
SequoiaDB数据分区的含义是,把逻辑上的一个大的数据集合,按某一个或多个字段的值将一个大的集合划分成若干个小集合,再将这些小集合分别存放在物理上的不同区块上(相同物理机器上的不同磁盘或不同物理机器上)。数据分区的好处不仅仅能带来数据访问速度的大幅提升,它还能带来管理和维护上的方便。
高速访问:在数据访问速度上,对集合数据进行数据分区后,当数据库接收到客户端请求访问该集合中的某一条数据对象时,数据库分两种情况对该请求进行检索,如果该集合已经建立了索引,并且该索引的索引字段正好包含此次请求的检索条件,数据库可以直接通过索引文件命中该数据对象。特别的,如果该集合是通过垂直分区的方式进行数据分区,当请求的检索条件包含主表的分区键时,将直接访问包含该分区键的对应子表,仅仅对该子表进行全表扫描,而不用对整个集合进行全表扫描。
无索引字段:如果检索条件不包含在任何索引的索引字段中,则数据库将进行全表扫描,在该集合对应的所有的分区上同时进行数据检索操作,换句话说,也就是在各个分区对应的不同的物理机器或磁盘上并行的进行数据的检索,这样就完成了将某一个请求映射到不同的物理磁盘以平衡IO。从而线性的提高了检索速度。
数据的管理和维护:对数据进行数据分区后,将会让一个大的数据集合,划分为若干个小的数据集合,这些小的集合分别可以存储在不同的分区组上,如果某个分区组出现意外故障,则可以只从该复制组的另一台机器上同步该分区的数据过来修复分区即可。不用进行整个集合的修复的高IO耗时操作。
默认情况下即创建集合空间和集合时不指定任何数据分区相关的参数,该集合存储数据时会将数据存放在一个复制组内。随着集合数据量的增加和频繁的CURD操作。将会导致物理机IO的增加,从而导致物理机的高负荷压力增加和访问集合数据的速度变慢。
SequoiaDB提供三种数据分区类型,即水平分区、垂直分区和混合分区。注意,这里的分区概念是一种逻辑的概念,通过逻辑分区的概念,方便用户更好的区分和管理数据。
水平分区
水平分区又称为数据库分区或横向分区,水平分区可以将集合按照分区键(包含一个或多个字段)切分成若干分区,并将分区指定到不同的复制组中,图示如图1:
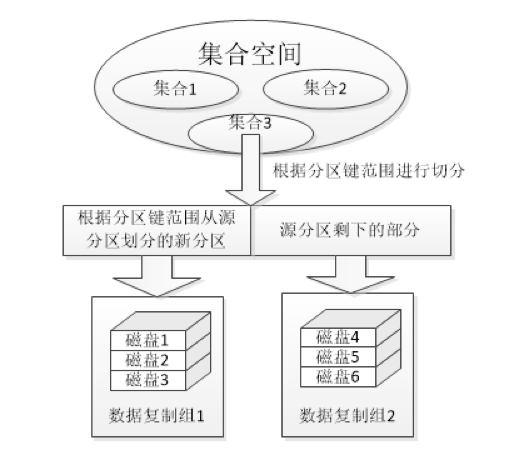
图1
图中,将集合空间中的集合2进行了水平分区,将集合中的数据按照分区键切分到范围为1-N的分区中,每个分区可以对应不同的复制组,当请求访问某一条数据对象,就会将请求分发给不同的复制组,将查询速度平均提高了N倍,线性的提高了检索速度。
垂直分区
垂直分区又称为集合分区或纵向分区。SequoiaDB集群环境中,用户不同与传统关系型数据库的视图的概念,将几个表的数据通过视图的方式拼合在一起构成一张虚表,从逻辑上层面上将所需要的数据抽取出来。
SequoiaDB的垂直分区虽然也是将不同的集合数据通过一个主集合进行统一管理,主集合也不存放数据记录,只是作为方便维护子集合,不过是通过集合中的某一个或多个字段作为分区键,将集合划分成若干个子集,并在主集合和子集合上通过分区键范围建立主集合和子集合之间的关联
协调节点处理客户端的一个数据请求进行检索时,在主表上进行检索,将会根据主表上的分区键范围,将该数据访问请求分发到映射的各个子集合中,如果查找条件包含主表的分区键字段,将直接对相应的子表进行查找,直接在该子集合上检索该数据,而不用进行在所有子表上进行扫描。否则,将请求分发到各个子表中,进行全表扫描,并行的对数据访问请求进行快速检索。
每个切分的子集合称为分区,分区映射的集合成为子集合;一个分区只能映射到一个子集合中,但一个子集合可以承载多个分区,可以通过垂直切分操作,对分区和子集合进行重新建立新的映射关系。如图2:
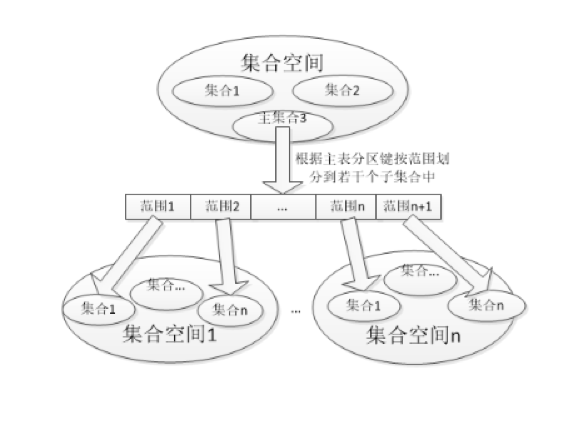
图2
混合分区
混合分区即是结合垂直分区和水平分区的数据切分类型,将一个大的集合先进性垂直分区到多个子集合中再对各个子集合进行水平分区,将自己和按照自己和的分区键切分到多个更小的集合中。可以理解为将图二中的集合空间1和n看成图一中的集合空间。将某个子集合进行进一步的划分,可以参考垂直分区分区和水平分区,进行理解。

图3
多维分区是SequoiaDB分布式数据库的一个重要技术特点。
在大部分新型分布式数据库中,表或集合中的数据一般仅能通过针对主键或分区键进行散列,来判断某一条记录应当被存储在哪个物理分区中。这种做法是一维分区。
而SequoiaDB则创造性地引入了多维分区的概念,除了使用分区键将记录散列在不同节点以外,还能够在每个节点内部根据其他维度进一步分区,使得在高存储密度服务器中的大表按照额外提供的维度,被进一步切分缩减。这种机制在管理海量数据时会大幅度提升性能,降低磁盘访问开销。
图4显示了在一个分区内,SequoiaDB按照时间维度进行切分,使得每一个子分区仅包含指定时间范围内的数据。
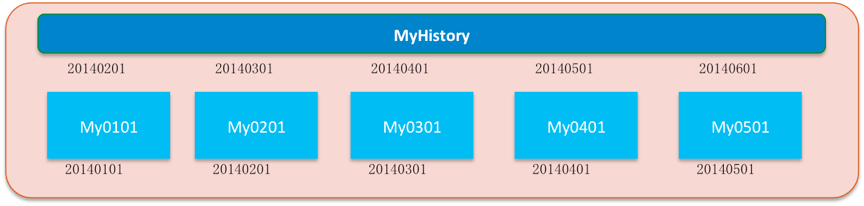
图4:SequoiaDB多维分区机制
在使用多维分区技术时,开发人员不需要关注底层数据库集合的具体切分逻辑。数据库会自动根据查询条件判断,该查询仅需要查找特定某些子分区,或需要在全部子分区上进行检索。
SequoiaDB提供以下两种分区方式,范围分区和散列(Hash)分区。
其中水平分区下支持两种分区方式,而垂直分区下只支持范围分区。
范围分区(Range)
当集合分区方式为范围分区时,当协调节点接到数据请求时,会将请求数据的分区键的值,在各个分区的分区键范围中查找落在分区区间内的分区,选择该分区响应请求操作,分区范围不能交叉,当插入一条记录到不存在的分区范围时,则定义为 Undefined 类型。范围分区的图示如下图4所示:
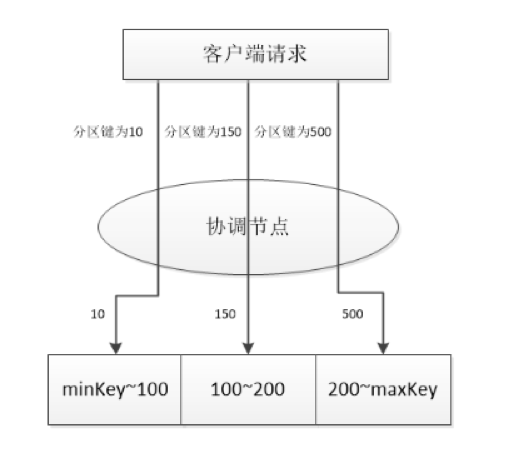
图5
其中假设a为分区键,分区1的分区键范围为100以下,分区2的分区键范围为100~200,分区3的分区键范围为200以上。分区键为100以下的记录,将会存储到分区1中,分区键为100~200的记录,将存储在分区2中,分区键为200以上的记录将会存储在分区3中。
散列分区(Hash)
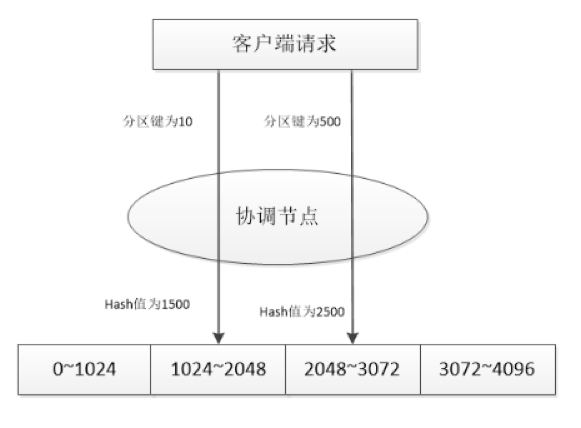
图6
上图中的hash后的值,只作示意,并非实际hash运算的结果。Hash函数运算后的分区键在0~1024之间的将存储在分区1内;1024~2048之间的将存储在分区2内;2048~3072之间的将存储在分区3内和3072~4096之间的将存储在分区4内。
当向SequoiaDB集群添加或删除分区时,用户可以对集群的拓扑结构进行动态不停机调整。数据库确保在数据重分布的过程当中,对业务读写数据操作做到完全在线,功能不受影响。
SequoiaDB提供以下两种数据切分的方式(范围切分和百分比切分,两种分区方式均支持着两种切分方式)。
范围切分
指定一个切分的范围,具体是在split函数指定原数据组,目的数据组,范围切分下限,范围切分上限。来进行范围切分。
百分比切分
定一个切分的范围,具体是在split函数指定原数据组,目的数据组,百分切分比例。来进行百分比切分。其中range数据分区类型的百分比切分,如果集合是空的,无法进行百分比切分,找不到百分比切分点。需要集合中有数据。
分区是分布式数据库的重要功能,本文也介绍了巨杉数据库的分区功能和一些特点。具体的最佳实践将在我们的“最佳实践”系列文章中向大家做详细的介绍和操作说明。
用户还可以参考分区功能的使用文档:
http://doc.sequoiadb.com/cn/SequoiaDB-cat_id-1454575727-edition_id-0
数据切分使用文档:
http://doc.sequoiadb.com/cn/SequoiaDB-cat_id-1432190620-edition_id-0







