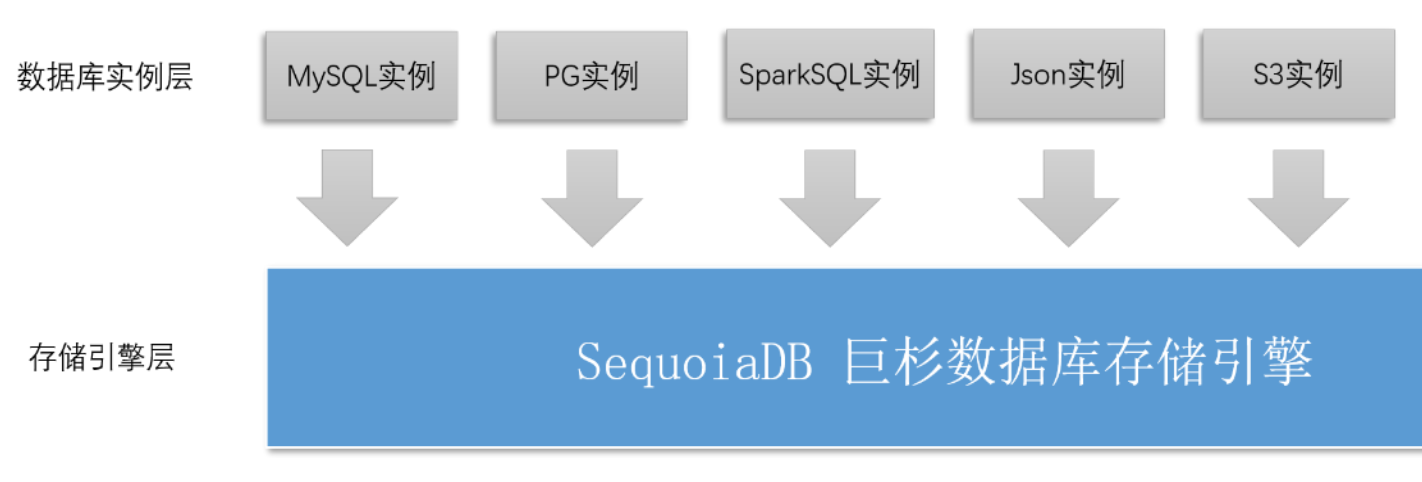
巨杉数据库 SequoiaDB 是一款开源的金融级分布式数据库,支持MySQL、PostgreSQL 与 SparkSQL 三种关系型数据库实例、 JSON 文档类数据库实例、以及 S3 对象存储非结构化数据实例。
SequoiaDB 适用于联机交易、数据中台和内容管理等应用场景。
那么如何从 MySQL 迁移到 SequoiaDB?之前有介绍过利用 mysqldump 以及mydumper/myloader 进行数据库迁移,本文介绍从 MySQL 到 SequoiaDB 快速迁移工具 etlAlchemy。
当应用系统需要切换数据库时,DBA 需要将旧数据库上的数据全部迁移至新数据库,数据迁移工作主要分为以下5个步骤:
1. 将旧数据库的创建数据表和索引导出
2. 将旧数据库的数据表的数据导出为数据文件
3. 将旧数据库的创建数据表语句、索引创建语句根据新数据库的语法规则进行调整
4. 在新数据库中创建对应的数据表和索引
5. 将数据文件导入新数据库中
以上的数据迁移工作在数据表较多的情况下采用人工处理的方式时工作量大且慢,期望使用脚本实现自动化。针对此数据迁移的场景,推荐一个工具 etlAlchemy。
etlAlchemy 是基于 Python 的 SQLAlchemy 库实现,能够通过简短的几行代码帮助用户快速迁移整个数据库。目前,该工具支持以下的数据库:
MySQL
PostgreSQL
MSSQL
Oracle
SQLite
虽然 etlAlchemy 目前只支持以上5种数据库,但是由于 etlAlchemy 是基于 SQLAlchemy 库实现,理论上 SQLAlchemy 支持的所有主流的数据库,etlAlchemy 均可以通过修改源码来增加支持,感兴趣的读者可以修改源码实现。
针对上述的数据库,etlArchemy 提供了以下的功能特性:
支持根据数据表名过滤数据表
支持迁移 Schema,数据,索引以及外键
支持过滤值为 null 的数据列
支持过滤记录为空的数据表以及所有数据列的值均为null的数据表
支持根据主键进行 Upsert,即目的端存在相同主键的记录则更新该记录的值,否则插入记录
支持修改 schema,包括:修改数据列名,修改数据列类型,删除数据列,数据表重命名,删除数据表
支持根据指定后缀名批量修改数据列名
支持忽略数据列名包含指定后缀名的数据列
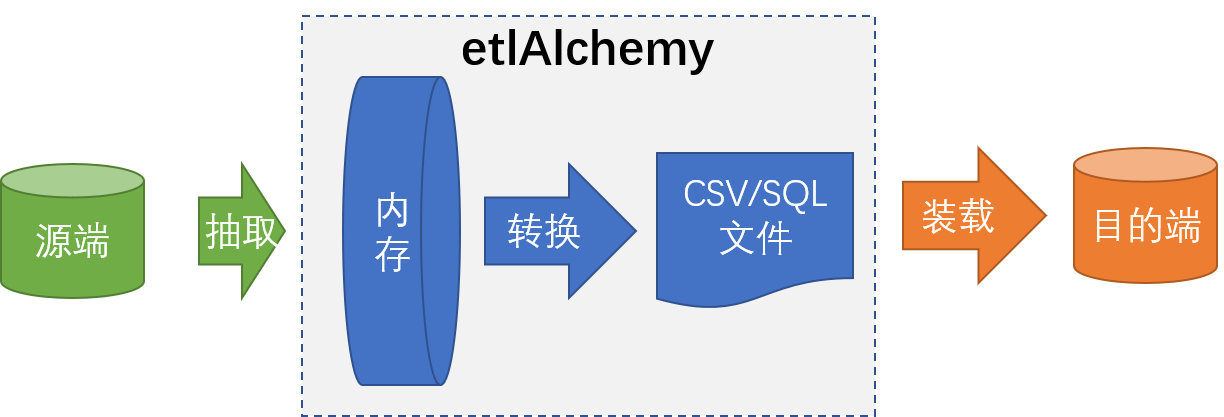
从上面支持的功能列表来看,etlAlchemy 支持的功能特性很强。etlAlchemy 工具的主要实现思路是 etlAlchemy 对源数据库的数据表逐个进行 ETL 过程处理,而 ETL 过程与数据迁移工作过程比较类似,具体处理过程如下:
1. 获取数据表的索引信息,外键信息
2. 将数据表的所有数据行抽取并映射至内存中
3. 对数据行进行数据转换处理,根据目的数据库类型存储为 SQL 文件或 CSV 文件,其中 MSSQL、Oracle 库是存储为 sql 文件,其余数据库类型则是存储为 CSV 文件
4. 在目的数据库中创建数据表
5. 调用目的端的数据导入工具将 CSV 文件导入目的端或执行 SQL 文件的 sql 语句插入数据至目的端数据库
6. 创建数据表的索引、外键
7. 清理临时生成的数据文件
8. 创建索引和外键
etlAlchemy 的安装部署主要分为以下3个步骤:
1. 安装 mysql-devel , python-devel 库,示例环境是 centos7.2。
yum intall mysql-devel python-devel
2. 使用 pip 安装 etlAlchemy。
pip install etlalchemy
3. etlAlchemy 依赖DB-API 来访问源端和目标端数据库,因此迁移不同的数据库时需要安装不同的 DB-API,在此以 MySQL 为例。
pip install mysql-python
接下来安装部署 MySQL 实例。假设已有 MySQL 和 SequoiaDB 集群环境,计划在 server2 机器上安装部署 MySQL 实例,环境信息如下表:

SequoiaDB 数据库集群部署教程可以参考官方教程。
安装部署 MySQL 实例主要分为以下6个步骤:
1. 到官网下载 SequoiaDB 安装包
Note:
3.0版本及以上提供 MySQL 实例
MySQL 实例的版本需要跟 SequoiaDB 版本保持一致
2. 解压安装包
tar -zxvf sequoiadb-3.2.3-linux_x86_64.tar.gz
3. 切换至 root 用户,执行安装 MySQL 实例
su root sh setup.sh --mysql
4. 添加 MySQL 实例
/opt/sequoiasql/mysql/bin/sdb_sql_ctl addinst mysqlinstance1 -D /opt/sequoiasql/
Note:
-D 指定 MySQL 实例的元数据信息存储目录
addinst 后面跟着的是实例名,当同一个机器部署多个 MySQL 实例时,每个实例名在本机上必须唯一
5. MySQL 实例安装部署完毕,使用 MySQL 客户端或者其他 MySQL 图形化操作界面连接 MySQL 实例进行数据操作
mysql -uroot -h127.0.0.1
6. 创建数据迁移的 MySQL 实例用户test
mysql mysql> CREATE USER test IDENTIFIED BY 'test'; Query OK, 0 rows affected (0.16 sec) mysql> GRANT ALL PRIVILEGES ON *.* TO 'test'@'%' ; Query OK, 0 rows affected (0.01 sec) mysql> FLUSH PRIVILEGES; Query OK, 0 rows affected (0.08 sec)
假设已经根据上述的环境信息表准备好对应的环境,现有需求是将 MySQL 数据库上的 test 库迁移至 SequoiaDB 数据库中。
mysql mysql> use test; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> select * from test; +------+------+ | id | name | +------+------+ | 1 | test1 | | 2 | test2 | | 3 | test3 | | 4 | test4 | | 5 | test5 | | 6 | test6 | | 7 | test7 | +------+------+ 7 rows in set (0.00 sec)
2. 新建一个 python 脚本文件,输入以下4行代码并保存文件 migrateDb.py
#!/usr/bin/python
from etlalchemy import ETLAlchemySource, ETLAlchemyTarget
# 数据库的用户名、密码、主机、字符编码需要根据实际情况编写
source = ETLAlchemySource("mysql://test:test@server1/test?charset=utf8")
target = ETLAlchemy
Target("mysql://test:test@server2/test", drop_database=True)
target.addSource(source)target.migrate()3. 执行 python 脚本,即可自动将 MySQL 的 test 库迁移至 SequoiaDB 中
python migrateDb.py
4. 在 MySQL 实例上检查数据是否已经迁移成功
mysql mysql> use test; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> select * from test; +------+------+ | id | name | +------+------+ | 1 | test1 | | 2 | test2 | | 3 | test3 | | 4 | test4 | | 5 | test5 | | 6 | test6 | | 7 | test7 | +------+------+ 7 rows in set (0.00 sec)
从上面的步骤,可以得知 etlAlchemy 工具将 MySQL 的数据迁移至 SequoiaDB 中很简单方便快捷。那么该工具的数据迁移的性能如何呢?
根据官网性能测试数据,整个 MySQL 库有 400w 数据,大小为 150MB,从 MySQL 迁移至另一个 MySQL,耗时为4min38s。
虽然 etlAlchemy 工具能够通过简单的几行代码完成整个数据库的数据迁移工作,但是在使用该工具时,需要注意以下事项:
对于时间类型的数据,时间格式均为所有数据库开箱即用的默认值
字符串类型的值不能包含字符"|"或字符串"*",否则可能会引起数据导入失败
不支持迁移 MSSQL 的外键
工具不兼容在 Windows 上运行
迁移 MSSQL 和 Oracle 的速度比较缓慢,该问题有兴趣的读者可以对代码进行优化,提高数据迁移性能
确保机器的可用内存大于数据表的大小,避免由于内存不足而导致迁移程序被系统kill掉
确保迁移程序所在的磁盘空间足够存储数据表的 dump 出来的数据文件的大小
更多注意事项说明参见已知限制
SequoiaDB 巨杉数据库100%兼容 MySQL,利用 etlAlchemy 工具能够通过简单的几行代码,帮助用户快速将 MySQL 整个库迁移至 SequoiaDB 中。
1






