作者介绍
萧少聪,巨杉数据库资深总监,负责公司技术社区及生态发展。2015-2018年PostgreSQL中国社区主席。历任阿里云数据库高级产品高级专家、华为存储产业营销专家。2011年成为全国首位获得EnterpriseDB公司Postgres Plus Professional认证的专家。2009年通过红帽全球最高认证RHCA,成为国内前20名考取此认证的架构师。
参与著作:
2011年参与编写《Linux系统案例精解》
2013年参与编写《深入理解大数据:大数据处理与编程实践》
很多朋友可能是通过2011年成立的PostgreSQL中国社区认识我的,今年,我加入SequoiaDB巨杉数据库,期待在分布式数据库领域,继续与大家探讨无尽的技术话题。周日,转发了公司公众号文章《SequoiaDB SQL查询语句执行过程》后,不少同行都问我SequoiaDB是不是就是基于一个分布式的存储,并对接上层的各类数据库及存储操作协议,形成兼容架构,这是不是就是巨杉的核心特色。
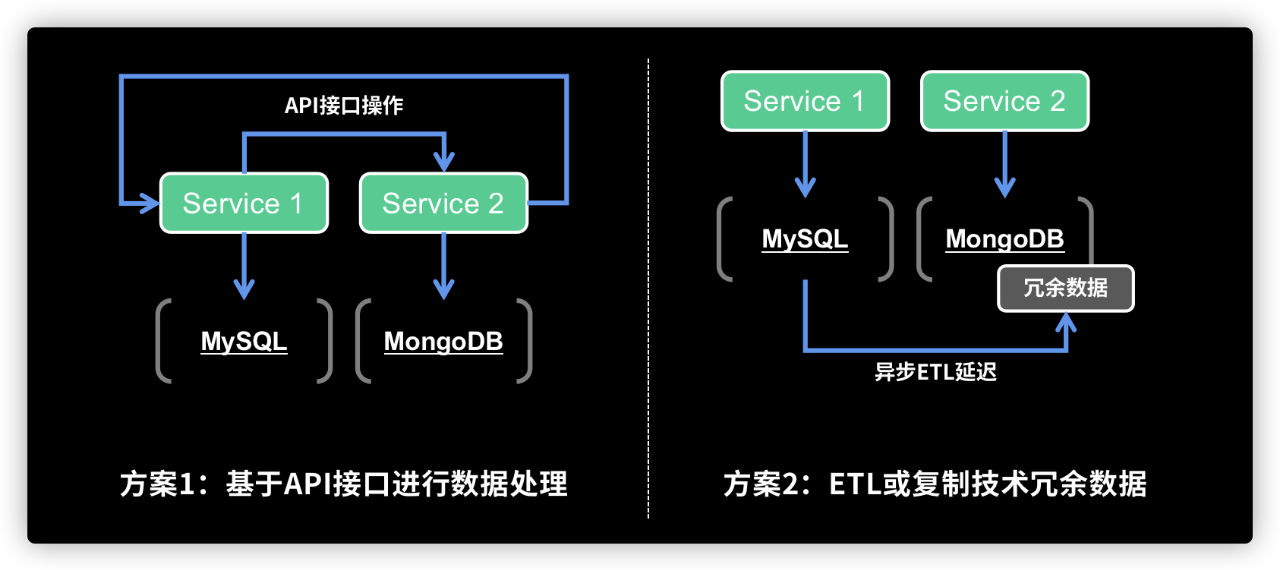
市场上云计算厂商提供了支持不同协议的云数据库服务,受到不少用户青睐,特别是使得DBA可以减少很多安装部署及维护不同数据库架构的工作。但一方面,即使是使用云数据库,每个不同的数据库引擎之间,数据依然是各个孤岛,与上图一样方案1、方案2中的数据交互问题没有解决。如果需要进一步进行“数据中台”整合,还需要单独的ETL操作汇总到单独的数据仓库。另一方面,从平台的角度,用户必须使用公共云,或在企业中花费巨资,部署绑定某个云厂商的私有云“全家桶”方案,才可获得云数据库基于资源池化的存储计算分离,及多引擎支持能力。
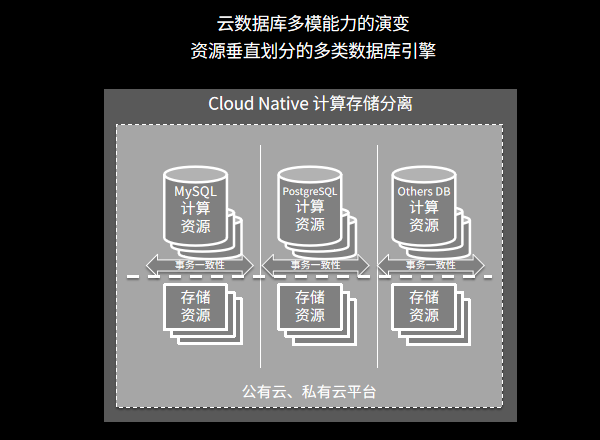
巨杉数据库提供引擎级多模能力,在SequoiaDB的原生分布式数据库基础上,同时支持多种数据库,现有的v3.4版本已经支持:MySQL、PostgreSQL、Spark、及原生SDB JSON API,新的v5.0版本更将支持MariaDB、S3兼容协议,也欢迎关注并报名参加我们10月22日的SequoiaDB v5.0发布会。
谈到这里,让我们拆解一下巨杉数据库SequoiaDB是如何支持多个不同的数据库引擎,以及在真实的业务场景中如何协助研发及DBA取得各自的平衡。如下图,从大粒度来拆解,SequoiaDB分为「SequoiaDB Instance Layer计算实例层」、「SequoiaDB Database Layer分布式数据库层」两层。顾名思义,分布式数据库层本身就是一个完整的数据库,通过SDB JSON API可以通过shell或SDK的方式进行数据操作,具备完整的事务一致性及数据库所有应有的管理功能。而计算实例层则提供更广泛的通用联机引擎模型,及对象引擎模型,SequoiaDB的多模支持能力不限于数据类型,而进一步实现了「引擎级多模」支持。
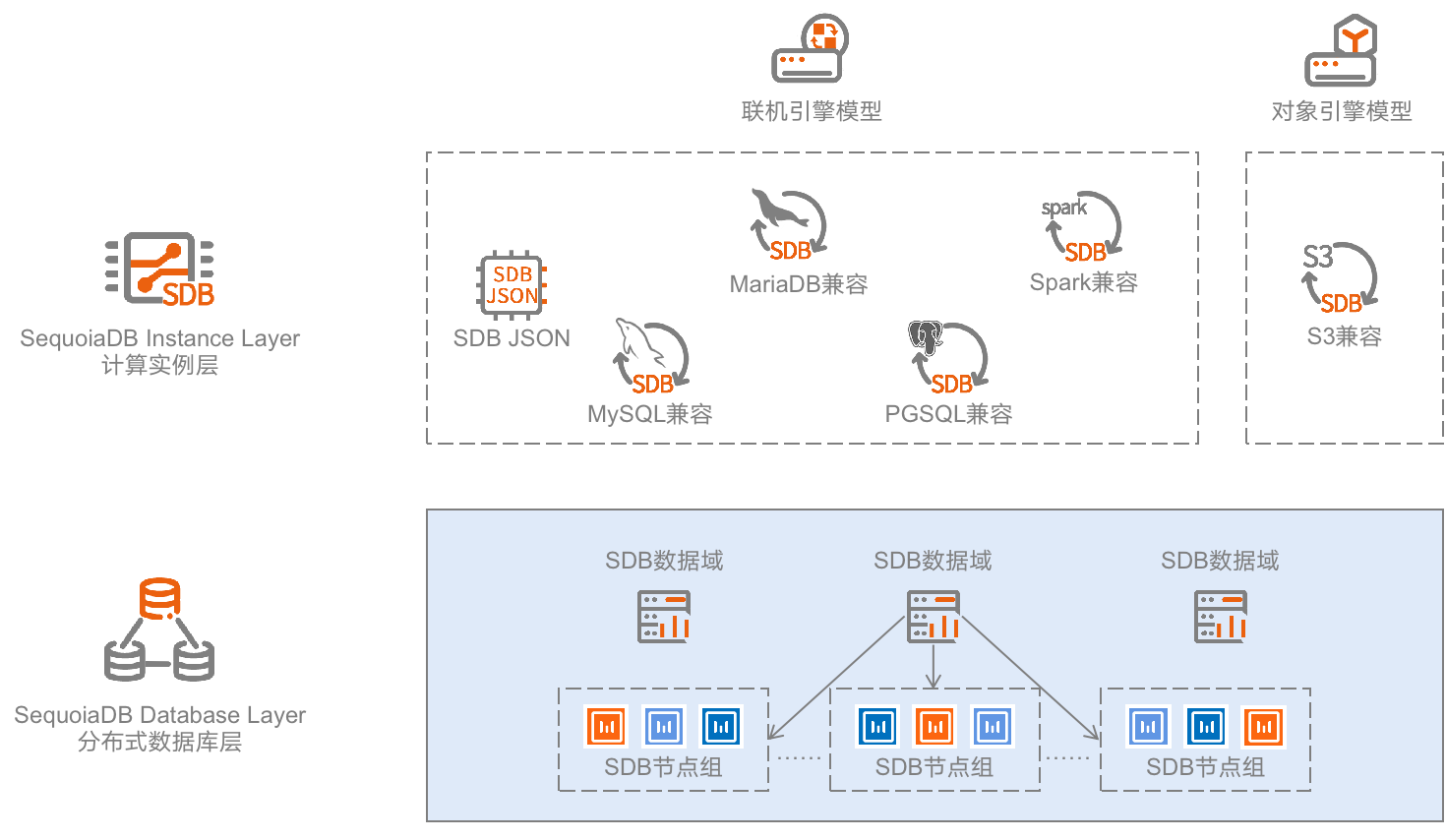
基于「引擎级多模」能力,MySQL及MongoDB可以同时挂载相同的SDB数据域,即可实现不同的数据引擎共享同一个数据域的数据,实现实时共享的读写处理,无须任何ETL操作,因此也不会导致因ETL带来的数据延迟问题及数据冗余空间浪费。同时,研发人员可以直接将原有的MySQL或MongoDB应用直接跑在SequoiaDB中,无须因为使用新的数据库而进行程序修改。
精明的小伙伴是不是发现了,MySQL和MongoDB共同使用一份数据?那数据库的事务一致性在什么地方处理呢?难道数据不会冲突吗?这就来源于SequoiaDB的架构设计了,SequoiaDB与众多云原生数据库一样,提供存储计算分离的能力。但不同的是,SequoiaDB底层的存储引擎实际上就是一个完整的分布式数据库,具备完整的事务一致性、排序过滤、下推计算等能力。而上层计算实例层只承担SQL或API解析及业务计算的工作,所以不同引擎下发的操作,事务一致性在分布式引擎层进行控制。
到这里,一些朋友所疑惑的,SequoiaDB是否基于xxx开源数据库的疑问也就揭开谜底了。SequoiaDB原生分布式引擎源自2011年,100%自主研发,基于独特的技术架构及稳定性实践,已经在近百家金融机构上线生产系统。如果您有哪些疑问想与我们交流,欢迎留言。同时也诚邀您关注及参加10月22日举行的SequoiaDB v5.0新版本发布会,了解我们更多的技术特性。







