项目背景
JanusGraph 介绍
JanusGraph 架构介绍
我从 JanusGraph 的官网里找了一个整体的架构图,大家可以看到 JanusGraph 的模块还是挺丰富的,功能也是比较的全面。
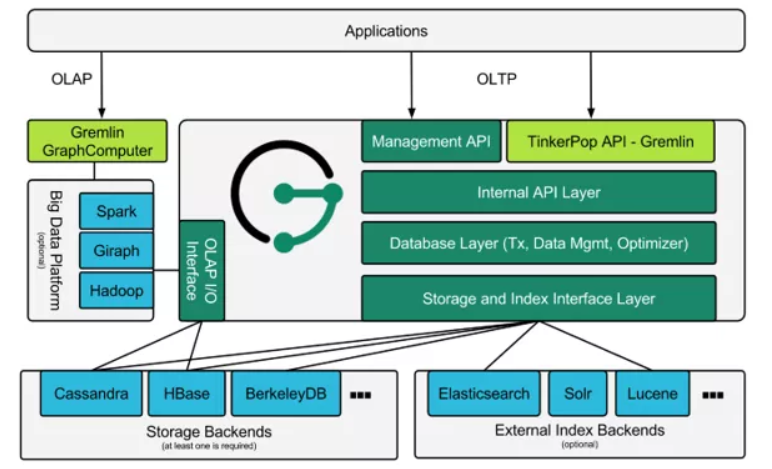
JanusGraph 在存储层中,分开了两个部分,一个专门存储数据(Storage Backend)的,另外一个是专门存储索引信息(Extemal Index Backend)的。存储层中这两个模块都设计得非常 open,逻辑比较清晰,简直就是希望大家踊跃尝试的意思。
JanusGraph 的操作语言,使用 Gremlin 语法进行操作。Gremlin 应该算是图计算里面的事实标准,很多的图计算语法,都是基于 Gremlin 进行二次开发的。
JanusGraph 还能够提供基于 Hadoop 啊,Spark 这些大数据的分析框架,为用户提供 OLAP 的服务。
但是最令我感到震惊的是,JanusGraph 竟然还支持事务功能,虽然是非常有限的事务,但确实提供了这个功能,但是需要存储层的产品来支撑事务功能。
JanusGraph 存储部分介绍
JanusGraph 的存储模块,它本身就是按照插件式的形式组成,大家可以从它的源代码的结构就能够看出来。
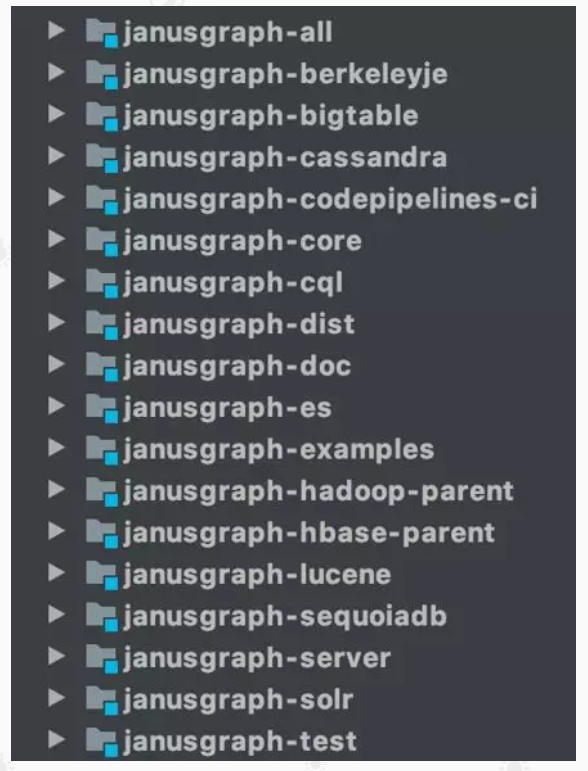
这种插件方式,在大数据平台里很多产品都是这种设计,Hadoop、Spark、Hive 等,另外,大家能够想到连著名的 MySQL 也是采用这种插件设计吗?这种插件的设计方法,优点就是容易集成,大家可以根据需要,随时扩展它的功能,这个是它社区繁荣的基础,也是它能够更快地衍生出更多场景的基础。
另外一方面,大家是否发现了,JanusGraph 支持的存储产品里,基本都是列存储的,譬如:HBase、Cassandra,都是列簇型的数据库,BerkeleyDB 则是一款K/V 型的数据。
以 HBase 数据库为例,因为它是列簇型的数据库,所以它把所有的内容都存放到了一张表里,通过不同的 Family 来保存,达到 I/O 分离的目的。而且 JanusGraph 向底下的数据库存储数据时,都是采用 Binary 格式进行保存,我看了一下代码,JanusGraph 除了需要保存一些常用的 Int、Boolean、String 类型外,还会保存一些 JanusGraph 自己特殊的类型数据。另外一个比较有意思的地方,可能是 HBase 或者是 Casssandra 数据库的API 特点,JanusGraph 将列的名字也是采用 Binary 格式存储,并且里面使用了 HBase 对 Key 排序的功能来读取数据。
从这些细节来看,JanusGraph 的存储设计都是基于列存储或者是 K/V 型的数据库进行,不知道是由于 Titan 的历史包袱,还是一些其他的考虑。
JanusGraph 存储模块代码梳理
我自己在阅读 JanusGraph 的存储代码时,主要就是参考 HBase 和 BerkeleyDB 的代码,逻辑比较清晰。
大家打开 StandardStoreManager.java 文件,就能够看到以下的 enum 描述。
BDB_JE("org.janusgraph.diskstorage.berkeleyje.BerkeleyJEStoreManager", "berkeleyje"),
CASSANDRA_THRIFT("org.janusgraph.diskstorage.cassandra.thrift.CassandraThriftStoreManager", "cassandrathrift"),
CASSANDRA_ASTYANAX("org.janusgraph.diskstorage.cassandra.astyanax.AstyanaxStoreManager", ImmutableList.of("cassandra", "astyanax")),
CASSANDRA_EMBEDDED("org.janusgraph.diskstorage.cassandra.embedded.CassandraEmbeddedStoreManager", "embeddedcassandra"),
CQL("org.janusgraph.diskstorage.cql.CQLStoreManager", "cql"),HBASE("org.janusgraph.diskstorage.hbase.HBaseStoreManager", "hbase"),
IN_MEMORY("org.janusgraph.diskstorage.keycolumnvalue.inmemory.InMemoryStoreManager", "inmemory");JanusGraph 就是通过不同的 storage.beckend 的名字,来判断应该初始化哪个 manager 类。
JanusGraph 关于 HBase 的代码,有好几个文件夹,但是真正核心的类,其实就是 HBaseStoreManager 和 HBaseKeyColumnValueStore 两个类。
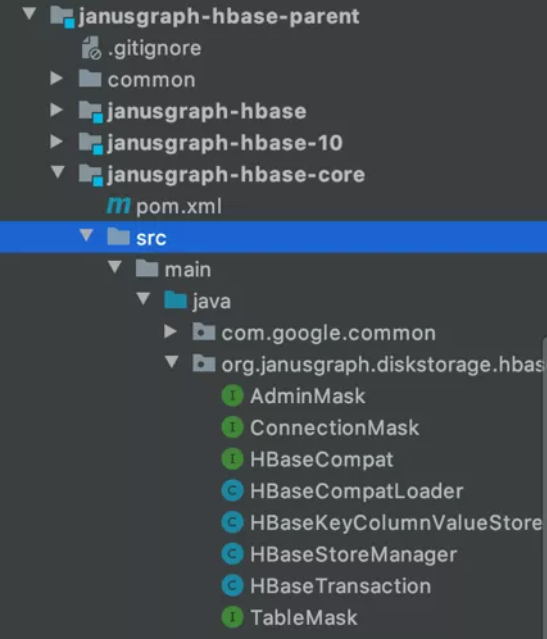
HBaseStoreManager 类是这个存储插件的入口类,它初始化了 JanusGraph 和 HBase 之间的连接,并且根据不同的 family 保存不同的连接。每一个 family 连接都会对应一个 HBaseKeyColumnValueStore 实例。
HBaseKeyColumnValueStore 类主要是对数据的存和取的操作,包括将 JanusGraph 的数据转换成 HBase 自身的格式,然后进行保存,或者是查询。
由于 HBase 不支持事务功能,所以 JanusGraph 在 HBase 上直接是关闭了事务功能。这个事情未来可以重新参考 BerkeleyDB 的模式来实现基于 SequoiaDB 的事务功能。
SequoiaDB for JanusGraph 技术设计
SequoiaDB 介绍
说老实话,当我一开始知道项目是使用一款国产的分布式数据库时,我是拒绝的,我觉得不能够甲方爸爸叫我用什么就用什么,如果它说它很厉害,然后写的软文都是速度快,开发简单,我就非常的不相信。但是当我体验了一下,Duang,这个感觉还真的挺好,确实速度快,开发简单。我还给我很多的朋友推荐,让他们都来试试。所以说啥,前面自己说啥呢?最后还不是真香!
言归正传,我从 SequoiaDB 的官网上找了一下它的架构图,大家可以看看。
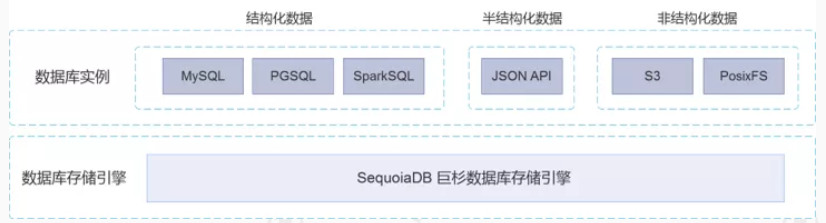
SequoiaDB 采用的是一种叫做“计算和存储分离”的架构,虽然听起来挺神奇的,但是却很好理解,上面的计算层就是一些协议的解析,它支持很多种协议,有 MySQL 的,有 JSON API 的,还有一些对象存储的协议;下面的存储层,看起来就像是一个封装好的盒子,里面可以支持数据的分布式存储。
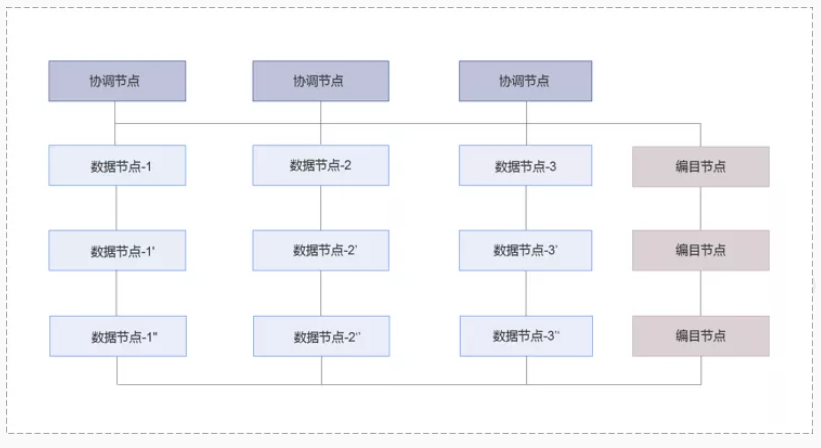
因为这种计算和存储分离的架构,使得应用的开发者,完全不需要关注底层的数据分布式实现,只要专心做好自己的应用逻辑就好了。
当然,如果你是一名 DBA,那样你还是要学习如何配置 SequoiaDB 底层的分布式存储的。
SequoiaDB 如何对接 JanusGraph
1、SequoiaDB for JanusGraph 的存储结构
前面也讲到了,由于 JanusGraph 对底层存储的设计和接口,都是根据列存储来设计的,所以在为 SequoiaDB for JanusGraph 设计时,就需要做出一些调整。
最开始时候,我是希望将一条记录的所有列都保存到 SequoiaDB 一个 BSON 里面,但是写到后面,由于 JanusGraph 会依赖 HBase 的列排序功能返回记录,所以这个在 SequoiaDB 里面无法对一条记录的不同列进行排序。所以在最后, JanusGraph 中的一条记录被我拆分成多个 BSON 记录,形式变成了以下的形式。记录以 RowKey 来维护其一条记录的完整性。
{RowKey:"", Key:"", Value:""}
{RowKey:"", Key:"", Value:""}
{RowKey:"", Key:"", Value:""}
{RowKey:"", Key:"", Value:""}在 BSON 中,RowKey、Key和Value 三个字段的数据类型都是 Binary 格式,这个也是 JanusGraph 自己所独有的解析方法。JanusGraph 保存于 SequoiaDB 中的记录如下面的例子:
{
"_id": {
"$oid": "5e410c444f025855e5552b4c"
},
"Key": {
"$binary": "///////+x38ABZ40DXrgsGMwYTgxZmZiMTc2ODYtY2hlbjE=",
"$type": "0"
},
"RowKey": {
"$binary": "AAAAAAAAAAM=",
"$type": "0"
},
"Value": {
"$binary": "",
"$type": "0"
}
}在前面我向大家介绍 JanusGraph 如何识别不同的存储产品的,所以要增加 SequoiaDB 数据库这个存储选项,首先需要 为StandardStoreManager 类增加 SequoiaDB 的选项,修改的部分如下:
BDB_JE("org.janusgraph.diskstorage.berkeleyje.BerkeleyJEStoreManager", "berkeleyje"),
CASSANDRA_THRIFT("org.janusgraph.diskstorage.cassandra.thrift.CassandraThriftStoreManager", "cassandrathrift"),
CASSANDRA_ASTYANAX("org.janusgraph.diskstorage.cassandra.astyanax.AstyanaxStoreManager", ImmutableList.of("cassandra", "astyanax")),
CASSANDRA_EMBEDDED("org.janusgraph.diskstorage.cassandra.embedded.CassandraEmbeddedStoreManager", "embeddedcassandra"),
CQL("org.janusgraph.diskstorage.cql.CQLStoreManager", "cql"),HBASE("org.janusgraph.diskstorage.hbase.HBaseStoreManager", "hbase"),
IN_MEMORY("org.janusgraph.diskstorage.keycolumnvalue.inmemory.InMemoryStoreManager", "inmemory"),
SEQUOIADB("org.janusgraph.diskstorage.sequoiadb.SequoiadbStoreManager", "sequoiadb");<titan.compatible-versions>1.0.0,1.1.0-SNAPSHOT</titan.compatible-versions> … <httpcomponents.version>4.4.1</httpcomponents.version> <hadoop2.version>2.7.7</hadoop2.version> <hbase1.version>1.4.10</hbase1.version> <hbase2.version>2.1.5</hbase2.version> <hbase.server.version>1.4.10</hbase.server.version> <sequoiadb.version>3.2.1</sequoiadb.version> ... <modules> … <module>janusgraph-doc</module> <module>janusgraph-solr</module> <module>janusgraph-examples</module> <module>janusgraph-sequoiadb</module> </modules>
对 JanusGraph 重新编译:
mvn -Dlicense.skip=true -DskipTests=true clean install
最后将编译好的 janusgraph-sequoiadb-0.4.0.jar 和 SequoiaDB 的 API 驱动 jar 包保存至 ${JANUSGRAPH_BINARY_HOME}/lib 目录中,就完成了 JanusGraph 扩展 SequoiaDB 存储的操作了。
3、JanusGraph 配置 SequoiaDB 作为存储
大家将 janusgraph-sequoiadb 的模块编译出来的 jar 包和 SequoiaDB 的 JSON API jar 包一起放到 JunasGraph 的 lib 目录里,同时更新 janusgraph-core 的 jar 包后,就完成了 JanusGraph 扩展 SequoiaDB 存储的操作了。为了让 JanusGraph 能够认识 SequoiaDB 的连接信息,大家还需要准备一个 config 文件。大家在 JunasGraph 的conf 目录里增加一个 janusgraph-sequoiadb.properties的文件,内容大致如下:
gremlin.graph=org.janusgraph.core.JanusGraph Factorystorage.backend=sequoiadbstorage.hostname=10.211.55.7 storage.port=11810#storage.username=sdbadmin# storage.password=sdbadminstorage.meta.visibility = true cache.db-cache = falsecache.db-cache-clean-wait = 20 cache.db-cache-time = 180000cache.db-cache-size = 0.5
storage.hostname,SequoiaDB coord 节点的 IP 地址,或者是 hostname
storage.port,SequoiaDB coord 节点的端口号
storage.username,如果 SequoiaDB 配置了鉴权,那样就需要配置鉴权的用户名
storage.password,如果 SequoiaDB 配置了鉴权,那样就需要配置鉴权的密码
当我们已经将 SequoiaDB 的配置信息写到了 config 文件里面了,那么 JanusGraph 对接 SequoiaDB 也是顺利成章的事情。大家可以直接打开 Gremlin 控制界面,然后就像平时使用 JanusGraph 那样操作即可。这里,我给大家准备了一下小 demo。
graph = JanusGraphFactory.open('conf/janusgraph-sequoiadb.properties');
graph.addVertex("name", "aaa", "num", 123)
g = graph.traversal()
g.V().values('name')So easy!
现在这个项目还是处于孵化阶段(事实是:一堆的坑,仅仅是 demo 跑通),未来还有很多工作要做,例如:
完善程序,不要那么多的 bug
应该要支持事务功能,毕竟人家 SequoiaDB 支持事务功能呢
对接 JanusGraph 的 Index 模块,也将这块内容让 SequoiaDB 接管
所以啊,未来路还很长,如果有谁看了这篇文章,被我成功感化了,欢迎来找我,也欢迎大家上Git点亮我的小心心,毕竟Star 数量多,会显得我很厉害的样子。谢谢大家。
项目地址:https://github.com/ak918808/sequoiadb_for_janusgraph
感谢社区同学的分享,也欢迎大家多多给我们投稿,未来我们也会多和大家分享巨杉数据库社区用户的使用心得体会敬请期待!






