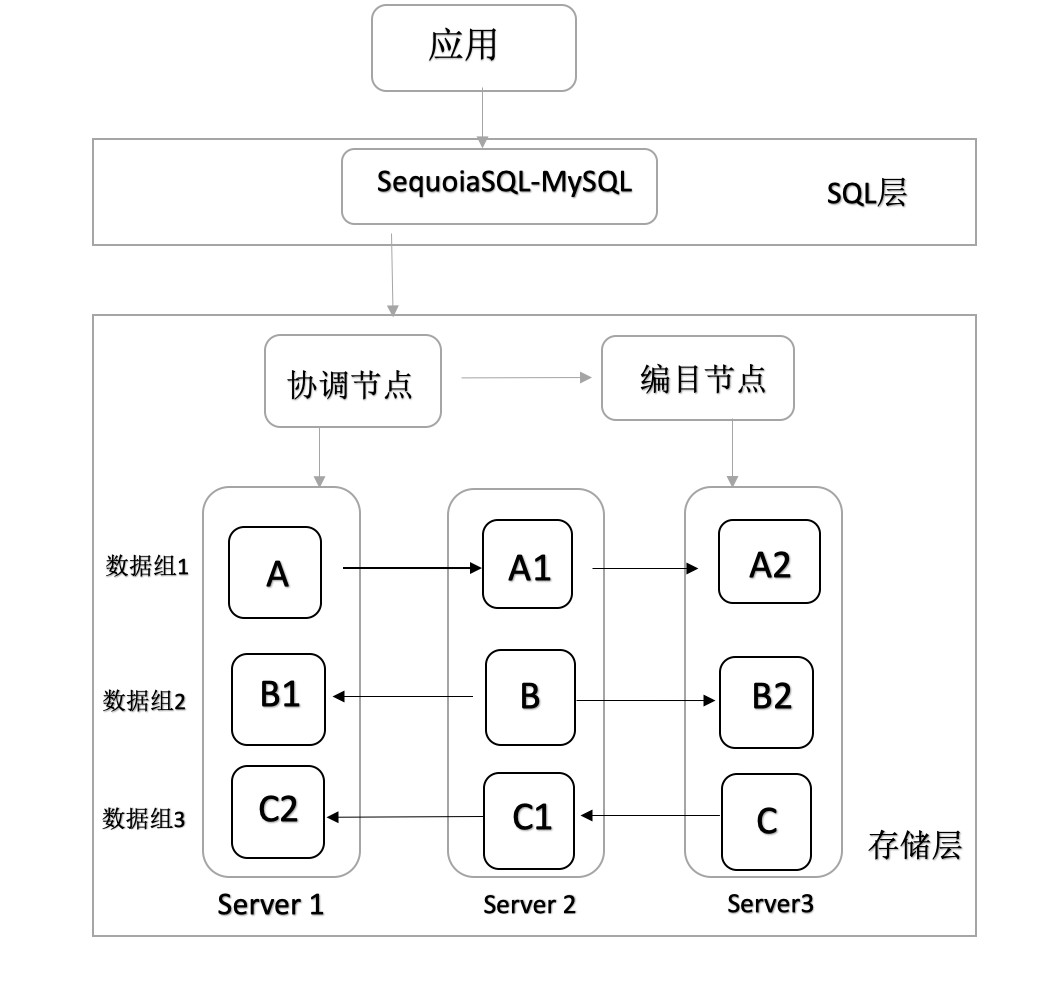
数据库的高可用是指最大程度地为用户提供服务,避免服务器宕机等故障带来的服务中断。数据库的高可用性不仅仅体现在数据库能否持续提供服务,而且也体现在能否保证数据的一致性。
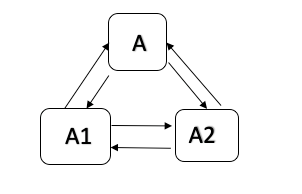
Note: 1)当主节点宕机时,需要从备节点中选举出一个新的节点作为新的主节点。 2)当备节点宕机时,主节点不受影响,等备节点恢复后,通过日志同步继续与主节点保持数据一致即可。
下面介绍当主节点宕机时,选举新主节点的过程。
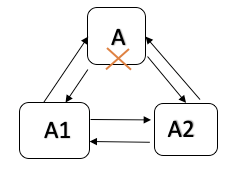
自己不是主节点
剩下的备节点占半数以上
自己的LSN比其它备节点的LSN新
测试环境说明
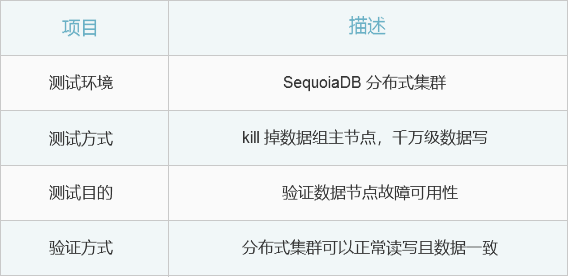
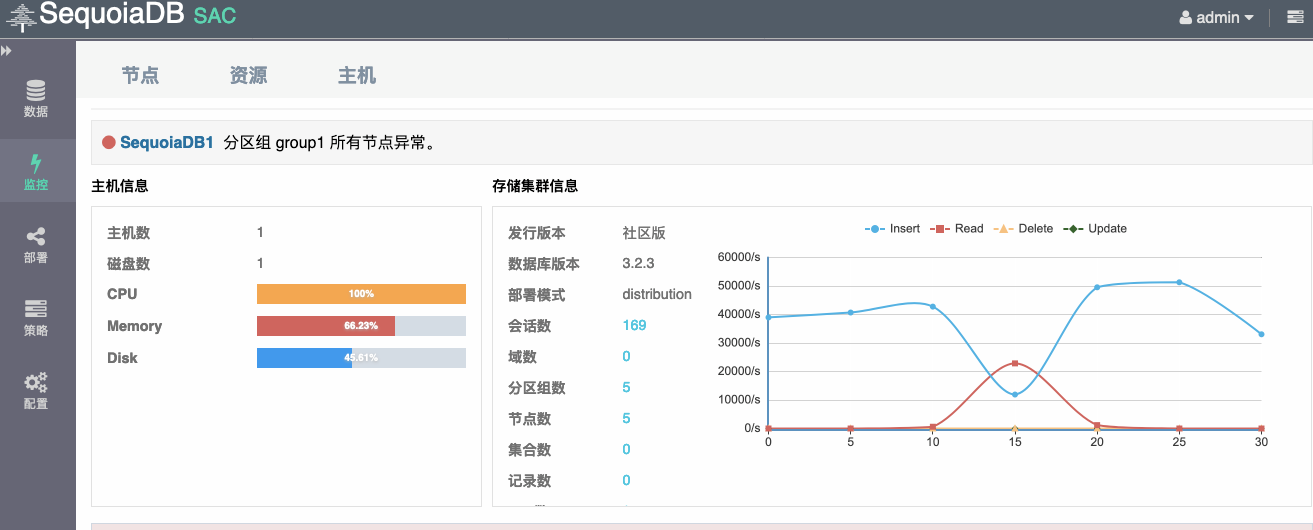
查看服务器集群状态
# service sdbcm status ..... Main PID: 803 (sdbcm) Tasks: 205 (limit: 2319) CGroup: /system.slice/sdbcm.service ├─ 779 sdbcmd ├─ 803 sdbcm(11790) ├─1166 sequoiadb(11840) D ├─1169 sequoiadb(11810) S ├─1172 sequoiadb(11830) D ├─1175 sdbom(11780) ├─1178 sequoiadb(11820) D ├─1181 sequoiadb(11800) C └─1369 /opt/sequoiadb/plugins/SequoiaSQL/bin /../../../java/jdk/bin/java -jar /opt/sequoiadb/plugins/SequoiaSQL .....
SequoiaDB 分布式集群中数据节点端口在11820,11830,11840;编目节点11800,协调节点在11810
sdbadmin@sequoiadb:~$ ps -ef|grep sequoiadbsdb admin 1166 1 0 Aug20 ? 00:02:23 sequoiadb(11840) D sdbadmin 1169 1 0 Aug20 ? 00:01:43 sequoiadb(11810) S sdbadmin 1172 1 0 Aug20 ? 00:02:24 sequoiadb(11830) D sdbadmin 1178 1 0 Aug20 ? 00:02:33 sequoiadb(11820) D sdbadmin 1181 1 0 Aug20 ? 00:04:01 sequoiadb(11800) C
kill 掉11820的主节点,执行查询和写入sql
sdbadmin@sequoiadb:~$ kill 1178 sdbadmin@sequoiadb:~$ ps -ef|grep sequoiadb sdbadmin 1166 1 0 Aug20 ? 00:02:24 sequoiadb(11840) D sdbadmin 1169 1 0 Aug20 ? 00:01:43 sequoiadb(11810) S sdbadmin 1172 1 0 Aug20 ? 00:02:24 sequoiadb(11830) D sdbadmin 1181 1 0 Aug20 ? 00:04:01 sequoiadb(11800) C sdbadmin 1369 1 0 Aug20 ? 00:01:33 /opt/sequoiadb....
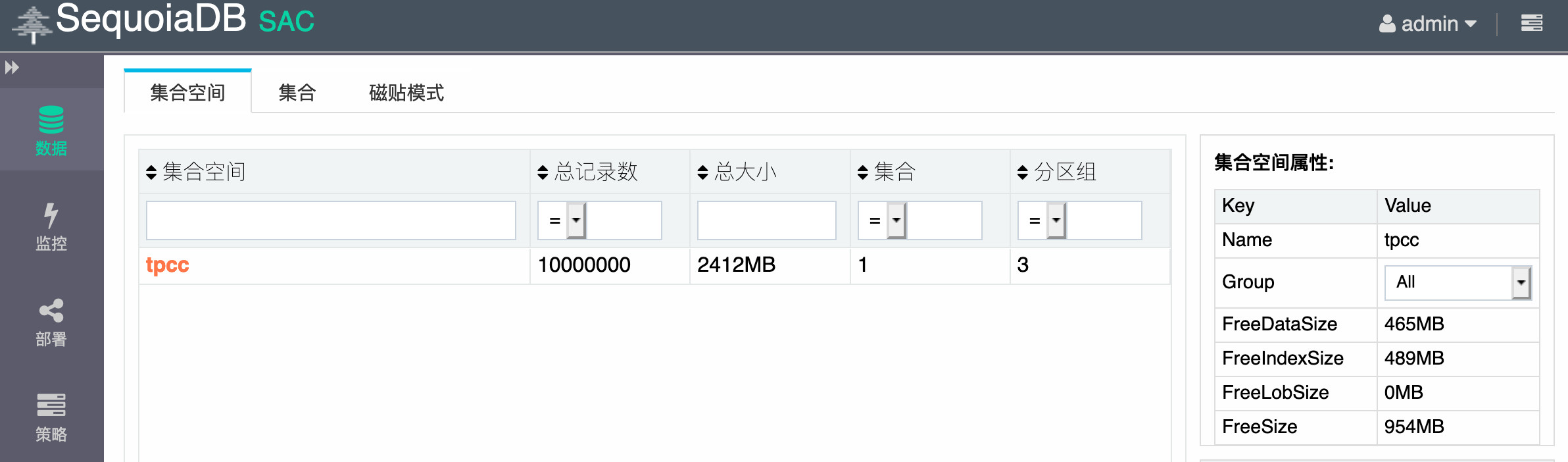
执行查看 sql,查看插入操作之前数据为121
mysql> select * from news.user_info; +------+-----------+| id | unickname | +------+-----------+ | 1 | test1 | ........ | 119 | test119 | | 120 | test120 | | 121 | test121 | +------+-----------+ 121 rows in set (0.01 sec)
执行写入 sql,查看插入是否成功
mysql> insert into news.user_info(id,unickname)values(122,"success"); Query OK, 1 row affected (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.01 sec) mysql> select * from news.user_info; +------+-----------+ | id | unickname | +------+-----------+ | 1 | test1 | ......... | 120 | test120 | | 121 | test121 | | 122 | success | +------+-----------+ 122 rows in set (0.00 sec)
Note: 如果需要获取 imprt.sh 脚本,关注“巨杉数据库”公众号回复 “imprt” 即可获取。
执行导入数据脚本
./imprt.sh 协调节点主机 协调节点端 次数 ./imprt.sh 192.168.1.122 11810 100
如图5所示,在执行导入数据时刻,kill 掉主数据节点,insert 写入下降,之后集群恢复高可用