With the mobile Internet and intelligentization of financial services, the new generation of distributed databases not only need to be compatible with traditional databases in terms of architecture and functional characteristics, but also driven by the requirements of micro-services and cloud-based architectures, the relationship between applications and databases platform is facing reconstruction.
Wang Tao, the co-founder and CTO of SequoiaDB, brought his keynote:<The development and future of distributed database>, and briefly discussed the current transition of application development from chimney architecture to distributed, and how the database should respond to micro-service application frameworks. The financial-level distributed relational database SequoiaDB adopts the "computing storage separation" architecture and powerful distributed transaction capability, which can meet the three application scenarios of online transaction, data mid-end and content management. Its latest version 3.2, has a lot of optimization and improvement based on 3.0.1 version. The overall performance has improved by 2-3 times, while saving 30% of CPU consumption.
At present, the 3.2 version of SequoiaDB has been released at official website download center.
We can take a quick look at the new features of the 3.2 release from several aspects.
SequoiaDB applies the architecture of computing and storage separation. The bottom layer of the database builds a scale-out storage cluster with storage nodes that support distributed transaction capabilities. The upper layer provides support for MySQL, PostgreSQL, and SparkSQL by creating multiple instances. At the same time, in addition to supporting structured SQL instances, SequoiaDB also supports the creation of JSON, S3 object storage, and unstructured instances of the Posix file system.
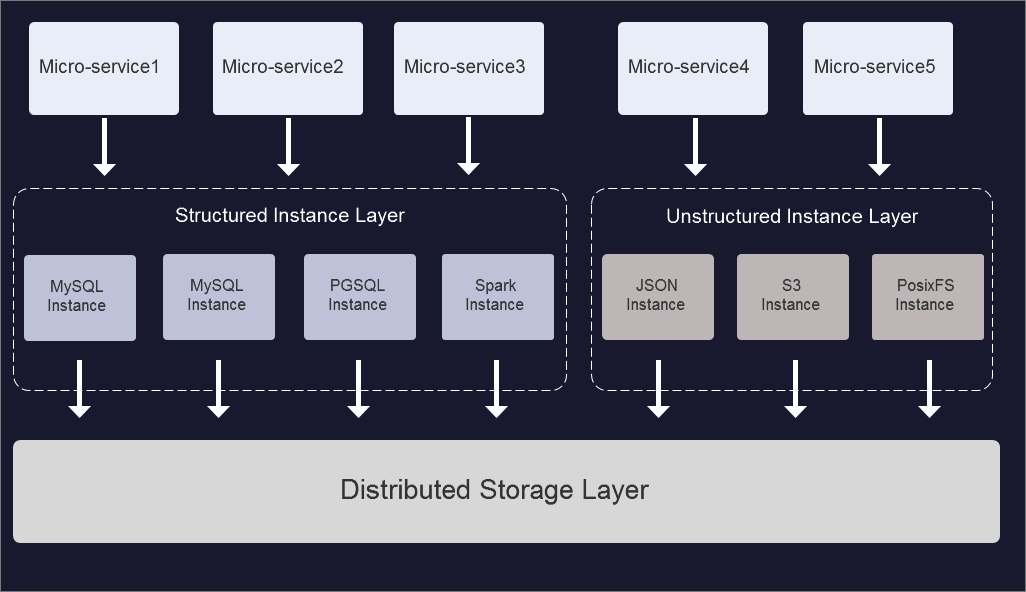
On the one hand, the distributed architecture of the SequoiaDB can provide unlimited horizontal expansion for data table. On the other hand, in the computing layer, SequoiaDB supports 100% compatibility with MySQL, PostgreSQL and SparkSQL protocols and syntax in the computing layer by providing different types of database instances. And it natively supports the distributed transaction capabilities with cross-table and cross nodes, and applications can basically perform database migration with zero-change.
In addition to structured data, SequoiaDB supports unstructured data including JSON, S3 object storage, and Posix file systems, and provides complete data service resource pooling facing to the micro-service architecture from upper-level.
Functions
Distributed Storage Layer:
• Support distributed transaction
• Support four isolation level: RU, RC, RR and Serializable
• Support reading MVCC feature
• Online data rebalance
• Physical isolation of multi-tenant data
• Physical isolation capability of HTAP transaction analysis business
• High availability based on Raft protocol
• Data synchronization strategy based on Logshipping mechanism, supporting multiple disaster recovery architectures such as dual-center in the same city, three centers in the same city, three centers in the two cities, and five centers in the three cities.
• Support active-active in same city
• Support consistency control strategies for table level
Distributed computing layer:
• 100% support native MySQL, PostgreSQL, SparkSQL protocols and syntax
• Support JSON, S3 object storage, and Posix file system protocols
• Compute nodes provide high availability capabilities similar to Oracle RAC
• Support MySQL and PostgreSQL views, storage procedures, triggers, auto increment fields, and etc.
• This version has been greatly optimized and improved on the basis of 3.0.1. In the distributed transaction type business, the overall performance is improved by 2~3 times, and the CPU consumption is saved by more than 30%.
Tools
• Provide Oracle OGG and IBM CDC real-time data synchronization solution
• Support real-time synchronization scheme for MySQL data
• Data import and export tool (sdbimprt, sdbexprt)
• Data file offline parsing formatting tool (dmsdump)
• Log file offline parsing formatting tool (dpsdump)
• Graphical deployment, management, monitoring tools (OM)
• Potential fault inspection tool
• Diagnostic log analysis tool
• Code flow trace tool (trace)
• Open source monitoring tool docking (zabbix, prometheus, grafana)
Scenarios
• Online transaction scenario:
Bank core transaction system, online loan core system, bank channel integration system
• Data mid-end scenario:
Historical data query platform, quasi-real-time data service mid-end, self-service query report platform
• Content management scenario:
Image platform, government e-license system, file management system





