分布式架构+多模正在成为新一代数据库技术的主流技术架构,其中处理非结构化数据的能力成为新一代数据库的关键功能点。本文也将从一个实际企业案例出发,介绍分布式数据库在影像数据管理场景下的最佳实践。
在银行业竞争越来越激烈的背景下,部分银行由于非结构数据部分或全部存在于各自系统中,或尚未形成完整统一的存储管理模式,信息共享不及时导致信息孤岛效应明显,影响银行在部分业务上的决策。并且现有的非结构化内容管理平台已经不能满足在产品创新、服务创新和流程创新上的新需求,并且部分银行已经提出流程银行的战略构想,将企业内容应用以及集中作业和碎片录入系统,作为全行流程银行的基础平台。
目前金融企业内容管理平台存在以下几个问题:
需要实现跨业务的企业内容管理系统整合和处理,由于部分业务系统企业内容数据独立,未形成企业级内容统一存储,造成在需要企业内容数据跨业务进行处理和展现时,不同业务系统对企业内容数据的调用处理复杂
数据量增长太快,传统企业内容管理系统依赖于关系型数据库,在记录数超过亿级别之后,检索内容记录的响应时间变慢,很难实时过滤企业内容数据特征比如基于内容标签的实时推荐,并且无法在全表多索引数据回溯
传统企业内容管理系统建设成本较高,水平扩展复杂。在银行海量数据存储需求的背景下,需要高性价比的数据存储持续在线,保留源结构的长期数据并且能做到秒级快速索引数据回溯,以满足复杂联机交易和历史数据查询需求,因此,未来企业内容管理系统需满足在线水平扩展
为了满足未来全行级流程银行建设的要求,需要建设能够服务于全行各种业务流程化处理的影像及相关系统处理平台,将其他分散的非结构化数据进行统一的管理。
用低成本的分布式存储管理海量数据
非结构化数据和结构化数据的统一管理
高并发处理能力,随集群水平扩展性能线性提升
同城灾备或异地灾备
多中心部署
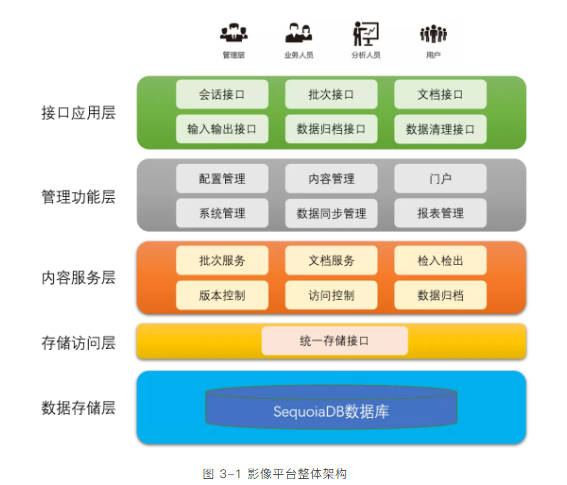
批次服务
文档服务
检入检出
版本控制
访问控制
数据归档
内容管理
数据同步管理
配置管理
系统管理
报表展现
门户
接口应用层
每个业务系统使用独立的域进行存储(可以在同一个物理设备上,但是域要独立,数据域之间可以重叠数据组)
每个业务划分为结构化域和非结构化域
结构化域里面保存元数据信息,使用主子表按照时间切分,每个子表按照ID散列分布到域所对应的所有机器上
非结构化域里面保存对象数据,LOB不支持垂直分区,为了避免集群扩容对象数据重新均衡,在存储规划时可根据对象数据总的存储量及增长量采用按年或者按月的方式进行写入,LOB写入对应的集合空间和集合名称由接入平台维护
结构化域扩容可使用增加数据组再进行数据均衡切分到新扩容的机器上或者指定子表所属数据组在新扩容机器的数据组上
非结构化域扩容创建集合时所属数据组直接指定到新扩容机器的数据组上(这种方式适合前期规划时按月或年的方式,对应规划时存储在一个集合中的情形扩容后增加数据组需数据均衡)
结构化数据以主子表的方式进行存储
结构化数据在创建主子表时,以上线时间为基准,上线时间以前的数据存放在历史数据表中,数据较少的业务系统以年为单位创建子表,子表时间跨度为规划存储年限,超过规划存储年限的数据存储到其他数据存储子表中;数据较多的业务系统以月或季度为单位创建子表,子表时间跨度为规划存储年限,超过规划存储年限的数据存储到其他数据存储子表中。
非结构化数据以月为单位创建表进行存储
非结构化数据的存储,以上线时间为基准,上线时间以前的数据存放在历史数据表中,数据较少的业务系统以年为单位创建表,表时间跨度为规划存储年限,超过规划存储年限的数据存储到其他数据存储表中;数据较多的业务系统以月或季度为单位创建表,表时间跨度为规划存储年限,超过规划存储年限的数据存储到其他数据存储表中。
结构化数据域和非结构化数据域创建脚本:
db.createDomain('metaCSDomain',["group1","group2"],{AutoSplit:true});
db.createDomain('lobCSDomain',["group1","group2"],{AutoSplit:true});结构化集合空间和非结构化结合空间创建脚本:
db.createCS('metaCS', {"Domain":'metaCSDomain'});
db.createCS('lobCS', {"Domain":'lobCSDomain',"LobPageSize":logPageSize});结构化数据集合创建脚本:
db.metaCS.createCL('metaCL',{"ShardingKey":{"CREATETIME":1},"ShardingType":"range",ReplSize:-1,"Compressed":true,"CompressionType":"lzw","IsMainCL":true});
db.metaCS.createCL('metaCLMin',{"ShardingKey":{"_id":1},"ShardingType":"hash",ReplSize:-1,"Compressed":true,"CompressionType":"lzw","AutoSplit":true,"EnsureShardingIndex":false});
db.metaCS.createCL('metaCL2017',{"ShardingKey":{"_id":1},"ShardingType":"hash",ReplSize:-1,"Compressed":true,"CompressionType":"lzw","AutoSplit":true,"EnsureShardingIndex":false});
db.metaCS.createCL('metaCL2018',{"ShardingKey":{"_id":1},"ShardingType":"hash",ReplSize:-1,"Compressed":true,"CompressionType":"lzw","AutoSplit":true,"EnsureShardingIndex":false});
db.metaCS.createCL('metaCLMax',{"ShardingKey":{"_id":1},"ShardingType":"hash",ReplSize:-1,"Compressed":true,"CompressionType":"lzw","AutoSplit":true,"EnsureShardingIndex":false});
db.metaCS.getCL('metaCL').attachCL('metaCLMin',{"LowBound":{"CREATETIME":{$minKey:1}},"UpBound":{"CREATETIME":"20170101"}});db.metaCS.getCL('metaCL').attachCL('metaCL2017',{"LowBound":{"CREATETIME":"20170101"},"UpBound":{"CREATETIME":"20180101"}});
db.metaCS.getCL('metaCL').attachCL('metaCL2018',{"LowBound":{"CREATETIME":"20180101"},"UpBound":{"CREATETIME":"20190101"}});db.metaCS.getCL('metaCL').attachCL('metaCLMax',{"LowBound":{"CREATETIME":"20200101"},"UpBound":{"CREATETIME":{$maxKey:1}}});非结构化数据集合创建脚本:
db.lobCS.createCL('lobCL201701', {"ShardingKey":{"_id":1},"ShardingType":"hash",ReplSize:-1,"AutoSplit":true});
db.lobCS.createCL('lobCL201702', {"ShardingKey":{"_id":1},"ShardingType":"hash",ReplSize:-1,"AutoSplit":true});
db.lobCS.createCL('lobCL201703', {"ShardingKey":{"_id":1},"ShardingType":"hash",ReplSize:-1,"AutoSplit":true});
db.lobCS.createCL('lobCL201704', {"ShardingKey":{"_id":1},"ShardingType":"hash",ReplSize:-1,"AutoSplit":true});
...
db.lobCS.createCL('lobCL201912', {"ShardingKey":{"_id":1},"ShardingType":"hash",ReplSize:-1,"AutoSplit":true});数据域在逻辑上由一个或多个数据组组成,在物理上对应具体的数据节点,并且不同的域之间可以重叠数据组。因此,业务系统可以根据域包含数据组的灵活性将集群划分为不同的区域存储结构化数据和非结构化数据,充分利用集群的计算、存储资源。






