
随着互联网和移动技术的不断年发展,数据呈现急剧增长,这对数据存储和管理提出了更高要求。以大型商业银行为例,通常它们拥有成百上千个业务系统以及上亿用户的海量数据,数量呈现指数级增长,从TB级别增加到PB级别,未来很快就会增加至EB级别。因此,海量数据的管理就成为了企业关心的头等大事。
反范式化
反范式化的运用主要用来减少多表关联,提高查询的响应速度。大数据场景下,传统数据库在使用反范式化技术提高性能的瓶颈主要有两个:高成本与扩展难。
在关系数据库中,一个业务场景的数据通常需要多张表的数据通过关联得出结果集。一般情况下,业务应用系统要求数据查询的响应速度要在2~3秒。多表关联会极大的影响查询的响应速度,而且查询效果不稳定。使用反范式化,将所需的全部数据放在一张表,可以解决多表关联带来的问题。
在大数据场景下,将多个表的数据去范式化整合成一张表,会比多表关联的效果好,但会极大的增加冗余数据,每条数据的数据长度可能会成倍增加,影响查询效率。另一方面,去范式化极大的增加冗余数据,使得存储等硬件资源紧张。而传统数据库只能进行纵向扩展,扩展成本高、扩展难,很容易达到扩展的极限。当数据量大大一定程度,性能就无法再进一步提升。
缓慢渐变维度
对于状态表来说,数据更新后该记录的历史数据就会丢失,但丢失的历史数据可能是有业务价值的。缓慢渐变维度的运用,主要解决如何保存数据记录的变化过程的问题,以便对数据变更的跟踪。传统数据库通常运用新增记录来实现这种功能。在大数据场景下,运用缓慢渐变维度来记录历史数据,数据量将增长2~3倍,甚至更多。与去范式化应用一样,无疑给传统数据库的性能雪上加霜。
关系型数据库的局限性
当单表数据量达到十亿级时,传统关系型数据库很难完成多表关联查询操作;当单表数据量达到百亿级时,其完成单表查询都面临很大性能压力,更不用说多表关联查询了。想要避免多表关联只能对查询表添加冗余数据,同时又会导致数据过度膨胀,进而降低查询效率并导致存储紧张。此外,传统关系型数据库的扩展性差且成本昂贵,使其在处理大数量级数据时显得那么的无能为力。
在单表的大数据场景下,响应速度、操作性能将会是在线用户考虑的最重要因素。而SequoiaDB作为一款分布式数据库,可以完成传统关系型数据库不可能完成的任务,解决单表的大数据查询问题。接下来,文章也将介绍在数据迁移进入SequoiaDB过程中和日常使用过程中,运用反范式化和缓慢渐变维度处理方式,对大数据合理规划,实现业务需求和提高数据操作性能。
SequoiaDB的分布式架构能灵活动态的实现横向扩展,能将一个百亿级的大表切分,分布存储在各个数据节点上。这样,如果集群达到上百个,单节点数据就只是千万级别,再结合垂直分区的应用,查询性能将大幅提升。
SequoiaDB采用JSON的数据存储模型,数据记录的长度不会影响查询效率。SequoiaDB中每条数据记录都是一个整体,数据记录头会记录数据长度,能快速定位到下一条数据记录的位置,所以数据记录的长短不影响查询效率。
一方面,采用JSON的数据存储模型,不需定义数据结构。反范式化过程中,会因业务需要调整数据结构,SequoiaDB数据库能在不影响历史数据的情况下,动态调整数据结构。缓慢渐变维度也能运用这个特性新增字段来记录历史数据。另一方面,JSON的数据存储模型能储存嵌套数据,为缓慢渐变维度运用提供了另一种思路,使用嵌套数据来保存记录历史数据,即能达到应用要求又能减少数据冗余。
再者,SequoiaDB数据库能部署在廉价的X86 PC服务器上,并以多副本形式提供高可用,能低成本安全方便的实现横向扩展,按需提升数据库性能。本文第三章测试数据也表明,从数据的迁移入库到数据应用查询场景,SequoiaDB对大数据应用提供了强有力的性能支持。
数据库总体架构设计,决定数据库特性,决定数据库的应用场景。下面简要介绍在大数据场景下,为什么要使用反范式化、为什么能使用缓慢渐变维度这些技术所涉及到的数据库特性。
SequoiaDB 作为典型 Share-Nothing 的分布式数据库,同时具备高性能与高可用的特性。SequoiaDB 的整体架构图如图 1 所示。
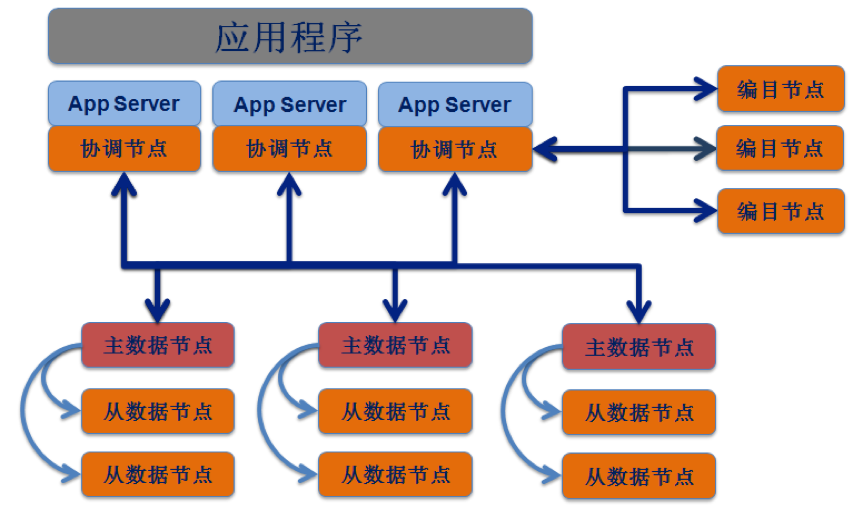
图 1 SequoiaDB集群架构
特性1:分布式架构
在大数据场景下,传统数据库最常见的就是性能瓶颈和存储空间不足。性能瓶颈一般只能通过添加内存和CPU、优化数据库等手段处理;存储空间不足通过添加硬盘解决。但单机环境下,CPU、内存、硬盘的接口都非常有限,用户为了解决性能瓶颈不得不高价购买服务器代替原有服务器,只能使用昂贵的NAS存储、SAN存储代替原有DAS存储。造成资源的浪费不说,系统和数据的迁移也是个非常麻烦和复杂的事情。
分布式存储设计,一方面将大量数据分散在各个数据节点,使数据由大化小;另一方面解决系统的横向扩展问题,使得数据库在遇到性能瓶颈时能通过添加机器方式,以低成本提升系统性能。这是SequoiaDB能够处理大数据的重要因素之一。
分布式架构是从架构层面将集中的硬件资源分散到网络节点上,解决资源扩展问题。
特性2:多维度分区
SequoiaDB提供水平分区、垂直分区和混合分区,三种分区方式。其中,混合维度分区即水平分区+垂直分区。
水平分区是采用分片技术为系统提供了横向扩展机制,将数据按照分区键切分成若干分区分别存放在各个数据节点中;垂直分区是将几个表的数据通过类似视图的方式拼合在一起构成一张虚表。水平分区在物理层面对大数据进行合理分配,垂直分区在业务逻辑层面对进行合理分配。其分区过程对于应用程序来说完全透明。
SequoiaDB采用水平分区和垂直分区将一张表的数据合理打散到分布式存储中,当集群水平扩展时,数据能动态进行切分,使得横向扩展能有效提高对数据的操作性能。
水平分区是从技术层面实现合理利用分散到网络节点上的硬件资源,是分布式架构的技术应用。
特性3:灵活的数据类型定义
SequoiaDB采用JSON文档类型定义数据存储模型(类对象存储)。JSON作为当今应用设计中主流的存储与通讯协议格式,使用的数据模型与平台、语言无关,从而为企业内异构数据的整合提供了标准方式。传统企业内存在大量的结构化数据资产需要用分布式大数据的手段处理,同时又希望尽量保留其关系型结构,JSON数据模型则恰好满足这些需求。解决了传统存储结构僵化、设计复杂、性能低下的问题。
特性4:多副本
SequoiaDB采用多副本主要为了满足高可用。由于SequoiaDB能在较廉价的x86服务器上运行,存储可也使用普通商用硬盘,硬件可靠度较低。SequoiaDB数据库为采用多副本来满足高可用,在业界普遍使用三副本,这样的硬件成本还是相当低廉的。
另一方面,多副本还能提高并发度以及实现读写分离机制,大大提高了数据库的响应速度和高可用性。多副本机制对应用程序来说完全透明,能天然实现异地灾备存储。
特性5:支持SQL
SequoiaDB全面支持标准 SQL,提供高性能的 SQL 引擎组件。支持标准 SQL 的访问,包括完整的 CRUD 以及事务的支持,深度数据压缩等多项全新功能,、能够兼容传统应用,并最大程度满足传统应用开发人员对于数据库 SQL 访问方式的需求。
海量历史数据在线查询平台是巨杉为客户打造的一个海量历史数据在线查询平台,能支持超过十年的业务历史数据实时查询功能,实时查询性能表现非常优异,将近上百亿的数据表,能在3秒内完成简单的查询功能,复杂的查询功能也能在10秒内响应。
在业务系统使用的传统关系型数据库设计中,数据模型的构造需要遵从范式规范,如第三范式(3NF),以减小数据库冗余和避免数据冗余带来的不一致冲突。
在海量历史数据在线查询平台的海量的历史数据中,通过反范式化来实现实时查询的目的。大数据场景下,数据查询如果采用多表JOIN,无法实现数据高效访问。但通过数据模型去范式化,减少多表关联,能达到数据高效访问的目的。
海量历史数据在线查询平台将业务系统原有的数据模型反范式化。根据业务系统逻辑,结合业务使用需求,将业务系统多张表进行关联打平,将需要记录数据变化过程的表运用缓慢渐变维度技术保存历史记录,最终形成一张大宽表。如图2所示,海量历史数据在线查询平台通过采集交易系统数据,将数据反范式化打平后,储存到SequoiaDB数据库供不同系统进行在线查询。
目前,巨杉已经帮助多家大型银行客户,完成了海量历史数据在线查询平台建设,实现账单等历史数据的在线实时查询,提高了客户的数据查询能力和办公效率。
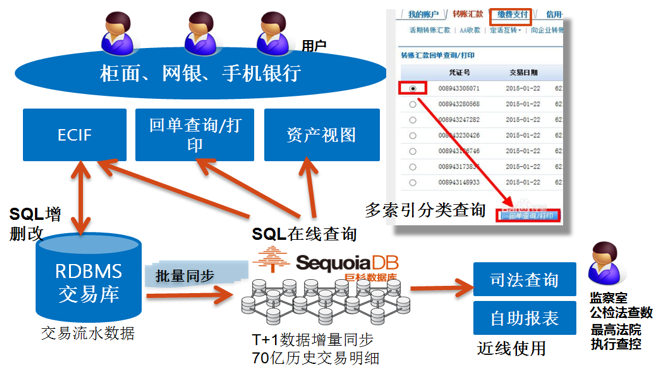
图 2 海量历史数据在线查询平台应用场景
在大数据时代,数据与日俱增,呈几何增长。传统数据对大数据的运用瓶颈日益显现。在大数据场景下,SequoiaDB数据库能为用户提供高性价比、高性能和高可扩展的数据库存储解决方案。







